데이터 정제 및 준비
데이터 분석과 모델링 작업에서는 데이터를 불러오고, 정제하고, 변형하고, 재정렬하는 데이터 준비 과정에 많은 시간을 들이게 된다. 이런 작업들은 분석 시간의 80%를 잡아먹기도 한다. 가끔은 파일이나 데이터베이스에 저장된 데이터가 애플리케이션에서 사용하기 쉽지 않은 방식으로 저장되어 있기도 한다. 대부분의 사람은 파일이나 데이터베이스에 저장된 데이터를 다른 형태로 바꾸기 위해 파이썬이나 Perl, R, Java 혹은 awk나 sed 같은 유닉스의 텍스트 처리 유틸리티를 사용하기도 하는데, 파이썬 표준 라이브러리를 판다스와 함께 사용하면 큰 수고 없이 데이터를 원하는 형태로 가공할 수 있다. 판다스는 이런 작업을 위한 유연하고 빠른 고수준의 알고리즘과 처리 기능을 제공한다.
머신러닝 등 데이터 분석의 정확도는 분석 데이터의 품질에 의해 좌우된다. 데이터 품질을 높이기 위해서는 누락 데이터, 중복 데이터 등 오류를 수정하고 분석 목적에 맞게 변형하는 과정이 필요하다. 수집한 데이터를 분석에 적합하도록 사전 처리(Preprocessing)하는 방법을 살펴보자.
누락된 데이터 처리하기
데이터프레임에는 원소 데이터 값이 종종 누락되는 경우가 있다. 데이터를 파일로 입력할 때 빠트리거나 파일 형식을 변환하는 과정에서 데이터가 소실되는 것이 주요 원인인데 이러한 누락된 데이터를 처리하는 일은 데이터 분석 애플리케이션에서 흔히 발생하는 일이다. 판다스의 설계 목표 중 하나는 누락 데이터를 가능한 한 쉽게 처리할 수 있도록 하는 것이다. 예를 들어 판다스 객체의 모든 기술 통계는 누락된 데이터를 배제하고 처리한다.
판다스 객체에서 누락된 값을 표현하는 방식은 완벽하다고 할 수 없다. 산술 데이터에 한해 판다스는 누락된 데이터를 실숫값인 NaN으로 취급한다. 이는 누락된 값을 쉽게 찾을 수 있도록 하는 파수병 역할을 한다.
또한 NaN 값은 평균, 총합 등의 함수 연산 시 제외가 된다.
머신러닝 분석 모형에 데이터를 입력하기 전에 반드시 누락 데이터를 제거하거나 다른 적절한 값으로 대체하는 과정이 필요하다. 누락 데이터가 많아지면 데이터의 품질이 떨어지고, 머신러닝 분석 알고리즘을 왜곡하는 현상이 발생하기 때문이다.
string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
string_data
0 aardvark 1 artichoke 2 NaN 3 avocado dtype: object
string_data.isnull()
0 False 1 False 2 True 3 False dtype: bool
판다스에서는 R 프로그래밍 언어에서의 결측치를 NANot Available로 취급하는 개념을 차용했다. 분석 애플리케이션에서 NA 데이터는 데이터가 존재하지 않거나, 존재하더라도 데이터를 수집하는 과정 등에서 검출되지 않았음을 의미한다. 분석을 위해 데이터를 정제하는 과정에서 결측치 자체를 데이터 수집 과정에서의 실수나 결측치로 인한 잠재적인 편향을 찾아내는 수단으로 인식하는 것은 중요하다.
파이썬의 내장 None 값 또한 NA 값으로 취급된다.
string_data[0] = None
string_data.isnull()
0 True 1 False 2 True 3 False dtype: bool
판다스 프로젝트에서는 결측치를 처리하는 방법을 개선하는 작업이 진행 중이지만 isnull() 같은 사용자 API 함수에서는 성가신 부분을 추상화로 제거했다. 다음은 결측치 처리와 관련된 함수를 정리해두었다.
| 인자 | 설명 |
|---|---|
| dropna | 누락된 데이터가 있는 축(로우, 칼럼)을 제외시킨다. 어느 정도의 누락 데이터까지 용인할 것인지 지정할 수 있다. |
| fillna | 누락된 데이터를 대신할 값을 채우거나 'ffill' 이나 'bfill' 같은 보간 메서드를 적용한다. |
| isnull | 누락되거나 NA인 값을 알려주는 불리언값이 저장된 같은 형의 객체를 반환한다. |
| notnull | isnull과 반대되는 메서드 |
누락된 데이터 골라내기
누락된 데이터를 골라내는 몇 가지 방법이 있는데, isnull()이나 불리언 인덱싱을 사용해 직접 손으로 제거하는 것도 한 가지 방법이지만, dropna()를 매우 유용하게 사용할 수 있다. 시리즈에 dropna() 메서드를 적용하면 널이 아닌non-null 데이터와 인덱스 값만 들어 있는 시리즈를 반환한다.
from numpy import nan as NA
data = pd.Series([1, NA, 3.5, NA, 7])
print(data)
print('\n')
print(data.dropna())
0 1.0 1 NaN 2 3.5 3 NaN 4 7.0 dtype: float64 0 1.0 2 3.5 4 7.0 dtype: float64
# 위 코드와 유사하다.
data[data.notnull()]
0 1.0 2 3.5 4 7.0 dtype: float64
데이터프레임 객체의 경우에는 조금 복잡한데, 모두 NA 값인 로우나 칼럼을 제외시키거나 NA 값을 하나라도 포함하고 있는 로우나 칼럼을 제외시킬 수 있다. dropna()는 기본적으로 NA 값을 하나라도 포함하고 있는 로우를 제외시킨다.
data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],
[NA, NA, NA], [NA, 6.5, 3.]])
cleaned = data.dropna()
print(data)
print('\n')
print(cleaned)
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
0 1 2
0 1.0 6.5 3.0
how=’all’ 옵션을 넘기면 모두 NA 값인 로우만 제외시킨다.
data.dropna(how='all')
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1.0 | 6.5 | 3.0 |
| 1 | 1.0 | NaN | NaN |
| 3 | NaN | 6.5 | 3.0 |
칼럼을 제외시키는 방법도 동일하게 동작한다. 옵션으로 axis=1을 넘겨주면 된다.
data[4] = NA
print(data)
print('\n')
print(data.dropna(axis=1, how='all'))
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
데이터프레임의 로우를 제외시키는 방법은 시계열 데이터에 주로 사용되는 경향이 있다. 몇 개 이상의 값이 들어 있는 로우만 살펴보고 싶다면 thresh 인자에 원하는 값을 넘기면 된다.
