외부 파일 읽어오기, 웹(web)에서 가져오기
외부 파일 읽어오기
데이터 분석, 머신러닝 등에 사용할 라이브러리 도구들을 사용하는 첫 관문은 데이터에 접근하는 것이다. 다양한 형식의 데이터를 읽고 쓸 수 있는 많은 라이브러리가 있지만 여기서는 판다스에 초점을 맞춰 설명한다.
일반적으로 입출력은 몇 가지 작은 범주로 나뉘는데, 텍스트 파일을 이용하는 방법, 데이터베이스를 이용하는 방법, 웹 API를 이용해서 네트워크를 통해 불러오는 방법이 있다.
텍스트 파일에서 데이터를 읽고 쓰는 법
판다스는 다양한 형태의 외부 파일을 읽어와서 데이터프레임으로 변환하는 함수를 제공한다. 어떤 파일이든 판다스 객체인 데이터프레임으로 변환되고 나면 판다스의 모든 함수와 기능을 자유롭게 사용할 수 있다. 반대로 데이터프레임을 다양한 유형의 파일로 저장할 수도 있다. 다음은 판다스 공식 사이트에서 제공하는 입출력 도구에 관한 자료를 요약한 것이다.
| File Format | Reader | Writer |
|---|---|---|
| CSV | read_csv | to_csv |
| JSON | read_json | to_json |
| HTML | read_html | to_html |
| Local clipboard | read_clipboard | to_clipboard |
| MS Excel | read_excel | to_excel |
| HDF5 Format | read_hdf | to_hdf |
| SQL | read_sql | to_sql |
판다스 데이터 입출력 도구(출처: http://pandas.pydata.org)
위 함수들은 텍스트 데이터를 데이터프레임으로 읽어오기 위한 함수인데, 아래와 같은 몇 가지 옵션을 취한다.
-
인덱스 반환하는 데이터프레임에서 하나 이상의 칼럼을 인덱스로 지정할 수 있다. 파일이나 사용자로부터 칼럼 이름을 받거나 아무것도 받지 않을 수 있다.
-
자료형 추론과 데이터 변환 사용자 정의 값 변환과 비어 있는 값을 위한 사용자 리스트를 포함한다.
-
날짜 분석 여러 칼럼에 걸쳐 있는 날짜와 시간 정보를 하나의 칼럼에 조합해서 결과에 반영한다.
-
반복 여러 개의 파일에 걸쳐 있는 자료를 반복적으로 읽어올 수 있다.
-
정제되지 않은 데이터 처리 로우나 꼬리말, 주석 건너뛰기 또는 천 단위마다 쉼표로 구분된 숫자 같은 사소한 것들의 처리를 해준다.
데이터 분석을 위해 다양한 곳에서 자료를 수집하다 보면, 여러 가지 파일 형식을 마주치게 된다. 파일 확장자를 예로 들면, .csv, .json, .xlsx 등이 있다.
데이터 값을 쉼표(,)로 구분하고 있다는 의미로 CSV(comma-separated values)라고 부르는 텍스트 파일이다. 쉼표(,)로 열을 구분하고 줄바꿈으로 행을 구분한다. 판다스 read_csv() 함수에 확장자(.csv)를 포함하여 파일 경로(파일명)를 입력하면 CSV 파일을 읽어와서 데이터프레임으로 변환한다.
read_csv() 함수의 header(기본 값: 0) 옵션은 데이터프레임의 열 이름으로 사용할 행을 지정하고, index_col(기본 값: False) 옵션은 데이터프레임의 행 인덱스가 되는 열을 지정한다.
또한 read_csv() 같은 함수들은 데이터 형식에 자료형이 포함되어 있지 않은 관계로 타입 추론을 수행한다. HDF5나 Feather, msgpack의 경우에는 데이터 형식에 자료형이 포함되어 있다.
다음은 예제로 사용할 CSV 파일의 내용이다. 데이터가 쉼표(,)와 행으로 구분된 것을 확인할 수 있다.
a,b,c,d,message 1,2,3,4,hello 5,6,7,8,world 9,10,11,12,foo
이 파일은 쉼표로 구분되어 있으므로 read_csv()를 사용해서 데이터프레임으로 읽어올 수 있다. 파일명을 포함하여 정확한 파일 경로를 read_csv() 함수의 인자로 전달한다.
df = pd.read_csv('examples/ex1.csv')
print(df)
a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo
read_table()에 구분자를 쉼표로 지정해서 읽어올 수도 있다. 참고로 read_table()은 기본 데이터 구분자를 탭(\t)으로 한다.
df = pd.read_table('examples/ex1.csv', sep=',')
print(df)
a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo
모든 파일에 칼럼 이름이 있는 건 아니다. 다음 파일처럼 칼럼 이름이 없을 수도 있다.
1,2,3,4,hello 5,6,7,8,world 9,10,11,12,foo
이 파일을 읽어오는 몇 가지 옵션이 있는데, 판다스가 자동으로 칼럼 이름을 생성하도록 하거나 우리가 직접 칼럼 이름을 지정한다.
df = pd.read_csv('examples/ex2.csv', header=None)
print(df) # 자동으로 칼럼명에 정수가 들어갔다.
0 1 2 3 4 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo
df = pd.read_csv('examples/ex2.csv', names=['a', 'b', 'c', 'd', 'message'])
print(df) # 칼럼에 지정한 리스트의 원소들이 들어갔다.
a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo
message 칼럼을 인덱스로 하는 데이터프레임을 반환하려면 index_col 인자에 4번째 칼럼 또는 ‘message’ 이름을 가진 칼럼을 지정해서 인덱스로 만들 수 있다.
names = ['a', 'b', 'c', 'd', 'message']
df = pd.read_csv('examples/ex2.csv', names=names, index_col='message') # index_col=4와 동일
print(df)
print('\n')
print(df.index) # df의 index를 표시. index의 이름이 'message'이다.
a b c d
message
hello 1 2 3 4
world 5 6 7 8
foo 9 10 11 12
Index(['hello', 'world', 'foo'], dtype='object', name='message')
멀티 인덱스를 지정하고 싶다면 칼럼 번호나 이름의 리스트를 넘기면 된다.
key1,key2,value1,value2 one,a,1,2 one,b,3,4 one,c,5,6 one,d,7,8 two,a,9,10 two,b,11,12 two,c,13,14 two,d,15,16
parsed = pd.read_csv('examples/csv_mindex.csv',
index_col=['key1', 'key2'])
print(parsed)
value1 value2
key1 key2
one a 1 2
b 3 4
c 5 6
d 7 8
two a 9 10
b 11 12
c 13 14
d 15 16
멀티 인덱스에 대해서는 다음에 알아보기로 하고, 지금은 여러 개의 인덱스를 사용한다 정도만 알아두자.
가끔 고정된 구분자 없이 공백이나 다른 패턴으로 필드를 구분해놓은 경우가 있다. 다음과 같은 파일이 있다고 하자.
list(open('examples/ex3.txt'))
[' A B C\n', 'aaa -0.264438 -1.026059 -0.619500\n', 'bbb 0.927272 0.302904 -0.032399\n', 'ccc -0.264273 -0.386314 -0.217601\n', 'ddd -0.871858 -0.348382 1.100491\n']
직접 파일을 고쳐도 되지만, 이 파일은 필드가 여러 개의 공백 문자로 구분되어 있으므로 이를 표현할 수 있는 정규 표현식 \s+를 사용해서 처리할 수도 있다.
result = pd.read_table('examples/ex3.txt', sep='\s+')
print(result)
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491
이 경우 첫 번째 로우는 다른 로우보다 칼럼이 하나 적기 때문에 read_table()은 첫 번째 칼럼이 데이터프레임의 인덱스가 되어야 한다고 추론한다.
파서 함수는 파일 형식에서 발생할 수 있는 매우 다양한 예외를 처리할 수 있도록 많은 추가 인자를 가지고 있는데, 예를 들면 skiprows를 이용해서 첫 번째, 세 번째, 네 번째 로우를 건너뛸 수 있다.