df = pd.DataFrame(np.random.randn(7, 3))
df.iloc[:4, 1] = NA
df.iloc[:2, 2] = NA
print(df)
print('\n')
print(df.dropna())
print('\n')
print(df.dropna(thresh=2)) # NaN값을 2개 이상 갖는 모든 행을 삭제
0 1 2
0 -1.217909 NaN NaN
1 0.837906 NaN NaN
2 -0.132805 NaN -1.406148
3 -0.859423 NaN -0.391956
4 1.845769 -0.121270 -0.839991
5 -0.921043 -0.706578 1.277880
6 -0.372958 -1.020079 -1.055084
0 1 2
4 1.845769 -0.121270 -0.839991
5 -0.921043 -0.706578 1.277880
6 -0.372958 -1.020079 -1.055084
0 1 2
2 -0.132805 NaN -1.406148
3 -0.859423 NaN -0.391956
4 1.845769 -0.121270 -0.839991
5 -0.921043 -0.706578 1.277880
6 -0.372958 -1.020079 -1.055084
dropna()를 이용하면 결측치가 있는 행을 제거할 수 있다. subset 인자에 []를 이용해 변수명을 입력하면 된다.
df.dropna(subset=[2]) # 칼럼 2가 결측치가 아닌 행만 출력
| 0 | 1 | 2 | |
|---|---|---|---|
| 2 | -0.132805 | NaN | -1.406148 |
| 3 | -0.859423 | NaN | -0.391956 |
| 4 | 1.845769 | -0.121270 | -0.839991 |
| 5 | -0.921043 | -0.706578 | 1.277880 |
| 6 | -0.372958 | -1.020079 | -1.055084 |
dropna()의 subset에 변수를 나열하면 여러 변수에 결측치가 없는 행을 추출할 수 있다.
df.dropna(subset=[1, 2]) # 칼럼 1과 칼럼2 결측치 제거
| 0 | 1 | 2 | |
|---|---|---|---|
| 4 | 1.845769 | -0.121270 | -0.839991 |
| 5 | -0.921043 | -0.706578 | 1.277880 |
| 6 | -0.372958 | -1.020079 | -1.055084 |
간편하게 dropna()만 사용하면 결측치를 모두 제거하여 간편하지만, 분석에 필요한 행까지 손실된다는 단점이 있다. 따라서 분석에 사용할 변수를 직접 지정해 결측치를 제거하는 방법을 권한다.
결측치 채우기
데이터가 크고 결측치가 얼마 없을 때는 결측치를 제거하고 분석하더라도 무리가 없다. 하지만 데이터가 작고 결측치가 많을 때는 결측치를 제거하면 너무 많은 데이터가 손실되어 분석 결과가 왜곡되는 문제가 생긴다. 또한, 누락 데이터를 무작정 삭제해 버린다면 어렵게 수집한 데이터를 활용하지 못하게 된다. 데이터 분석의 정확도는 데이터의 품질 외에도 제공되는 데이터의 양에 의해 상당한 영향을 받는다. 따라서 데이터 중에서 일부가 누락되어 있더라도 나머지 데이터를 최대한 살려서 데이터 분석에 활용하는 것이 좋은 결과를 얻는 경우가 많다.
결측치를 제거하는 대신 다른 값을 채워 넣는 방법도 있는데, 이를 결측치 대체법imputation이라고 한다. 결측치를 다른 값으로 대체하면 데이터가 손실되어 분석 결과가 왜곡되는 문제를 보완할 수 있다.이 경우 fillna() 메서드를 활용하면 되는데, fillna() 메서드에 채워 넣고 싶은 값을 넘겨주면 된다.
결측치를 대체하는 방법에는 데이터의 분포와 특성을 잘 나타낼 수 있는 평균값이나 최빈값 같은 대표값을 구해 모든 결측치를 하나의 값으로 일괄 대체하는 방법과 통계 분석 기법으로 결측치의 예측값을 추정해 대체하는 방법이 있다.
df.fillna(0)
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | -1.217909 | 0.000000 | 0.000000 |
| 1 | 0.837906 | 0.000000 | 0.000000 |
| 2 | -0.132805 | 0.000000 | -1.406148 |
| 3 | -0.859423 | 0.000000 | -0.391956 |
| 4 | 1.845769 | -0.121270 | -0.839991 |
| 5 | -0.921043 | -0.706578 | 1.277880 |
| 6 | -0.372958 | -1.020079 | -1.055084 |
fillna()에 사전값을 넘겨서 각 칼럼마다 다른 값을 채울 수도 있다.
df.fillna({1: 0.5, 2: 0})
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | -1.217909 | 0.500000 | 0.000000 |
| 1 | 0.837906 | 0.500000 | 0.000000 |
| 2 | -0.132805 | 0.500000 | -1.406148 |
| 3 | -0.859423 | 0.500000 | -0.391956 |
| 4 | 1.845769 | -0.121270 | -0.839991 |
| 5 | -0.921043 | -0.706578 | 1.277880 |
| 6 | -0.372958 | -1.020079 | -1.055084 |
fillna()는 새로운 객체를 반환하지만 다음처럼 기존 객체를 변경할 수도 있다.
_ = df.fillna(0, inplace=True)
df
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | -1.217909 | 0.000000 | 0.000000 |
| 1 | 0.837906 | 0.000000 | 0.000000 |
| 2 | -0.132805 | 0.000000 | -1.406148 |
| 3 | -0.859423 | 0.000000 | -0.391956 |
| 4 | 1.845769 | -0.121270 | -0.839991 |
| 5 | -0.921043 | -0.706578 | 1.277880 |
| 6 | -0.372958 | -1.020079 | -1.055084 |
데이터셋의 특성상 서로 이웃하고 있는 데이터끼리 유사성을 가질 가능성이 높다. 이럴 때는 앞이나 뒤에서 이웃하고 있는 값으로 치환해 주는 것이 좋다.
재인덱싱에서 사용 가능한 보간 메서드는 fillna() 메서드에서도 사용 가능하다.
df = pd.DataFrame(np.random.randn(6, 3))
df.iloc[2:, 1] = NA
df.iloc[4:, 2] = NA
df
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0.489194 | -1.846255 | 0.864160 |
| 1 | 0.810077 | 2.235698 | -0.262641 |
| 2 | -0.865866 | NaN | 1.305211 |
| 3 | 1.439591 | NaN | 0.237947 |
| 4 | -0.128130 | NaN | NaN |
| 5 | -0.153638 | NaN | NaN |
df.fillna(method='ffill')
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0.489194 | -1.846255 | 0.864160 |
| 1 | 0.810077 | 2.235698 | -0.262641 |
| 2 | -0.865866 | 2.235698 | 1.305211 |
| 3 | 1.439591 | 2.235698 | 0.237947 |
| 4 | -0.128130 | 2.235698 | 0.237947 |
| 5 | -0.153638 | 2.235698 | 0.237947 |
df.fillna(method='ffill', limit=2)
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0.489194 | -1.846255 | 0.864160 |
| 1 | 0.810077 | 2.235698 | -0.262641 |
| 2 | -0.865866 | 2.235698 | 1.305211 |
| 3 | 1.439591 | 2.235698 | 0.237947 |
| 4 | -0.128130 | NaN | 0.237947 |
| 5 | -0.153638 | NaN | 0.237947 |
조금만 창의적으로 생각하면 fillna()를 이용해서 매우 다양한 일을 할 수 있는데 예를 들어 시리즈의 평균값이나 중간값을 전달할 수도 있다.
data = pd.Series([1., NA, 3.5, NA, 7])
data.fillna(data.mean())
0 1.000000 1 3.833333 2 3.500000 3 3.833333 4 7.000000 dtype: float64
fillna()에 대한 설명은 다음을 참조하자.
| 인자 | 설명 |
|---|---|
| value | 비어 있는 값을 채울 스칼라값이나 사전 형식의 객체 |
| method | 보간 방식. 기본적으로 'ffill'을 사용한다. |
| axis | 값을 채워 넣을 축. 기본값은 axis=0이다. |
| inplace | 복사본을 생성하지 않고 호출한 객체를 변경한다. 기본값은 False다. |
| limit | 값을 앞 혹은 뒤에서부터 몇 개까지 채울지 지정한다. |
누락 데이터가 NaN으로 표시되지 않은 경우
데이터셋 중에는 누락 데이터가 NaN으로 입력되지 않은 경우도 많다. 예를 들면, 숫자 0이나 문자 ‘-‘, ‘?’ 같은 값으로 입력되기도 한다. 판다스에서 누락 데이터를 다루려면 replace() 메서드를 활용하여 NumPy에서 지원하는 np.nan으로 변경해 주는 것이 좋다.
* 사용법 예(‘?’을 np.nan으로 치환):df.replace('?', np.nan, inplace=True)
이상치 정제하기
정상 범위에서 크게 벗어난 값을 이상치anomaly라고 한다. 데이터 수집 과정에서 오류가 발생할 수 있기 때문에 현장에서 만들어진 실제 데이터에는 대부분 이상치가 들어 있다. 오류는 아니지만 매우 드물게 발생하는 극단적인 값이 데이터에 들어 있기도 한다. 이상치가 들어 있으면 분석 결과가 왜곡되므로 분석에 앞서 이상치를 제거하는 작업을 해야 한다.
논리적으로 존재할 수 없는 값이 데이터에 들어 있을 때가 있다. 예를 들어, 남자는 1, 여자는 2로 되어 있는 성별 변수에 3이라는 값이 들어 있는 경우다. 이는 분명한 오류이므로 결측치로 변환한 다음 제거하고 분석하면 된다.
df = pd.DataFrame({'sex': [1, 2, 1, 3, 2, 1],
'score': [5, 4, 3, 4, 2, 6]})
df
| sex | score | |
|---|---|---|
| 0 | 1 | 5 |
| 1 | 2 | 4 |
| 2 | 1 | 3 |
| 3 | 3 | 4 |
| 4 | 2 | 2 |
| 5 | 1 | 6 |
이상치 확인하기
데이터에 이상치가 들어 있는지 확인하려면 value_counts()를 이용해 빈도표를 만들면 된다.
df['sex'].value_counts().sort_index()
1 3 2 2 3 1 Name: sex, dtype: int64
df['score'].value_counts().sort_index()
2 1 3 1 4 2 5 1 6 1 Name: score, dtype: int64
value_counts()에 sort_index()를 적용하면 빈도 기준으로 내림차순 정렬하지 않고 변수의 값 순서로 정렬한다.
결측 처리하기
변수에 이상치가 들어 있다는 것을 확인했으니 이상치를 결측치로 바꾼다. np.where()를 이용해 이상치일 경우 NaN을 부여하면 된다.
# sex가 3이면 NaN 부여
df['sex'] = np.where(df['sex']==3, NA, df['sex'])
df
| sex | score | |
|---|---|---|
| 0 | 1.0 | 5 |
| 1 | 2.0 | 4 |
| 2 | 1.0 | 3 |
| 3 | NaN | 4 |
| 4 | 2.0 | 2 |
| 5 | 1.0 | 6 |
# score가 5보다 크면 NaN 부여
df['score'] = np.where(df['score'] == 5, NA, df['score'])
df
| sex | score | |
|---|---|---|
| 0 | 1.0 | NaN |
| 1 | 2.0 | 4.0 |
| 2 | 1.0 | 3.0 |
| 3 | NaN | 4.0 |
| 4 | 2.0 | 2.0 |
| 5 | 1.0 | 6.0 |
sex, score 변수 모두 이상치를 결측치로 변환했으니 결측치를 제거하고 분석하면 된다.
df.dropna(subset=['sex', 'score']) \ # sex, score 결측치 제거
.groupby('sex') \ # sex 별 분리
.agg(mean_score=('score', 'mean')) # score 평균 구하기
| mean_score | |
|---|---|
| sex | |
| 1.0 | 4.5 |
| 2.0 | 3.0 |
사실 다음처럼 dropna()로 결측치를 제거하지 않아도 위와 같은 결과를 낼 수 있다. 그 이유는 pd.mean(), pd.sum()과 같은 수치 연산 함수는 결측치가 있으면 자동으로 제거하고 연산하는 기능이 있기 때문이다. 그래서 groupby()와 agg()를 이용해 집단별 요약 통계량을 구할 때도 결측치를 제거하고 연산한다.
df.groupby('sex').agg(mean_score=('score', 'mean'))
| mean_score | |
|---|---|
| sex | |
| 1.0 | 4.5 |
| 2.0 | 3.0 |
자동으로 결측치를 제거하는 기능은 편리한 측면이 있지만, 결측치가 있는지 모른 채로 데이터를 다루게 된다는 위험이 있다. 데이터의 특징을 잘 이해하고 분석하기 위해 결측치가 있는지 직접 확인하고 dropna()를 이용해 명시적으로 제거하는 방법을 권한다.
np.where()는 문자와 NaN을 함께 반환할 수 없다.
np.where()는 반환하는 값 중에 문자가 있으면 np.nan을 지정하더라도 결측치 NaN이 아니라 문자 ‘nan’을 반환하므로 주의해야 한다. 다음 코드의 출력 결과를 보면 조건에 맞지 않을 때 np.nan을 부여했는데도 출력값은 ‘nan’이다. isna()로 결측치가 있는지 확인해보면 모든 값이 False이다.
df = pd.DataFrame({'x1': [1, 1, 2, 2]})
df['x2'] = np.where(df['x1'] == 1, 'a', NA) # 조건에 맞으면 문자 부여
print(df)
print('\n')
print(df.isna())
x1 x2
0 1 a
1 1 a
2 2 nan
3 2 nan
x1 x2
0 False False
1 False False
2 False False
3 False False
따라서 다음 절차를 따르면 변수를 문자와 NaN으로 함께 구성할 수 있다.
np.where()를 이용해 결측치로 만들 값에 문자를 부여한다.