# hey! a,b,c,d,message # just wanted to make things more difficult for you # who reads CSV files with computers, anyway? 1,2,3,4,hello 5,6,7,8,world 9,10,11,12,foo
df = pd.read_csv('examples/ex4.csv', skiprows=[0, 2, 3])
print(df) # 주석 처리된 문장들은 건너뛰었다.
a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo
누락된 값을 잘 처리하는 것은 파일을 읽는 과정에서 자주 발생하는 일이고 중요한 문제다. 보통 텍스트 파일에서 누락된 값은 표기되지 않거나(비어 있는 문자열) 구분하기 쉬운 특수한 문자로 표기된다. 기본적으로 판다스는 NA나 NULL처럼 흔히 통용되는 문자를 비어 있는 값으로 사용한다.
something,a,b,c,d,message one,1,2,3,4,NA two,5,6,,8,world three,9,10,11,12,foo
result = pd.read_csv('examples/ex5.csv')
print(result)
print('\n')
print(pd.isnull(result)) # NaN 값은 True, 값이 존재하면 False
something a b c d message 0 one 1 2 3.0 4 NaN 1 two 5 6 NaN 8 world 2 three 9 10 11.0 12 foo something a b c d message 0 False False False False False True 1 False False False True False False 2 False False False False False False
na_values 옵션은 리스트나 문자열 집합을 받아서 누락된 값을 처리한다.
result = pd.read_csv('examples/ex5.csv', na_values=['NULL'])
print(result)
something a b c d message 0 one 1 2 3.0 4 NaN 1 two 5 6 NaN 8 world 2 three 9 10 11.0 12 foo
칼럼마다 다른 NA 문자를 사전값으로 넘겨서 처리할 수도 있다.
sentinels = {'message': ['foo', 'NA'], 'something': ['two']}
result = pd.read_csv('examples/ex5.csv', na_values=sentinels)
print(result)
something a b c d message 0 one 1 2 3.0 4 NaN 1 NaN 5 6 NaN 8 world 2 three 9 10 11.0 12 NaN
다음은 read_csv()와 read_tabel() 함수의 자주 사용하는 옵션을 설명한 것이다.
| 옵션 | 설명 |
|---|---|
| path | 파일의 위치(파일명 포함), URL |
| sep(또는 delimiter) | 필드를 구분하기 위해 사용할 연속된 문자나 정규 표현식 |
| header | 열 이름으로 사용될 행의 번호(기본값은 0) header가 없고 첫 행부터 데이터가 있는 경우 None으로 지정 가능 |
| index_col | 행 인덱스로 사용할 열의 번호 또는 열 이름 |
| names | 열 이름으로 사용할 문자열의 리스트. header=None과 함께 사용한다. |
| skiprows | 처음 몇 줄을 skip할 것인지 설정(숫자 입력) skip하려는 행의 번호를 담은 리스트로 설정 가능(예:[1, 3, 5]) |
| parse_dates | 날짜 텍스트를 datetime64로 변환할 것인지 설정(기본값은 False), True일 경우 모든 컬럼에 적용된다. 칼럼의 번호나 이름을 포함한 리스트를 넘겨서 변환할 칼럼을 지정할 수 있는데, [1, 2, 3]을 넘기면 각각의 칼럼을 datetime으로 변환하며, [[1, 3]]을 넘기면 1, 3번 칼럼을 조합해서 하나의 datetime으로 변환한다. |
| skip_footer | 마지막 몇 줄을 skip할 것인지 설정(숫자 입력) |
| encoding | 텍스트 인코딩 종류를 지정(예:'utf-8') |
| na_values | NaN 값으로 처리할 값들의 목록 |
| comment | 주석으로 분류되어 파싱하지 않을 문자 혹은 문자열 |
| keep_date_col | 여러 칼럼을 datetime으로 변환했을 경우 원래 칼럼을 남겨둘지 여부. 기본값은 True |
| converters | 변환 시 칼럼에 적용할 함수를 지정한다. 예를 들어 {'foo': f}는 'foo' 칼럼에 f 함수를 적용시킨다. 전달하는 사전의 키값은 칼럼 이름이나 번호가 될 수 있다. |
| dayfirst | 모호한 날짜 형식일 경우 국제 형식으로 간주한다(7/6/2012는 2012년 6월 7일로 간주한다). 기본값은 False |
| date_parser | 날짜 변환 시 사용할 함수 |
| nrows | 파일의 첫 일부만 읽어올 때 처음 몇 줄을 읽을 것인지 지정 |
| iterator | 파일을 조금씩 읽을 때 사용하도록 TextParser 객체를 반환하도록 한다. 기본값은 False |
| chunksize | TextParser 객체에서 사용할 한 번에 읽을 파일의 크기 |
| verbose | 파싱 결과에 대한 정보를 출력한다. 숫자가 아닌 값이 들어 있는 칼럼에 누락된 값이 있다면 줄 번호를 출력해준다. 기본값은 False |
| squeeze | 만일 칼럼이 하나뿐이라면 시리즈 객체를 반환한다. 기본값은 False |
| thousands | 숫자를 천 단위로 끊을 때 사용할 ','나 '.' 같은 구분자 |
pd.read_csv('./examples/ex1.csv')
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
텍스트 파일 조금씩 읽어오기
매우 큰 파일을 처리할 때 인자를 제대로 주었는지 알아보기 위해 파일의 일부분만 읽어보거나 여러 파일 중에서 몇 개의 파일만 읽어서 확인해보고 싶을 것이다.
result = pd.read_csv('examples/ex6.csv')
print(result)
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
... ... ... ... ... ..
9995 2.311896 -0.417070 -1.409599 -0.515821 L
9996 -0.479893 -0.650419 0.745152 -0.646038 E
9997 0.523331 0.787112 0.486066 1.093156 K
9998 -0.362559 0.598894 -1.843201 0.887292 G
9999 -0.096376 -1.012999 -0.657431 -0.573315 0
[10000 rows x 5 columns]
파일 전체를 읽는 대신 처음 몇 줄만 읽어보고 싶다면 nrows 옵션을 주면 된다.
result = pd.read_csv('examples/ex6.csv', nrows=5)
print(result)
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
파일을 여러 조각으로 나누어서 읽고 싶다면 chunksize 옵션으로 로우의 개수를 주면 된다.
chunker = pd.read_csv('examples/ex6.csv', chunksize=1000)
print(chunker)
<pandas.io.parsers.readers.TextFileReader object at 0x000001B24C827E20>
read_csv()에서 반환된 TextParser 객체를 이용해서 chnksize에 따라 분리된 파일들을 순회할 수 있다. 예를 들어 ex6.csv 파일을 순회하면서 ‘key’ 칼럼에 있는 값을 세어보려면 다음처럼 하면 된다.
chunker = pd.read_csv('examples/ex6.csv', chunksize=1000)
tot = pd.Series([], dtype=float) # 빈 시리즈 객체 생성
# 총 데이터가 10,000개이므로 chunksize인 1,000개씩 10번 반복
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value=0) # 'key' 칼럼의 값의 개수를 반환
tot = tot.sort_values(ascending=False)
print(tot[:10])
E 368.0 X 364.0 L 346.0 O 343.0 Q 340.0 M 338.0 J 337.0 F 335.0 K 334.0 H 330.0 dtype: float64
TextParser는 임의 크기의 조각을 읽을 수 있는 get_chunk 메서드도 포함하고 있다.
구분자 형식 다루기
read_table() 함수를 이용해서 디스크에 표 형태로 저장된 대부분의 파일 형식을 불러올 수 있다. 하지만, 수동으로 처리해야 하는 경우도 있다. read_table() 함수가 데이터를 불러오는데 실패하게끔 만드는 잘못된 라인이 포함되어 있는 데이터를 전달받는 경우도 종종 있다. 우선은 작은 CSV 파일을 불러오는 과정으로 기본적인 도구 사용법을 익혀보자.
"a","b","c" "1","2","3" "1","2","3"
구분자가 한 글자인 파일은 파이썬 내장 csv 모듈을 이용해서 처리할 수 있는데, 열려진 파일 객체를 csv.reader 함수에 넘기기만 하면 된다.
import csv
f = open('examples/ex7.csv')
reader = csv.reader(f)
# 파일을 읽듯이 reader를 순회하면 둘러싸고 있던 큰따옴표가 제거된 리스트를 얻을 수 있다.
for line in reader:
print(line)
['a', 'b', 'c'] ['1', '2', '3'] ['1', '2', '3']
이제 원하는 형태로 데이터를 넣을 것이다.
# 먼저 파일을 읽어 줄 단위 리스트로 저장
with open('examples/ex7.csv') as f:
lines = list(csv.reader(f))
# 헤더와 데이터를 구분
header, values = lines[0], lines[1:]
# 로우를 칼럼으로 전치해주는 zip(*values)와 사전 표기법을 이용해서 데이터 칼럼 사전을 만든다.
data_dict = {h: v for h, v in zip(header, zip(*values))}
print(data_dict)
{'a': ('1', '1'), 'b': ('2', '2'), 'c': ('3', '3')}
참고로 위에서 zip(*values)의 결과는 다음과 같다.
# zip(*values)는 zip 객체이므로 list()로 감싸서 내용을 볼 수 있다.
print(list(zip(*values)))
[('1', '1'), ('2', '2'), ('3', '3')]
CSV 파일은 다양한 형태로 존재할 수 있다. 다양한 구분자, 문자열을 둘러싸는 방법, 개행 문자 같은 것들은 csv.Dialect를 상속받아 새로운 클래스를 정의해서 해결할 수 있다.
class my_dialect(csv.Dialect):
lineterminator = '\n' # 개행 문자
delimiter = ';' # 구분자 ;
quotechar = '"' # 문자열을 둘러싸는 방법 ""
quoting = csv.QUOTE_MINIMAL
with open('examples/ex7.csv') as f:
line = list(csv.reader(f, dialect=my_dialect))
서브클래스를 정의하지 않고 csv.reader()에 키워드 인자로 각각의 CSV 파일의 특징을 지정해서 전달해도 된다.
with open('examples/ex7.csv') as f:
line = list(csv.reader(f, delimiter='|'))
사용 가능한 옵션(csv.Dialect의 속성)과 어떤 역할을 하는지에 대해서는 다음을 참고한다.
| 인자 | 설명 |
|---|---|
| delimiter | 필드를 구분하기 위한 한 문자로 된 구분자. 기본값은 ',' |
| lineterminator | 파일을 저장할 때 사용할 개행 문자. 기본값은 '\r\n'. 파일을 읽을 때는 이 값을 무시하며, 자동으로 플랫폼별 개행 문자를 인식한다. |
| quotechar | 각 필드에서 값을 둘러싸고 있는 문자. 기본값은 ' " ' |
| quoting | 값을 읽거나 쓸 때 둘러쌀 문자 컨벤션. csv.QUOTE_ALL(모든 필드에 적용), csv.QUOTE_MINIMAL(구분자 같은 특별한 문자가 포함된 필드만 적용). csv.QUOTE_NONE(값을 둘러싸지 않음) 옵션이 있다. 자세한 내용은 파이썬 문서를 참고하자. 기본값은 QUOTE_MINIMAL |
| skipinitialspace | 구분자 뒤에 있는 공백 문자를 무시할지 여부. 기본값은 False |
| doublequote | 값을 둘러싸는 문자가 필드 내에 존재할 경우 처리 여부. True일 경우 그 문자까지 모두 둘러싼다. 자세한 내용은 온라인 문서를 참고하자. |
| escapechar | quoting이 csv.QUOTE_NONE일 때 값에 구분자와 같은 문자가 있을 경우 구별할 수 있도록 해주는 이스케이프 문자('\' 같은). 기본값은 None |
더 복잡하거나 구분자가 한 글자를 초과하는 고정 길이를 가진다면 csv 모듈을 사용할 수 없다. 이 경우 줄을 나누고 문자열의 split() 메서드나 정규 포현식 메서드인 re.split() 등을 이용해서 가공하는 작업이 필요하다.
CSV 처럼 구분자로 구분된 파일을 기록하려면 csv.writer()를 이용하면 된다. csv.writer()는 이미 열린, 쓰기가 가능한 파일 객체를 받아서 csv.reader()와 동일한 옵션으로 파일을 기록한다.
with open('mydata.csv', 'w') as f:
writer = csv.writer(f, dialect=my_dialect)
writer.writerow(('one', 'two', 'three'))
writer.writerow(('1', '2', '3'))
writer.writerow(('4', '5', '6'))
writer.writerow(('7', '8', '9'))
현재 작업 파일 경로에 ‘mydata.csv’ 파일이 생성되었다.

그리고 다음은 생성된 파일의 내용이다.

JSON 데이터
JSONJavaScript Object Notation은 웹브라우저와 다른 애플리케이션이 HTTP 요쳥으로 데이터를 보낼 때 널리 사용하는 표준 파일 형식 중 하나로, 데이터 공유를 목적으로 개발된 특수한 파일 형식이다. JSON은 CSV 같은 표 형식의 텍스트보다 좀 더 유연한 데이터 형식이다. 파이썬 딕셔너리와 비슷하게 ‘key: value’ 구조를 갖는데 구조가 중첩되는 방식에 따라 옵션을 다르게 적용한다. 아래는 JSON 데이터의 예다.
obj = """
{"name": "Wes",
"places_lived": ["United States", "Spain", "Germany"],
"pet": null,
"siblings": [{"name": "Scott", "age": 30, "pets": ["Zeus", "Zuko"]},
{"name": "Katie", "age": 38,
"pets": ["Sixes", "Stache", "Cisco"]}]
}
"""
JSON은 널값 null과 다른 몇 가지 미묘한 차이(리스트의 마지막에 쉼표가 있으면 안 되는 등)를 제외하면 파이썬 코드와 거의 유사하다. 기본 자료형은 객체(사전), 배열(리스트), 문자열, 숫자, 불리언, 그리고 널이다. 객체의 키는 반드시 문자열이어야 한다. JSON 데이터를 읽고 쓸 수 있는 파이썬 라이브러리가 몇 가지 있는데 여기서는 파이썬 표준 라이브러리인 json을 사용하겠다. JSON 문자열을 파이썬 형태로 변환하기 위해서는 json.loads를 사용한다.
import json
result = json.loads(obj)
print(result)
print('\n')
print(type(result))
{'name': 'Wes', 'places_lived': ['United States', 'Spain', 'Germany'], 'pet': None, 'siblings': [{'name': 'Scott', 'age': 30, 'pets': ['Zeus', 'Zuko']}, {'name': 'Katie', 'age': 38, 'pets': ['Sixes', 'Stache', 'Cisco']}]}
<class 'dict'>
json.dumbs는 파이썬 객체를 JSON 형태로 변환한다.
asjson = json.dumps(result)
print(asjson)
print('\n')
print(type(asjson))
{"name": "Wes", "places_lived": ["United States", "Spain", "Germany"], "pet": null, "siblings": [{"name": "Scott", "age": 30, "pets": ["Zeus", "Zuko"]}, {"name": "Katie", "age": 38, "pets": ["Sixes", "Stache", "Cisco"]}]}
<class 'str'>
JSON 객체나 객체의 리스트를 데이터프레임이나 다른 자료구조로 어떻게 변환해서 분석할 것인지는 사용자의 몫이다. 편리하게도 JSON 객체의 리스트를 사전을 담고 있는 리스트로 변환하여 데이터프레임 생성자로 넘기고 데이터 필드를 선택할 수 있다.
siblings = pd.DataFrame(result['siblings'], columns=['name', 'age'])
print(siblings)
name age
0 Scott 30
1 Katie 38
read_json()은 자동으로 JSON 데이터셋을 시리즈나 데이터프레임으로 변환할 수 있다.
[{"a": 1, "b": 2, "c": 3},
{"a": 4, "b": 5, "c": 6},
{"a": 7, "b": 8, "c": 9}]
별다른 옵션이 주어지지 않았을 경우 read_json()은 JSON 배열에 담긴 각 객체를 테이블의 로우로 간주한다.
data = pd.read_json('examples/example.json')
print(data)
a b c 0 1 2 3 1 4 5 6 2 7 8 9
웹(web)에서 가져오기
XML과 HTML: 웹 스크래핑
파이썬에는 lxml, Beautiful Soup(뷰티플 수프), 그리고 html5lib 같은 HTML과 XML 형식의 데이터를 읽고 쓸 수 있는 라이브러리가 무척 많다. 그중에서도 lxml은 가장 빠르게 동작하고 깨진 HTML과 XML 파일도 잘 처리해준다.