# 결측치로 만들 값에 문자 부여
df['x2'] = np.where(df['x1'] == 1, 'a', 'etc')
df
| x1 | x2 | |
|---|---|---|
| 0 | 1 | a |
| 1 | 1 | a |
| 2 | 2 | etc |
| 3 | 2 | etc |
replace()를 이용해 결측치로 만들 문자를 np.nan으로 바꾼다. 자세한 내용은 앞서 말했던 “누락 데이터가 NaN으로 표시되지 않은 경우”를 참조한다.
# 'etc'를 NaN으로 바꾸기
df['x2'] = df['x2'].replace('etc', NA)
print(df)
print('\n')
print(df.isna())
x1 x2
0 1 a
1 1 a
2 2 NaN
3 2 NaN
x1 x2
0 False False
1 False False
2 False True
3 False True
극단적인 값
논리적으로 존재할 수 있지만 극단적으로 크거나 작은 값을 극단치outlier라고 한다. 예를 들어 몸무게 변수에 200kg 이상의 값이 있다면, 이는 존재할 가능성은 있지만 매우 드문 경우이므로 극단치라고 볼 수 있다. 데이터에 극단치가 있으면 분석 결과가 왜곡될 수 있으므로 분석하기 전에 제거해야 한다.
극단치를 제거하려면 먼저 어디까지를 정상 범위로 볼 것인지 정해야 한다. 가장 쉬운 방법은 논리적으로 판단해 정하는 것이다. 예를 들어 성인의 몸무게가 40 ~ 150kg을 벗어나는 경우는 매우 드물다고 판단하고, 이 범위를 벗어나면 극단치로 간주하는 것이다.
두 번째 방법은 통계적인 기준을 이용하는 것이다. 예를 들어 상하위 0.3% 또는 ±3 표준편차에 해당할 만큼 극단적으로 크거나 작으면 극단치로 간주하는 것이다.
상자 그림으로 극단치 기준 정하기
상자 그림box plot을 이용해 중심에서 크게 벗어난 값을 극단치로 간주하는 방법도 있다. 상자 그림은 데이터의 분포를 직사각형의 상자 모양으로 표현한 그래프이다. 상자 그림을 보면 데이터의 분포를 한눈에 알 수 있다.
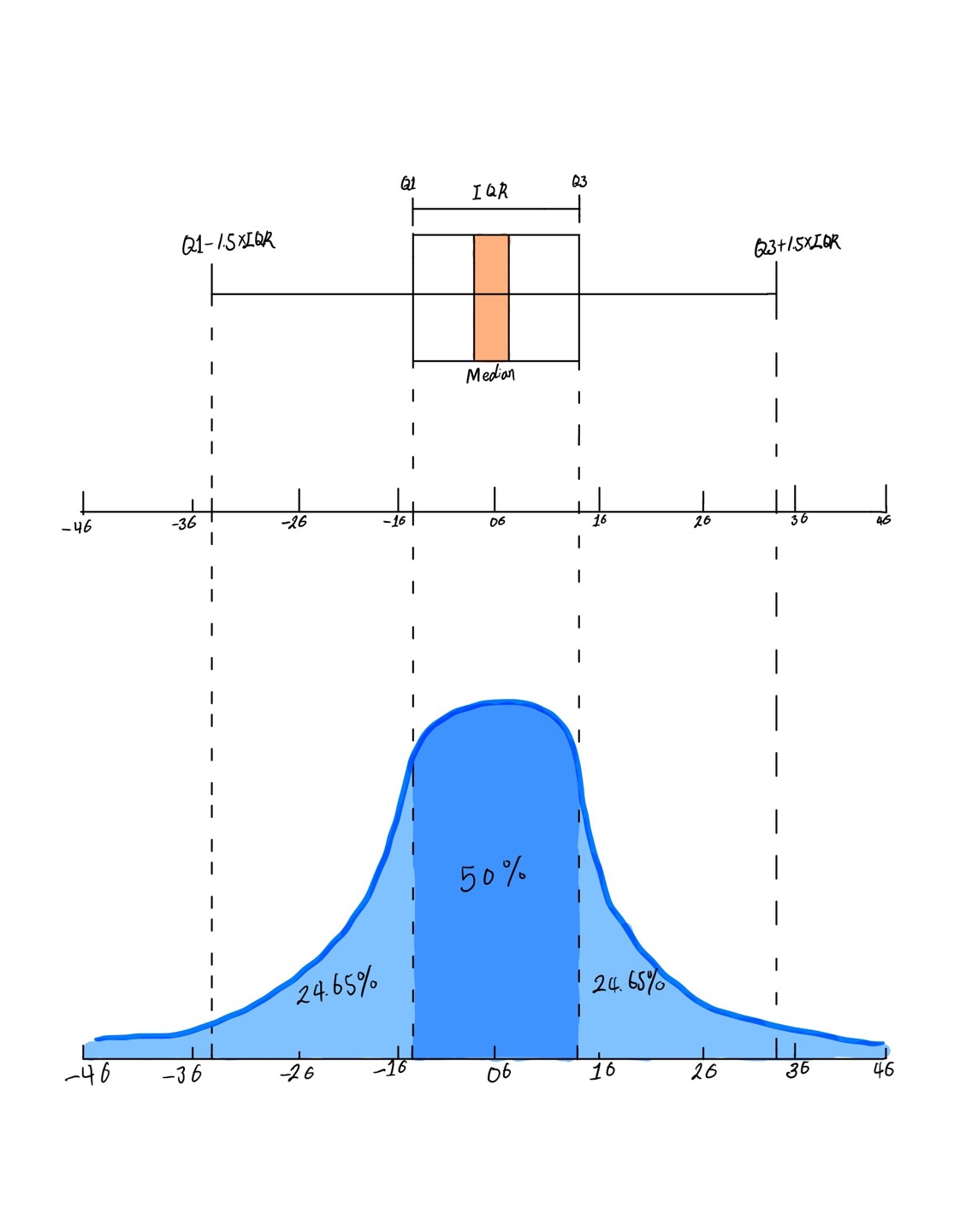
상자 그림은 중심에서 멀리 떨어진 값을 점으로 표현하는데, 이를 이용해 극단치의 기준을 정할 수 있다. 상자 그림을 이용해 극단치 기준을 구하는 방법을 알아보자.