판다스에는 read_html()이라는 내장 함수가 있다. 이는 lxml이나 Beautiful Soup 같은 라이브러리를 사용해서 자동으로 HTML 파일을 파싱하여 데이터프레임으로 변환해준다. 사용법을 알아보기 위해 미연방예금보험공사FDIC에서 부도은행을 보여주는 HTML을 다운로드하자.1
read_html() 함수에는 다양한 옵션이 있는데 기본적으로 <table> 태그 안에 있는 모든 표 형식의 데이터 파싱을 시도한다. 표 데이터들은 각각 별도의 데이터프레임으로 변환되기 때문에 여러 개의 데이터프레임(표)을 원소로 갖는 리스트가 반환된다.
tables = pd.read_html('examples/fdic_failed_bank_list.html')
print('표 데이터의 개수:', len(tables))
print('\n')
failures = tables[0]
print(failures.head()) # failures에는 칼럼이 많아서 판다스에서는 \ 문자로 구분해서 보여준다.
표 데이터의 개수: 1
Bank Name City ST CERT \
0 Allied Bank Mulberry AR 91
1 The Woodbury Banking Company Woodbury GA 11297
2 First CornerStone Bank King of Prussia PA 35312
3 Trust Company Bank Memphis TN 9956
4 North Milwaukee State Bank Milwaukee WI 20364
Acquiring Institution Closing Date Updated Date
0 Today's Bank September 23, 2016 November 17, 2016
1 United Bank August 19, 2016 November 17, 2016
2 First-Citizens Bank & Trust Company May 6, 2016 September 6, 2016
3 The Bank of Fayette County April 29, 2016 September 6, 2016
4 First-Citizens Bank & Trust Company March 11, 2016 June 16, 2016
lxml.objectify를 이용해서 XML 파싱하기
XMLeXtensible Markup Language은 계층적 구조와 메타데이터를 포함하는 중첩된 데이터 구조를 지원하는 또 다른 유명한 데이터 형식이다.
앞에서는 HTML에서 데이터를 파싱하기 위해 내부적으로 lxml 또는 Beautiful Soup을 사용하는 read_html() 함수를 살펴봤다. XML과 HTML은 구조적으로 유사하지만 XML이 좀 더 범용적이다. 여기서는 lxml을 이용해서 XML 형식에서 데이터를 파싱하는 방법을 살펴보겠다.
뉴욕 MTAMetropolitan Transportation Authority는 버스와 전철 운영에 관한 여러 가지 데이터를 공개하고 있다. 그중에서 살펴볼 것은 XML 파일로 제공되는 실적 자료다. 전철과 버스 운영은 매월 다음과 같은 비슷한 내용의 각기 다른 파일(Metro-North Railroad의 경우 Performance_MNR.xml)로 제공된다.

lxml.objectify를 이용해서 파일을 파싱한 후 getroot() 함수를 이용해서 XML 파일의 루트 노드에 대한 참조를 얻어오자.
from lxml import objectify
path = 'examples/Performance_MNR.xml'
parsed = objectify.parse(open(path))
root = parsed.getroot()
root.INDICATOR를 이용해서 모든 <INDICATOR> XML 엘리먼트를 끄집어낼 수 있다. 각각의 행목에 대해 몇몇 태그는 제외하고 태그 이름(YTD_ACTUAL 같은)을 키값으로 하는 사전을 만들어낼 수 있다.
data = []
skip_fields = ['PARENT_SEQ', 'INDICATOR_SEQ',
'DESIRED_CHAGE', 'EDCIMAL_PLACES']
for elt in root.INDICATOR:
el_data = {}
for child in elt.getchildren():
if child.tag in skip_fields:
continue
el_data[child.tag] = child.pyval
data.append(el_data)
# 사전 리스트 data를 데이터프레임으로 변환하자.
perf = pd.DataFrame(data)
print(perf.head())
AGENCY_NAME INDICATOR_NAME \
0 Metro-North Railroad On-Time Performance (West of Hudson)
1 Metro-North Railroad On-Time Performance (West of Hudson)
2 Metro-North Railroad On-Time Performance (West of Hudson)
3 Metro-North Railroad On-Time Performance (West of Hudson)
4 Metro-North Railroad On-Time Performance (West of Hudson)
DESCRIPTION PERIOD_YEAR \
0 Percent of commuter trains that arrive at thei... 2008
1 Percent of commuter trains that arrive at thei... 2008
2 Percent of commuter trains that arrive at thei... 2008
3 Percent of commuter trains that arrive at thei... 2008
4 Percent of commuter trains that arrive at thei... 2008
PERIOD_MONTH CATEGORY FREQUENCY DESIRED_CHANGE INDICATOR_UNIT \
0 1 Service Indicators M U %
1 2 Service Indicators M U %
2 3 Service Indicators M U %
3 4 Service Indicators M U %
4 5 Service Indicators M U %
DECIMAL_PLACES YTD_TARGET YTD_ACTUAL MONTHLY_TARGET MONTHLY_ACTUAL
0 1 95.0 96.9 95.0 96.9
1 1 95.0 96.0 95.0 95.0
2 1 95.0 96.3 95.0 96.9
3 1 95.0 96.8 95.0 98.3
4 1 95.0 96.6 95.0 95.8
XML 데이터를 얻으려면 지금 본 예제보다 훨씬 더 복잡한 과정을 거쳐야 한다. 각각의 태그 또한 메타데이터를 가지고 있을 수 있다. 유효한 XML 형식인 HTML의 <a> 태그를 생각하면 된다.
from io import StringIO
tag = '<a href="http://www.google.com">Google</a>'
root = objectify.parse(StringIO(tag)).getroot()
# 이제 태그나 링크 이름에서 어떤 필드(href 같은)라도 접근이 가능하다.
root
<Element a at 0x1b71e360340>
print(root.get('href'))
print('\n')
print(root.text)
http://www.google.com Google
웹 스크래핑
BeautifulSoup 등 웹 스크래핑(scraping) 도구로 수집한 데이터를 판다스 데이터프레임으로 정리하는 방법을 설명한다. 먼저 스크래핑한 내용을 파이썬 리스트, 딕셔너리 등으로 정리한 뒤 DataFrame() 함수에 리스트나 딕셔너리 형태로 전달하여 데이터프레임으로 변환한다.
다음 예제는 위키피디아에서 미국 ETF 리스트2 데이터를 가져와서 데이터프레임으로 변환하는 것이다.
# 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
import re
# 위키피디아 미국 ETF 웹 페이지에서 필요한 정보를 스크래핑하여 딕셔너리 형태로 변수 etfs에 저장
url = "https://en.wikipedia.org/wiki/List_of_American_exchange-traded_funds"
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'lxml')
rows = soup.select('div > ul > li')
etfs = {}
for row in rows:
try:
etf_name = re.findall('^(.*) \(NYSE', row.text)
etf_market = re.findall('\((.*)\|', row.text)
etf_ticker = re.findall('NYSE Arca\|(.*)\)', row.text)
if (len(etf_ticker) > 0) & (len(etf_market) > 0) & (len(etf_name) > 0):
etfs[etf_ticker[0]] = [etf_market[0], etf_name[0]]
except AttributeError as err:
pass
# etfs 딕셔너리 출력
print(etfs)
print('\n')
# etfs 딕셔너리를 데이터프레임으로 변환
df = pd.DataFrame(etfs)
print(df)
{}
Empty DataFrame
Columns: []
Index: []
웹 사이트 개편으로 오류가 발생하였지만, 코드 내용 중 etfs[etf_ticker[0]] = [etf_market[0], etf_name[0]]와 같이 리스트를 원소로 갖는 딕셔너리를 정의하는 방법을 반드시 기억하도록 한다.
API 활용하여 데이터 수집하기
인터넷 서비스 업체에서 제공하는 API를 통해서 수집한 데이터를 판다스 자료구조로 변환하는 방법을 살펴보자. 대부분의 API는 판다스에서 쉽게 읽어올 수 있는 파일 형식(csv, json, xml, …)을 지원한다. 따라서 API를 통해 가져온 데이터를 판다스 데이터프레임으로 손쉽게 변환할 수 있다. 그중 가장 손쉬운 방법은 requests 패키지3를 이용하는 것이다.
판다스 깃허브에서 최근 30개의 이슈를 가져오려면 requests 라이브러리를 이용해서 다음과 같은 GET HTTP 요청을 생성하면 된다.
import requests
url = 'https://api.github.com/repos/pandas-dev/pandas/issues'
resp = requests.get(url)
print(resp)
<Response [200]>
응답 객체의 json 메서드는 JSON의 내용을 파이썬 사전 형태로 변환한 객체를 반환한다.
data = resp.json()
print(data[0]['title'])
Create pr action/pre commit config update 0
data의 각 항목은 깃허브 이슈 페이지(댓글 제외)에서 찾을 수 있는 모든 데이터를 담고 있다. 이 data를 바로 데이터프레임으로 생성하고 관심이 있는 필드만 따로 추출할 수 있다.
issues = pd.DataFrame(data, columns=['number', 'title',
'labels', 'state'])
print(issues)
number title \
0 48069 Create pr action/pre commit config update 0
1 48068 Adding obvious type hints to pandas
2 48067 TST: Check index when grouping all columns of ...
3 48066 CI: Avoid flaky build errors & show installed ...
4 48065 CI/DEPS: Fix timezone test due to pytz upgrade
5 48064 BUG: Groupby cumprod nan influences other colu...
6 48063 fixed docstring error with pandas.Series.plot....
7 48062 REF: make copy keyword non-stateful
8 48061 STYLE: upgrade flake8
9 48060 DOC: "Creating a Python environment" in "Creat...
10 48058 REGR: fix reset_index (Index.insert) regressio...
11 48057 REGR: fix regression in scalar setitem with se...
12 48056 BUG: Rolling operations on groupby with apply ...
13 48055 Fixed docstring error with style.py, unknown p...
14 48052 BUG: Weird Behavior of astype(bool) for np.nan
15 48051 REF: dont alter self in _validate_specification
16 48050 ENH: allow user to infer SAS file encoding; ad...
17 48049 ENH: Deny/permit configuration for read_pickle...
18 48048 ENH: Add option to `read_sas` to infer encodin...
19 48046 CI: setuptools 64.0.0 breaks our builds
20 48042 TST: GH39984 Addition to tests
21 48041 CI: Include FutureWarning from numpy in npdev ...
22 48039 Unclear error statement printed when `python ....
23 48038 ENH: Improve styling compatibility with Latex
24 48035 DOC: "Committing your code" in "Contributing t...
25 48034 BUG: `Series.replace` converts `np.nan` into `...
26 48033 ENH: raise_assert_detail only shows the differ...
27 48032 BUG: Union of multi index with EA types can lo...
28 48030 ENH: Add rolling.prod()
29 48028 CLN: Refactor groupby's _make_wrapper
labels state
0 [] open
1 [{'id': 1280988427, 'node_id': 'MDU6TGFiZWwxMj... open
2 [] open
3 [{'id': 48070600, 'node_id': 'MDU6TGFiZWw0ODA3... open
4 [{'id': 48070600, 'node_id': 'MDU6TGFiZWw0ODA3... open
5 [{'id': 76811, 'node_id': 'MDU6TGFiZWw3NjgxMQ=... open
6 [{'id': 2413328, 'node_id': 'MDU6TGFiZWwyNDEzM... open
7 [{'id': 127681, 'node_id': 'MDU6TGFiZWwxMjc2OD... open
8 [{'id': 106935113, 'node_id': 'MDU6TGFiZWwxMDY... open
9 [{'id': 134699, 'node_id': 'MDU6TGFiZWwxMzQ2OT... open
10 [{'id': 32815646, 'node_id': 'MDU6TGFiZWwzMjgx... open
11 [{'id': 2822098, 'node_id': 'MDU6TGFiZWwyODIyM... open
12 [{'id': 76811, 'node_id': 'MDU6TGFiZWw3NjgxMQ=... open
13 [{'id': 134699, 'node_id': 'MDU6TGFiZWwxMzQ2OT... open
14 [{'id': 2822342, 'node_id': 'MDU6TGFiZWwyODIyM... open
15 [{'id': 127681, 'node_id': 'MDU6TGFiZWwxMjc2OD... open
16 [{'id': 258745163, 'node_id': 'MDU6TGFiZWwyNTg... open
17 [{'id': 76812, 'node_id': 'MDU6TGFiZWw3NjgxMg=... open
18 [{'id': 76812, 'node_id': 'MDU6TGFiZWw3NjgxMg=... open
19 [{'id': 48070600, 'node_id': 'MDU6TGFiZWw0ODA3... open
20 [{'id': 127685, 'node_id': 'MDU6TGFiZWwxMjc2OD... open
21 [{'id': 48070600, 'node_id': 'MDU6TGFiZWw0ODA3... open
22 [] open
23 [{'id': 251382258, 'node_id': 'MDU6TGFiZWwyNTE... open
24 [{'id': 134699, 'node_id': 'MDU6TGFiZWwxMzQ2OT... open
25 [{'id': 76811, 'node_id': 'MDU6TGFiZWw3NjgxMQ=... open
26 [{'id': 127685, 'node_id': 'MDU6TGFiZWwxMjc2OD... open
27 [{'id': 76811, 'node_id': 'MDU6TGFiZWw3NjgxMQ=... open
28 [{'id': 76812, 'node_id': 'MDU6TGFiZWw3NjgxMg=... open
29 [{'id': 233160, 'node_id': 'MDU6TGFiZWwyMzMxNj... open
조금만 더 수고하면 평범한 웹 API를 위한 고수준의 인터페이스를 만들어서 데이터프레임에 저장하고 쉽게 분석 작업을 수행할 수 있다.
데이터베이스와 함께 사용하기
비지니스 관점에서 대부분의 데이터는 텍스트 파일이나 엑셀 파일로 저장하지 않고 SQL 기반의 관계형 데이터베이스(SQL 서버, PostgreSQL, MySQL)를 많이 사용하는데, 다른 종류의 대안 데이터베이스들도 꽤 인기를 끌고 있다. 데이터베이스는 보통 애플리케이션에서 필요한 성능이나 데이터 무결성 그리고 확장성에 맞춰서 선택하는 것이 일반적이다.
SQL에서 데이터를 읽어 와서 데이터프레임에 저장하는 것은 꽤 직관적이며 판다스에는 이 과정을 간결하게 해주는 몇 가지 함수가 있다. 한 예로 파이썬의 내장 sqlite3 드라이버를 사용해서 SQLite 데이터베이스를 이용할 수 있다.
import sqlite3
query = """
CREATE TABLE test
(a VARCHAR(20), b VARCHAR(20),
c REAL, d INTEGER
);"""
con = sqlite3.connect('mydata.sqlite')
con.execute(query)
con.commit()
# 데이터 입력
data = [('Atlanta', 'Georgia', 1.25, 6),
('Tallahassee', 'Florida', 2.6, 3),
('Sacramento', 'California', 1.7, 5)]
stmt = "INSERT INTO test VALUES(?, ? ,?, ?)"
con.executemany(stmt, data)
con.commit()
대부분의 파이썬 SQL 드라이버(pyODBC, psycopg2, MySQLdb, pymssql 등)는 테이블에 대해 select 쿼리를 수행하면 튜플 리스트를 반환한다.
cursor = con.execute('select * from test') # test 테이블에서 모든 데이터를 선택
rows = cursor.fetchall()
print(rows)
[('Atlanta', 'Georgia', 1.25, 6), ('Tallahassee', 'Florida', 2.6, 3), ('Sacramento', 'California', 1.7, 5)]
반환된 튜플 리스트를 데이터프레임 생성자에 바로 전달해도 되지만, 칼럼 이름을 지정해주면 더 편하다. cursor의 description 속성을 활용하자.
cursor.description
(('a', None, None, None, None, None, None),
('b', None, None, None, None, None, None),
('c', None, None, None, None, None, None),
('d', None, None, None, None, None, None))
df = pd.DataFrame(rows, columns=[x[0] for x in cursor.description])
print(df)
a b c d
0 Atlanta Georgia 1.25 6
1 Tallahassee Florida 2.60 3
2 Sacramento California 1.70 5
read_sql() 함수를 이용하면 SQL 쿼리를 가지고 데이터베이스로부터 데이터를 불러올 수 있다. 이때 일겅온 데이터는 데이터프레임 포맷으로 저장된다.