상자 그림 살펴보기
mpg 데이터의 hwy 변수로 상자 그림을 만들어 본다. seaborn 패키지의 boxplot()을 이용하면 된다.
mpg = pd.read_csv('mpg.csv')
import seaborn as sns
plt.figure(figsize=(20, 20)) # figure size 조정
sns.boxplot(data=mpg, y='hwy') # mpg 데이터셋의 'hwy' 변수로 상자 그림을 그림
plt.yticks(list(range(12, 50))) # y 축 눈금선을 바꿈
plt.show()

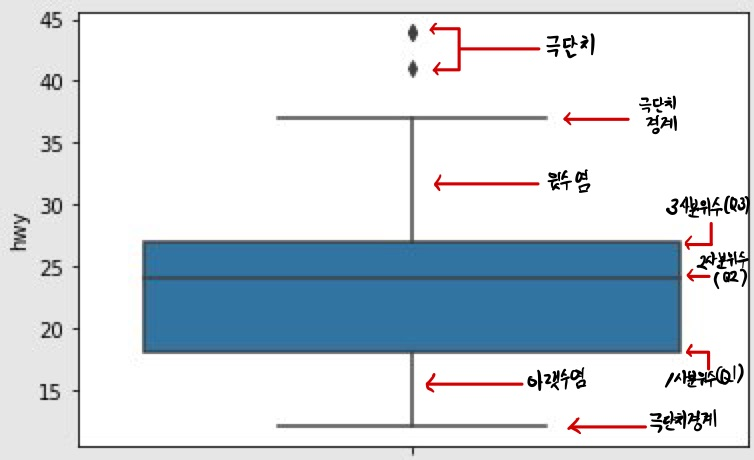
상자 그림은 값을 크기순으로 나열해 4등분 했을 때 위치하는 값인 ‘사분위수’를 이용해 만든다. 다음은 상자 그림의 요소가 나타내는 값이다.
| 상자 그림 | 값 | 설명 |
|---|---|---|
| 상자 아래 세로선 | 아랫수염 | 하위 0 ~ 25% 내에 해당하는 값 |
| 상자 밑면 | 1사분위수(Q1) | 하위 25% 위치 값 |
| 상자 내 굵은 선 | 2사분위수(Q2) | 하위 50% 위치 값(중앙값) |
| 상자 윗면 | 3사분위수(Q3) | 하위 75% 위치 값 |
| 상자 위 세로선 | 윗수염 | 하위 75 ~ 100% 내에 해당하는 값 |
| 상자 밖 가로선 | 극단치 경계 | Q1, Q3 밖 1.5 IQR 내 최대값 |
| 상자 밖 점 표식 | 극단치 | Q1, Q3 밖 1.5 IQR을 벗어난 값 |
‘IQR(사분위 범위)’은 1사분위수와 3사분위수의 거리를 뜻하고, ‘1.5 IQR’은 IQR의 1.5배를 뜻한다.
앞에서 출력한 상자 그림을 보면 hwy 값을 크기순으로 나열했을 때 하위 25% 지점에 18, 중앙에 24, 75% 지점에 27이 위치한다는 것을 알 수 있다. 직사각형 밖에 있는 아래, 위 가로선을 보면 12~37을 벗어난 값이 극단치로 분류된다는 것을 알 수 있다. 가로선 밖에 표현된 점 표식은 극단치를 의미한다.
극단치 기준값 구하기
quantile()을 이용하면 분위수quantile를 구할 수 있다. 하위 25%에 해당하는 1사분위수와 75%에 해당하는 3사분위수를 구한다.
pct25 = mpg['hwy'].quantile(.25)
print('1사분위수:', pct25)
1사분위수: 18.0
pct75 = mpg['hwy'].quantile(.75)
print('3사분위수:', pct75)
3사분위수: 27.0
앞에서 구한 pct25와 pct75를 이용해 1사분위수와 3사분위수의 거리를 나타낸 IQR(Inter Quartile Range, 사분위 범위)을 구한다.
iqr = pct75 - pct25
print('IQR:', iqr)
IQR: 9.0
이제 극단치의 경계가 되는 하한과 상한을 구한다.
-
하한: 1사분위수보다 ‘IQR의 1.5배’만큼 더 작은 값
-
상한: 3사분위수보다 ‘IQR의 1.5배’만큼 더 큰 값
다음 코드의 출력 결과를 보면 hwy가 4.5보다 작거나 40.5보다 크면 상자 그림 기준으로 극단치라는 것을 알 수 있다.
lower_limit = pct25 - 1.5 * iqr # 하한
print('하한:', lower_limit)
하한: 4.5
upper_limit = pct75 + 1.5 * iqr # 상한
print('상한:', upper_limit)
상한: 40.5
극단치를 결측 처리하기
상자 그림의 극단치 기준값을 구했으니 np.where()를 이용해 기준값을 벗어나면 결측 처리를 한다. np.where()에 여러 조건을 입력할 때는 각 조건을 괄호로 감싸야 하니 주의하도록 한다.
# 4.5 ~ 40.5 벗어나면 NaN 부여
mpg['hwy'] = np.where((mpg['hwy'] < lower_limit) | (mpg['hwy'] > upper_limit),
NA, mpg['hwy'])
# 결측치 빈도 확인
mpg['hwy'].isna().sum()
3
결측치 제거하고 분석하기
극단치를 결측 처리했으니 분석하기 전에 결측치를 제거하면 된다. drv(구동 방식)에 따라 hwy(고속도로 연비) 평균이 어떻게 다른지 알아보겠다.
mpg.dropna(subset=['hwy']) \ # hwy 결측치 제거
.groupby('drv') \ # drv별 분리
.agg(mean_hwy=('hwy', 'mean')) # hwy 평균 구하기
| mean_hwy | |
|---|---|
| drv | |
| 4 | 19.174757 |
| f | 27.728155 |
| r | 21.000000 |
데이터 변형
중복 제거하기
데이터프레임에서 각 행은 분석 대상이 갖고 있는 모든 속성(변수)에 대한 관측값(레코드)을 뜻한다. 하나의 데이터셋에서 동일한 관측값이 2개 이상 중복되는 경우 중복 데이터를 찾아서 삭제해야 한다. 동일한 대상이 중복으로 존재하는 것이므로 분석 결과를 왜곡하기 때문이다.
여러 가지 이유로 데이터프레임에서 중복된 로우를 발견할 수 있다. 그 이유는 사람의 실수 때문일 수도 있고, 어플의 버그일 수도 있고, 외부 소스에서 데이터를 추출하고 합칠 때 발생하게 된 깔끔하지 못한 데이터 때문일 수도 있다.1
data = pd.DataFrame({'k1': ['one', 'two'] * 3 + ['two'],
'k2': [1, 1, 2, 3, 3, 4, 4]})
data
| k1 | k2 | |
|---|---|---|
| 0 | one | 1 |
| 1 | two | 1 |
| 2 | one | 2 |
| 3 | two | 3 |
| 4 | one | 3 |
| 5 | two | 4 |
| 6 | two | 4 |
데이터프레임의 duplicated() 메서드는 각 로우가 중복인지 아닌지 알려주는 불리언 시리즈를 반환한다. 즉 전에 나온 행들과 비교하여 중복되는 행이면 True를 반환하고, 처음 나오는 행에 대해서는 False를 반환한다. 데이터프레임에 duplicated() 메서드를 적용하면 각 행의 중복 여부를 나타내는 불리언 시리즈를 반환한다.
data.duplicated()
0 False 1 False 2 False 3 False 4 False 5 False 6 True dtype: bool
drop_duplicates()는 중복되는 행을 제거하고 고유한 관측값을 가진 행들만 남긴다. 즉 duplicated 배열이 False인 데이터프레임을 반환한다. 원본 객체를 변경하려면 inplace=True 옵션을 추가한다.
data.drop_duplicates()
| k1 | k2 | |
|---|---|---|
| 0 | one | 1 |
| 1 | two | 1 |
| 2 | one | 2 |
| 3 | two | 3 |
| 4 | one | 3 |
| 5 | two | 4 |
이 두 메서드는 기본적으로 모든 칼럼에 적용되며 중복을 찾아내기 위한 부분합을 따로 지정해줄 수도 있다. subset 옵션에 ‘열 이름의 리스트’를 전달하는 것인데, 이는 데이터의 중복 여부를 판별할 때, subset 옵션에 전달한 인자를 기준으로 판단한다. 새로운 칼럼을 하나 추가하고 ‘k1’ 칼럼에 기반해서 중복을 걸러내려면 다음과 같이 한다.
data['v1'] = range(7)
print(data)
print('\n')
print(data.drop_duplicates(['k1']))
k1 k2 v1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
5 two 4 5
6 two 4 6
k1 k2 v1
0 one 1 0
1 two 1 1
duplicated()와 drop_duplicates()는 기본적으로 처음 발견된 값을 유지한다. keep=’last’ 옵션을 넘기면 마지막으로 발견된 값을 반환한다.
data.drop_duplicates(['k1', 'k2'], keep='last') # 원본 데이터프레임 인덱스의 5에 해당하는 데이터 삭제
| k1 | k2 | v1 | |
|---|---|---|---|
| 0 | one | 1 | 0 |
| 1 | two | 1 | 1 |
| 2 | one | 2 | 2 |
| 3 | two | 3 | 3 |
| 4 | one | 3 | 4 |
| 6 | two | 4 | 6 |
함수나 매핑을 이용해서 데이터 변형하기
데이터프레임에 함수를 매핑하는 방법, 데이터를 집계하는 그룹 연산, 데이터프레임을 합치거나 다양한 형태로 구조를 변경하는 방법 등에 관해 차례대로 살펴보자.
함수 매핑은 시리즈 또는 데이터프레임의 개별 원소를 특정 함수에 일대일 대응시키는 과정을 뜻한다. 사용자가 직접 만든 함수(lambda 함수 포함)를 적용할 수 있기 때문에 판다스 기본 함수로 처리하기 어려운 복잡한 연산을 데이터프레임 등 판다스 객체에 적용하는 것이 가능하다.
기본적으로 판다스 객체에도 넘파이의 유니버셜 함수(배열의 각 원소에 적용되는 메서드)를 적용할 수 있다.
frame = pd.DataFrame(np.random.randn(4, 3), columns=list('bde'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])
frame
| b | d | e | |
|---|---|---|---|
| Utah | 0.405010 | 0.021343 | -0.943314 |
| Ohio | 2.289276 | 0.329260 | -0.196781 |
| Texas | -0.298920 | -0.646138 | -0.728597 |
| Oregon | -1.123270 | 1.100850 | 0.607144 |
# 절대값을 구하는 np.abs() 함수
np.abs(frame)
| b | d | e | |
|---|---|---|---|
| Utah | 0.405010 | 0.021343 | 0.943314 |
| Ohio | 2.289276 | 0.329260 | 0.196781 |
| Texas | 0.298920 | 0.646138 | 0.728597 |
| Oregon | 1.123270 | 1.100850 | 0.607144 |
개별 원소에 함수 매핑
시리즈 원소에 함수 매핑
시리즈 객체에 apply() 메서드를 적용하면 인자로 전달하는 매핑 함수에 시리즈의 모든 원소를 하나씩 입력하고 함수의 리턴값을 돌려받는다. 시리즈 원소의 개수만큼 리턴값을 받아서 같은 크기의 시리즈 객체로 반환한다.
data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon',
'Pastrami', 'corned beef', 'Bacon',
'pastrami', 'honey ham', 'nova lox'],
'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
data['ten'] = 10
data
| food | ounces | ten | |
|---|---|---|---|
| 0 | bacon | 4.0 | 10 |
| 1 | pulled pork | 3.0 | 10 |
| 2 | bacon | 12.0 | 10 |
| 3 | Pastrami | 6.0 | 10 |
| 4 | corned beef | 7.5 | 10 |
| 5 | Bacon | 8.0 | 10 |
| 6 | pastrami | 3.0 | 10 |
| 7 | honey ham | 5.0 | 10 |
| 8 | nova lox | 6.0 | 10 |
다음으로 두 가지 사용자 함수를 정의한다. 임의의 객체 n에 숫자 10을 더하는 add_10(n) 함수와, 객체 a와 b를 더하는 add_two_obj(a, b) 함수이다. 두 함수를 다음과 같이 실행하는 경우 숫자 10을 두 번 더한 값인 20을 출력하는 점에서 같은 결과를 얻는다.