df = pd.read_sql('select * from test', con)
print(df)
a b c d
0 Atlanta Georgia 1.25 6
1 Tallahassee Florida 2.60 3
2 Sacramento California 1.70 5
데이터 저장하기
CSV 파일로 저장
판다스 데이터프레임은 2차원 배열로 구조화된 데이터이기 때문에 2차원 구조를 갖는 CSV 파일로 변환할 수 있다. 데이터프레임을 CSV 파일로 저장하려면 to_csv() 메서드를 적용한다. CSV 파일을 저장할 파일 경로와 파일명(확장자 포함)을 따옴표(“” 또는 ‘’) 안에 입력한다.
data = pd.read_csv('examples/ex5.csv')
print(data)
something a b c d message 0 one 1 2 3.0 4 NaN 1 two 5 6 NaN 8 world 2 three 9 10 11.0 12 foo
데이터프레임의 to_csv() 메서드를 이용하면 데이터를 쉼표로 구분된 형식으로 파일에 쓸 수 있다.
data.to_csv('examples/out.csv')


물론 다른 구분자도 사용 가능하다(콘솔에서 확인할 수 있도록 실제 파일로 기록하지 않고 sys.stdout에 결과를 기록하도록 했다).
import sys
data.to_csv(sys.stdout, sep='|')
|something|a|b|c|d|message 0|one|1|2|3.0|4| 1|two|5|6||8|world 2|three|9|10|11.0|12|foo
결과에서 누락된 값은 비어 있는 문자열로 나타나는데, 이것 역시 원하는 값으로 지정 가능하다.
data.to_csv(sys.stdout, na_rep='NULL')
,something,a,b,c,d,message 0,one,1,2,3.0,4,NULL 1,two,5,6,NULL,8,world 2,three,9,10,11.0,12,foo
다른 옵션을 명시하지 않으면 로우와 칼럼 이름이 같이 기록된다. 로우와 칼럼 이름을 포함하지 않으려면 다음과 같이 한다.
data.to_csv(sys.stdout, index=False, header=False)
one,1,2,3.0,4, two,5,6,,8,world three,9,10,11.0,12,foo
칼럼의 일부부만 기록할 수도 있으며, 순서를 직접 지정할 수도 있다.
data.to_csv(sys.stdout, index=False, columns=['a', 'b', 'c'])
a,b,c 1,2,3.0 5,6, 9,10,11.0
시리즈에도 to_csv() 메서드가 존재한다.
dates = pd.date_range('1/1/2000', periods=7)
ts = pd.Series(np.arange(7), index=dates)
ts.to_csv(sys.stdout)
,0 2000-01-01,0 2000-01-02,1 2000-01-03,2 2000-01-04,3 2000-01-05,4 2000-01-06,5 2000-01-07,6
JSON 파일로 저장
데이터프레임을 JSON 파일로 저장하려면 to_json() 메서드를 이용한다. JSON 파일의 이름(확장자 포함)을 저장하려는 파일 경로와 함께 따옴표(“” 또는 ‘‘)안에 입력한다.
# 판다스 DataFrame() 함수로 데이터프레임 변환. 변수 df에 저장
data = {'name': ['Jerry', 'Riah', 'Paul'],
'algol': ["A", "A+", "B"],
'basic': ["C", "B", "B+"],
'c++': ["B+", "C", "C+"]
}
df = pd.DataFrame(data)
df.set_index('name', inplace=True) # name 열을 인덱스로 지정
print(df)
# to_json() 메서드를 사용하여 JSON 파일로 내보내기. 파일명은 df_sample.json로 저장
df.to_json("./df_sample.json")
algol basic c++
name
Jerry A C B+
Riah A+ B C
Paul B B+ C+


Excel 파일로 저장
데이터프레임은 Excel 파일과 아주 유사한 구조를 갖는다. 데이터프레임의 행과 열은 Excel 파일의 행과 열로 일대일로 대응된다. 데이터프레임을 Excel 파일로 저장할 때는 to_excel() 메서드를 적용한다. 단, to_excel() 메서드를 사용하려면 openpyxl 라이브러리를 사전에 설치해야 한다.
print(df)
# to_excel() 메서드를 사용하여 Excel 파일로 내보내기. 파일명은 df_sample.xlsx로 저장
df.to_excel("./df_sample.xlsx")
algol basic c++
name
Jerry A C B+
Riah A+ B C
Paul B B+ C+
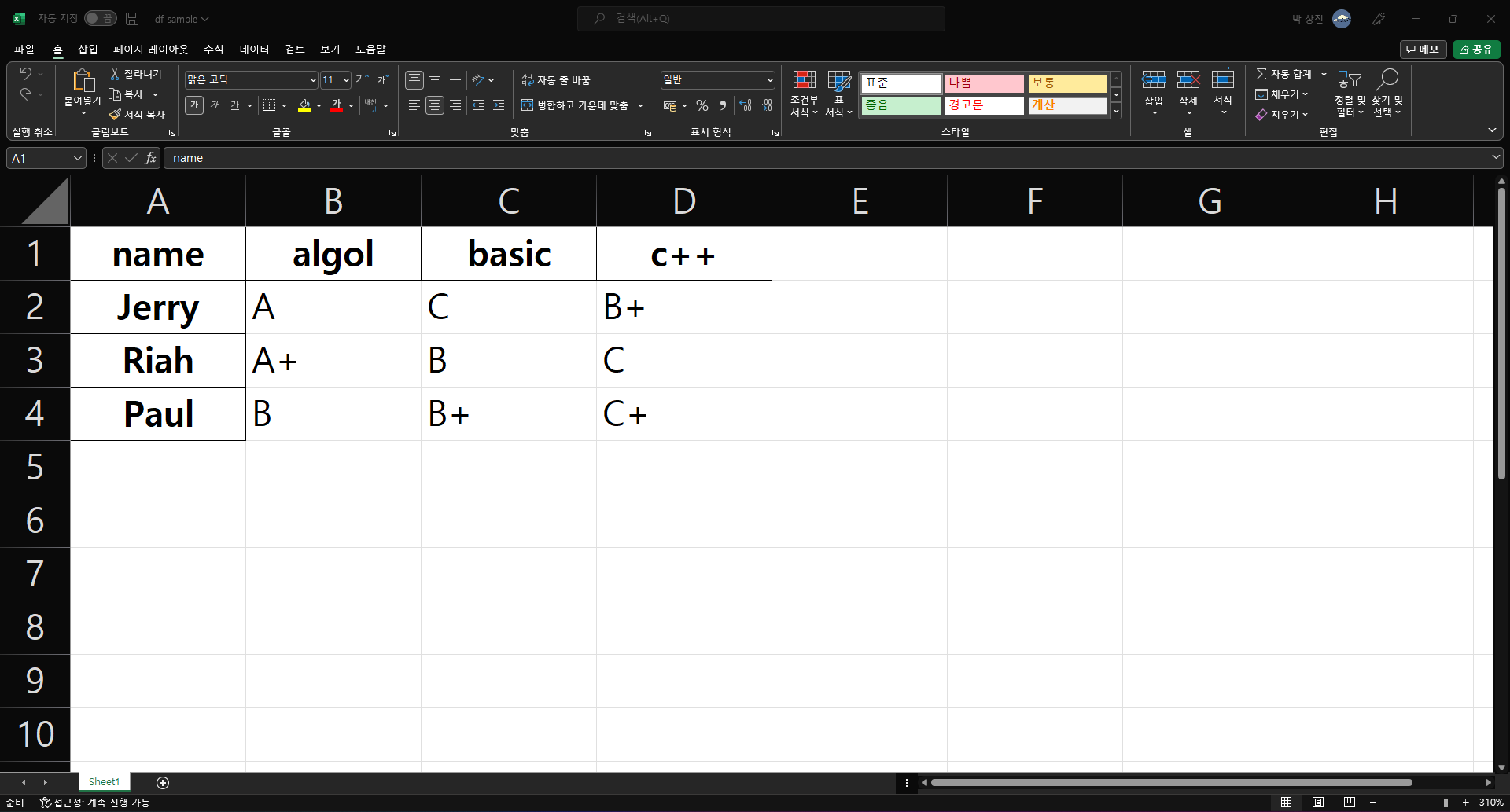
판다스 ExcelWriter() 함수는 Excel 워크북 객체를 생성한다. 워크북 객체는 우리가 알고 있는 Excel 파일이라고 생각하면 된다. 데이터프레임에 to_excel() 메서드를 적용할 때 삽입하려는 워크북 객체(Excel 파일)를 인자로 전달한다. 또한 sheet_name 옵션에 Excel 파일의 시트 이름을 입력하여 삽입되는 시트 위치를 지정할 수 있다. 한편 데이터프레임을 삽입하는 시트 이름을 다르게 설정하면, 같은 Excel 파일의 서로 다른 시트에 여러 데이터프레임을 구분하여 저장한다.