# 사용자 함수 정의
def add_10(n): # 10을 더하는 함수
return n + 10
def add_two_obj(a, b): # 두 객체의 합
return a + b
print(add_10(10))
print(add_two_obj(10, 10))
20 20
apply() 메서드를 이용하여 data[‘ounces’] 열에 add_10 함수를 매핑하면 모든 원소에 숫자 10을 더한다. 이 결과를 변수 rs1에 저장한다. 다음으로 add_two_obj 함수를 data[‘ounces’] 열에 매핑하면 함께 전달된 숫자 10을 모든 원소에 더하는데, 결과를 변수 rs2에 저장한다. 마지막으로 lambda 함수를 data[‘ounces’] 열에 매핑하여 add_10 함수의 리턴값을 rs3에 저장한다.
3가지 케이스 모두 ‘ounces’ 열의 각 원소에 10을 더한 값을 가진 같은 크기의 시리즈가 된다. 또한 열의 이름인 ‘ounces’가 시리즈 객체의 이름으로 유지되는 것을 확인할 수 있다.
# 시리즈 객체에 적용
rs1 = data['ounces'].apply(add_10) # n = data['ounces']의 모든 원소
print(rs1)
print('\n')
# 시리즈 객체와 숫자에 적용: 2개의 인수(시리즈 + 숫자)
rs2 = data['ounces'].apply(add_two_obj, b=10) # a = data['ounces']의 모든 원소, b = 10
print(rs2)
print('\n')
# lambda 함수 활용: 시리즈 객체에 적용
rs3 = data['ounces'].apply(lambda x: add_10(x)) # x = data['ounces']
print(rs3)
0 14.0 1 13.0 2 22.0 3 16.0 4 17.5 5 18.0 6 13.0 7 15.0 8 16.0 Name: ounces, dtype: float64 0 14.0 1 13.0 2 22.0 3 16.0 4 17.5 5 18.0 6 13.0 7 15.0 8 16.0 Name: ounces, dtype: float64 0 14.0 1 13.0 2 22.0 3 16.0 4 17.5 5 18.0 6 13.0 7 15.0 8 16.0 Name: ounces, dtype: float64
그리고 해당 육류가 어떤 동물의 고기인지 알려줄 수 있는 칼럼을 하나 추가한다고 가정하고 육류별 동물을 담고 있는 딕셔너리 데이터를 아래처럼 작성했다.
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}
meat_to_animal
{'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'}
시리즈의 map()메서드는 사전류의 객체나 어떤 함수를 받을 수 있는데, 위 데이터에는 육류 이름에 대소문자가 섞여 있는 사소한 문제가 있으므로 str.lower() 메서드를 사용해서 모두 소문자로 변경한다.
lowercased = data['food'].str.lower()
lowercased # index 3의 'pastrami' 확인
0 bacon 1 pulled pork 2 bacon 3 pastrami 4 corned beef 5 bacon 6 pastrami 7 honey ham 8 nova lox Name: food, dtype: object
data['animal'] = lowercased.map(meat_to_animal)
data
| food | ounces | animal | |
|---|---|---|---|
| 0 | bacon | 4.0 | pig |
| 1 | pulled pork | 3.0 | pig |
| 2 | bacon | 12.0 | pig |
| 3 | Pastrami | 6.0 | cow |
| 4 | corned beef | 7.5 | cow |
| 5 | Bacon | 8.0 | pig |
| 6 | pastrami | 3.0 | cow |
| 7 | honey ham | 5.0 | pig |
| 8 | nova lox | 6.0 | salmon |
물론 함수를 넘겨서 같은 일을 수행할 수도 있다.
data['food'].map(lambda x: meat_to_animal[x.lower()])
0 pig 1 pig 2 pig 3 cow 4 cow 5 pig 6 cow 7 pig 8 salmon Name: food, dtype: object
map() 메서드를 사용하면 데이터의 요소별 변환 및 데이터를 다듬는 작업을 편리하게 수행할 수 있다. 하지만 인덱스에 따라 값을 전환하는 기능이므로 데이터프레임에서는 사용할 수 없고 시리즈에서만 사용할 수 있다.
데이터프레임 원소에 함수 매핑
데이터프레임의 개별 원소에 특정 함수를 매핑하려면, applymap() 메서드를 활용한다. 매핑 함수에 데이터프레임의 각 원소를 하나씩 넣어서 리턴값으로 돌려받는다. 원소의 원래 위치에 매핑 함수의 리턴값을 입력하여 동일한 형태의 데이터프레임이 만들어진다.
df = data.loc[:, ['ounces', 'ten']]
print(df)
print('\n')
# 사용자 정의 함수
def add_10(n): # 10을 더하는 함수
return n + 10
# 데이터프레임에 applymap()으로 add_10() 함수를 매핑 적용
df_map = df.applymap(add_10)
print(df_map)
ounces ten 0 4.0 10 1 3.0 10 2 12.0 10 3 6.0 10 4 7.5 10 5 8.0 10 6 3.0 10 7 5.0 10 8 6.0 10 ounces ten 0 14.0 20 1 13.0 20 2 22.0 20 3 16.0 20 4 17.5 20 5 18.0 20 6 13.0 20 7 15.0 20 8 16.0 20
참고로 이 메서드의 이름이 applymap()인 이유는 앞서 말했듯이 시리즈는 각 원소에 적용할 함수를 지정하기 위한 map() 메서드를 가지고 있기 때문이다.
df['ten'].map(lambda x: '%.2f' % x)
0 10.00 1 10.00 2 10.00 3 10.00 4 10.00 5 10.00 6 10.00 7 10.00 8 10.00 Name: ten, dtype: object
시리즈 객체에 함수 매핑
데이터프레임의 각 열에 함수 매핑
데이터프레임에 apply(axis=0) 메서드를 적용하면 모든 열을 하나씩 분리하여 매핑 함수의 인자로 각 열(시리즈)이 전달된다. 매핑 함수에 따라 반환되는 객체의 종류가 다르다.