# 판다스 DataFrame() 함수로 데이터프레임 변환. 변수 df1, df2에 저장
data1 = {'name': ['Jerry', 'Riah', 'Paul'],
'algol': ["A", "A+", "B"],
'basic': ["C", "B", "B+"],
'c++': ["B+", "C", "C+"]}
data2 = {'c0': [1, 2, 3],
'c1': [4, 5, 6],
'c2': [7, 8, 9],
'c3': [10, 11, 12],
'c4': [13, 14, 15]}
df1 = pd.DataFrame(data1)
df1.set_index('name', inplace=True) # name 열을 인덱스로 지정
print(df1)
print('\n')
df2 = pd.DataFrame(data2)
df2.set_index('c0', inplace=True) # c0 열을 인덱스로 지정
print(df2)
# df1을 'sheet1'으로, df2를 'sheet2'로 저장(Excel 파일명은 "df_excelwriter.xlsx")
writer = pd.ExcelWriter("./df_excelwriter.xlsx")
df1.to_excel(writer, sheet_name="sheet1")
df2.to_excel(writer, sheet_name="sheet2")
writer.save()
algol basic c++
name
Jerry A C B+
Riah A+ B C
Paul B B+ C+
c1 c2 c3 c4
c0
1 4 7 10 13
2 5 8 11 14
3 6 9 12 15
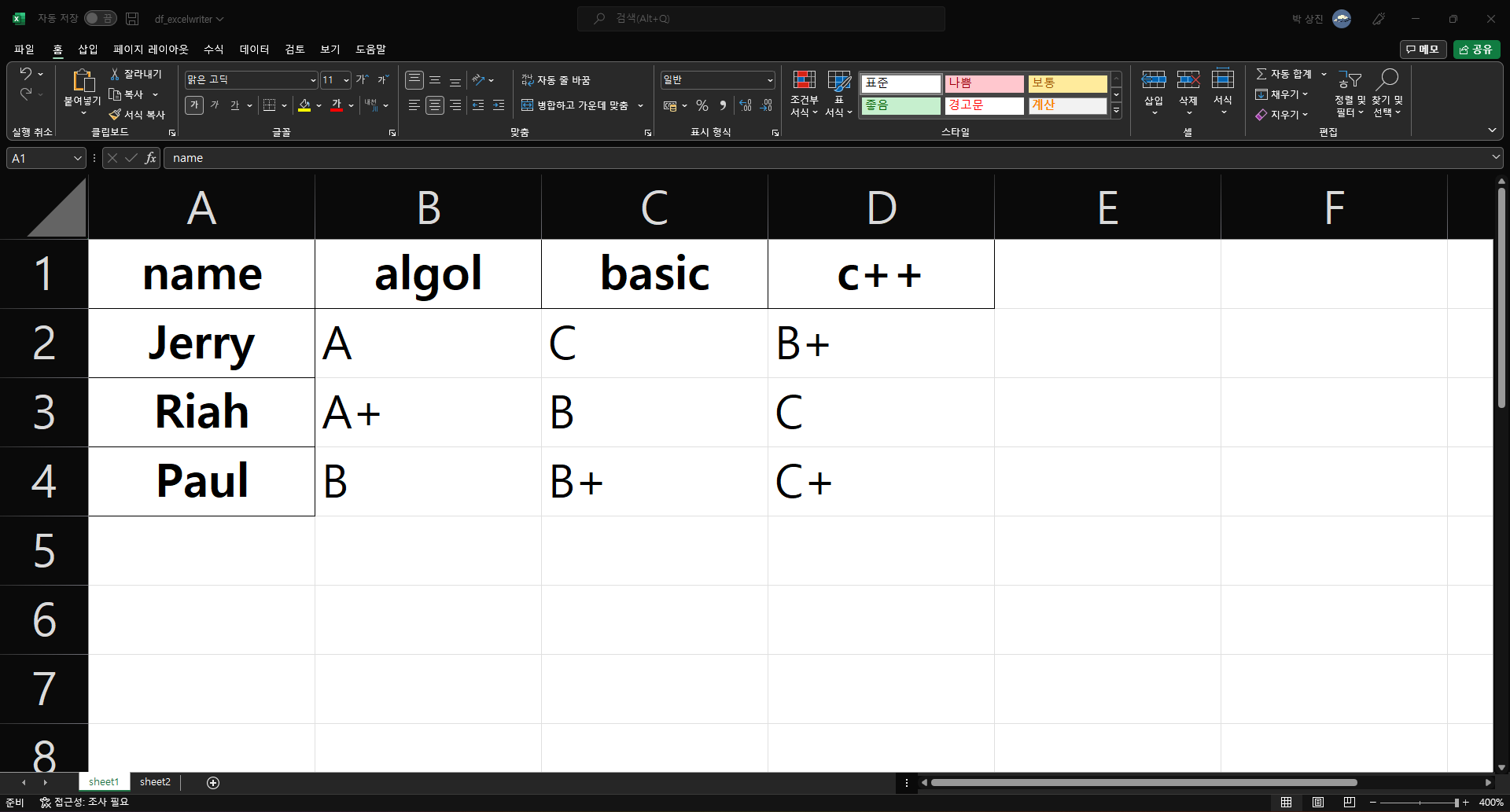
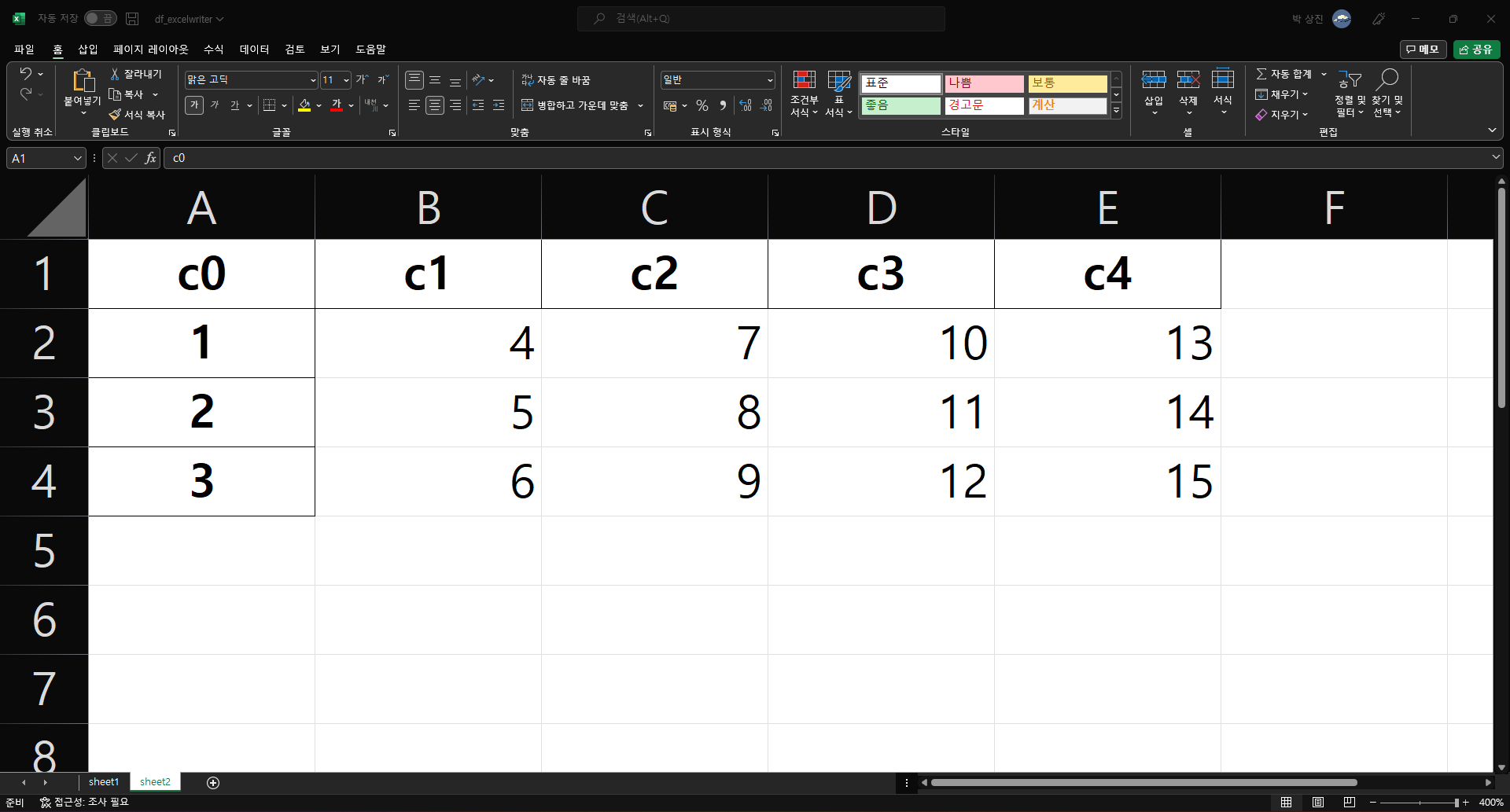
df1의 내용은 sheet1에 삽입되고 df2의 내용은 sheet2에 삽입된 것을 볼 수 있다.
이진 데이터 형식
데이터를 효율적으로 저장하는 가장 손쉬운 방법은 파이썬에 기본으로 내장되어 있는 pickle 직렬화를 사용해 데이터를 이진 형식으로 저장하는 것이다. 편리하게도 판다스 객체는 모두 pickle을 이용해서 데이터를 저장하는 to_pickle() 메서드를 가지고 있다.
frame = pd.read_csv('examples/ex1.csv')
print(frame)
frame.to_pickle('examples/frame_pickle')
a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo
pickle로 직렬화된 객체는 내장 함수인 pickle로 직접 불러오거나 아니면 좀 더 편리한 pickle 함수인 read_pickle() 메서드를 이용하여 불러올 수 있다.
df = pd.read_pickle('examples/frame_pickle')
print(df)
a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo
판다스는 HDF5와 Message-Pack, 두 가지 바이너리 포맷을 지원한다. 다양한 파일 형식이 실제 사용자의 분석 작업에 얼마나 더 적절한지 직접 살펴보기 권장한다. 다음과 같은 판다스 또는 넘파이 데이터를 위한 다른 저장 형식도 존재한다.
-
Bcolz
Blocs 압축 알고리즘에 기반한 압축이 가능한 칼럼지향 바이너리 포맷이다.
-
Feather
R 커뮤니티의 해들리 위컴과 웨스 매키니가 함께 설계한 칼럼지향 파일 형식이다. Feather는 아파치 에로우의 메모리 포맷을 사용한다.
HDF5 형식 사용하기
HDF5는 대량의 과학 계산용 배열 데이터를 저장하기 위해 고안된 훌륭한 파일 포맷이다. C 라이브러리로도 존재하며 자바, 줄리아, 매트랩, 그리고 파이썬 같은 다양한 다른 언어에서도 사용할 수 있는 인터페이스를 제공한다. HDF는 Hierarchical Data Format의 약자로 계층적 데이터 형식이라는 뜻이다. 각각의 HDF5 파일은 여러 개의 데이터셋을 저장하고 부가 정보를 기록할 수 있다. 보다 단순한 형식과 비교하면 HDF5는 다양한 압축 기술을 사용해서 온더플라이on-the-fly(실시간) 압축을 지원하며 반복되는 패턴을 가진 데이터를 좀 더 효과적으로 저장할 수 있다. 메모리에 모두 적재할 수 없는 엄청나게 큰 데이터를 아주 큰 배열에서 필요한 작은 부분들만 효과적으로 읽고 쓸 수 있는 훌륭한 선택이다.
PyTables나 h5py 라이브러리를 이용해서 직접 HDF5 파일에 접근하는 것도 가능하지만 판다스는 시리즈나 데이터프레임 객체로 간단히 저장할 수 있는 고수준의 인터페이스를 제공한다. HdFStore 클래스는 사전처럼 작동하며 세밀한 요구 사항도 잘 처리해준다.
frame = pd.DataFrame({'a': np.random.randn(100)})
store = pd.HDFStore('mydata.h5')
store['obj1'] = frame
store['obj1_col'] = frame['a']
store
<class 'pandas.io.pytables.HDFStore'> File path: mydata.h5
HDF5 파일에 포함된 객체는 파이썬 사전과 유사한 형식으로 사용 가능하다.
store['obj1']
| a | |
|---|---|
| 0 | -0.057989 |
| 1 | 0.001329 |
| 2 | 0.836392 |
| 3 | -0.095560 |
| 4 | 0.775297 |
| ... | ... |
| 95 | -0.513061 |
| 96 | -0.931065 |
| 97 | 0.014091 |
| 98 | 0.485825 |
| 99 | 0.680183 |
100 rows × 1 columns
HDFStore는 ‘fixed’와 ‘table’ 두 가지 저장 스키마를 지원한다. ‘table’ 스키마가 일반적으로 더 느리지만 아래와 같은 특별한 문법을 이용해 쿼리 연산을 지원한다.
store.put('obj2', frame, format='table')
store.select('obj2', where=['index >= 10 and index <= 15'])
| a | |
|---|---|
| 10 | -0.339296 |
| 11 | -0.682503 |
| 12 | -1.044286 |
| 13 | 1.686691 |
| 14 | -1.109805 |
| 15 | 0.810203 |
store.close()
put()은 명시적인 store[‘obj2’] = frame 메서드지만 저장 스키마를 지정하는 등의 다른 옵션을 제공한다.
read_hdf() 함수는 이런 기능들을 축약해서 사용할 수 있다.
frame.to_hdf('mydata1.h5', 'obj3', format='table')
pd.read_hdf('mydata1.h5', 'obj3', where=['index < 5'])
| a | |
|---|---|
| 0 | -0.057989 |
| 1 | 0.001329 |
| 2 | 0.836392 |
| 3 | -0.095560 |
| 4 | 0.775297 |
만일 아마존 S3나 HDFS 같은 원격 서버에 저장된 데이터를 처리해야 한다면 아파치 파케이(Parquet) 같은 분산 저장소를 고려하여 설계된 다른 바이너리 형식을 사용하는 편이 좀 더 올바른 선택일 수 있다.
만약 로컬 스토리지에서 엄청난 양의 데이터를 다뤄야 한다면 PyTables와 h5py를 살펴보고 목적에 맞는지 알아보기 권장한다. 실제로 대부분의 데이터 분석 문제는 CPU보다는 IO 성능에 의존적이므로 HDF5 같은 도구를 사용하면 애플리케이션의 성능을 어마어마하게 향상시킬 수 있다.
참고로 HDF5는 데이터베이스가 아니다. HDF5는 한 번만 기록하고 자주 여러 번 읽어야 하는 데이터에 최적화되어 있다. 데이터는 아무 때나 파일에 추가할 수 있지만 만약 여러 곳에서 동시에 파일에 추가한다면 파일이 깨지는 문제가 발생할 수 있다.
MS Excel 파일에서 데이터 읽어오기
판다스는 ExcelFile 클래스나 read_excel() 함수를 사용해서 마이크로소프트 엑셀 2003 이후 버전의 데이터를 읽어올 수 있다. 내부적으로 이들 도구는 XLS 파일과 XLSX 파일을 읽기 위해 각각 xlrd와 openpyxl 패키지를 이용한다.
ExcelFile 클래스를 사용하려면 xls나 xlsx 파일의 경로를 지정하여 객체를 생성해야 한다.
xlsx = pd.ExcelFile('examples/ex1.xlsx')
pd.read_excel(xlsx, 'Sheet1')
| Unnamed: 0 | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 1 | 5 | 6 | 7 | 8 | world |
| 2 | 2 | 9 | 10 | 11 | 12 | foo |
한 파일에서 여러 시트를 읽어오려면 ExcelFile을 생성하는게 빠르지만 간단하게는 read_excel()에 파일 이름만 넘겨도 된다.
frame = pd.read_excel('examples/ex1.xlsx', 'Sheet1')
frame
| Unnamed: 0 | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 1 | 5 | 6 | 7 | 8 | world |
| 2 | 2 | 9 | 10 | 11 | 12 | foo |
댓글남기기