시리즈를 입력받고 시리즈를 반환하는 함수를 매핑하면, 데이터프레임을 반환한다. 예제에서는 시리즈를 입력받아서 시리즈를 반환하는 missing_value(series) 함수를 정의하여 사용한다. 데이터프레임의 열을 매핑 함수에 전달하면 각 열의 리턴값은 시리즈 형태로 반환되고, 이들 시리즈가 하나의 데이터프레임으로 통합되는 과정을 거친다.
print(df)
print('\n')
# 사용자 함수 정의
def missing_value(series): # 시리즈를 인자로 전달
return series.isnull() # 불린 시리즈를 반환
# 데이터프레임의 각 열을 인자로 전달하면 데이터프레임을 반환
result = df.apply(missing_value, axis=0)
print(result)
print('\n')
print(type(result))
ounces ten 0 4.0 10 1 3.0 10 2 12.0 10 3 6.0 10 4 7.5 10 5 8.0 10 6 3.0 10 7 5.0 10 8 6.0 10 ounces ten 0 False False 1 False False 2 False False 3 False False 4 False False 5 False False 6 False False 7 False False 8 False False <class 'pandas.core.frame.DataFrame'>
한편 시리즈를 입력받아서 하나의 값을 반환하는 함수를 매핑하면 시리즈를 반환한다. 예제에서 시리즈의 최대값과 최소값의 차이를 계산하여 값을 반환하는 min_ax(x) 함수를 정의해서 사용한다. 데이터프레임의 각 열을 매핑 함수에 전달하면 각 열의 리턴값은 하나의 값으로 반한된다. 마지막으로 이들 값을 하나의 시리즈로 통합하는 과정을 거친다.
이때 각 열의 이름이 시리즈의 인덱스가 되고, 함수가 반환하는 값이 각 인덱스에 매칭되는 데이터 값이 된다. axis=0 옵션의 경우 따로 설정하지 않아도 apply() 함수에서 기본 적용된다.
print(df)
print('\n')
# 사용자 함수 정의
def min_max(x): # 최대값 - 최소값
return x.max() - x.min()
# 데이터프레임의 각 열을 인자로 전달하면 시리즈를 반환
result = df.apply(min_max) # 기본값 axis=0, axis='rows'
print(result)
print('\n')
print(type(result))
ounces ten 0 4.0 10 1 3.0 10 2 12.0 10 3 6.0 10 4 7.5 10 5 8.0 10 6 3.0 10 7 5.0 10 8 6.0 10 ounces 9.0 ten 0.0 dtype: float64 <class 'pandas.core.series.Series'>
apply() 메서드에 전달된 함수는 스칼라값을 반환할 필요가 없다. 여러 값을 가진 시리즈를 반환해도 된다.
def f(x):
return pd.Series([x.min(), x.max()], index=['min', 'max'])
print(df)
print('\n')
print(df.apply(f))
ounces ten
0 4.0 10
1 3.0 10
2 12.0 10
3 6.0 10
4 7.5 10
5 8.0 10
6 3.0 10
7 5.0 10
8 6.0 10
ounces ten
min 3.0 10
max 12.0 10
데이터프레임의 각 행에 함수 매핑
데이터프레임 객체에 apply(axis=1) 메서드를 적용하면 데이터프레임의 각 행을 매핑 함수의 인자로 전달한다. 데이터프레임의 행 인덱스가 매핑 결과로 반환되는 시리즈의 인덱스가 된다. 시리즈의 인덱스에 매칭되는 데이터 값에는 각 행의 데이터를 함수에 적용한 리턴값을 가져온다.
앞에서 정의한 add_two_obj(a, b) 함수를 활용한다. 두 객체를 인자로 받아서 덧셈(+) 연산자를 적용하고 결과를 반환하는 함수이다. apply(axis=1) 메서드를 이용하여 데이터프레임에 함수를 매핑하는데, add_two_obj 함수가 필요한 두 인자로는 df의 2개 열(‘ounces’, ‘ten’)을 지정한다. 데이터프레임의 모든 행에 대하여 두 열의 값을 더해서 반환한다.
print(df)
print('\n')
# 사용자 함수 정의
def add_two_obj(a, b): # 두 객체의 합
return a + b
# 데이터프레임의 2개 열을 선택하여 적용
# x=df, a=df['ounces'], b=df['ten']
df['add'] = df.apply(lambda x: add_two_obj(x['ounces'], x['ten']), axis=1)
print(df)
ounces ten 0 4.0 10 1 3.0 10 2 12.0 10 3 6.0 10 4 7.5 10 5 8.0 10 6 3.0 10 7 5.0 10 8 6.0 10 ounces ten add 0 4.0 10 14.0 1 3.0 10 13.0 2 12.0 10 22.0 3 6.0 10 16.0 4 7.5 10 17.5 5 8.0 10 18.0 6 3.0 10 13.0 7 5.0 10 15.0 8 6.0 10 16.0
데이터프레임 객체에 함수 매핑
데이터프레임 객체를 함수에 매핑하려면 pipe() 메서드를 활용한다. 이때 사용하는 함수가 반환하는 리턴값에 따라 pipe() 메서드가 반환하는 객체의 종류가 결정된다. 데이터프레임을 반환하는 경우, 시리즈를 반환하는 경우, 개별 값을 반환하는 경우로 나눌 수 있다.
# 각 열의 NaN 찾기 - 데이터프레임 전달하면 데이터프레임 반환
def missing_value(x):
return x.isnull()
# 각 열의 NaN 개수 반환 - 데이터프레임 전달하면 시리즈 반환
def missing_count(x):
return missing_value(x).sum()
# 데이터프레임의 총 NaN 개수 - 데이터프레임 전달하면 값 반환
def total_number_missing(x):
return missing_count(x).sum()
df.iloc[[0, 1, 3, 6], [0]] = NA
df.iloc[[2, 5, 8], [2]] = NA
print(df)
ounces ten add 0 NaN 10 14.0 1 NaN 10 13.0 2 12.0 10 NaN 3 NaN 10 16.0 4 7.5 10 17.5 5 8.0 10 NaN 6 NaN 10 13.0 7 5.0 10 15.0 8 6.0 10 NaN
첫 번째 pipe() 메서드가 데이터프레임을 반환하는 케이스부터 살펴보자. missing_value(x) 함수는 데이터프레임을 입력받으면 isnull() 메서드를 이용하여 데이터프레임의 각 원소에서 누락 데이터(NaN) 여부를 True 또는 False로 표시하고, 그 결과를 데이터프레임으로 반환한다.
# 데이터프레임에 pipe() 메서드로 함수 매핑
result_df = df.pipe(missing_value)
print(result_df)
print(type(result_df))
ounces ten add 0 True False False 1 True False False 2 False False True 3 True False False 4 False False False 5 False False True 6 True False False 7 False False False 8 False False True <class 'pandas.core.frame.DataFrame'>
두 번째 pipe() 메서드가 시리즈를 반환하는 케이스를 살펴보자. missing_count(x) 함수는 데이터프레임을 입력받으면 각 열의 누락 데이터 개수를 시리즈 형태로 반환한다.
result_series = df.pipe(missing_count)
print(result_series)
print(type(result_series))
ounces 4 ten 0 add 3 dtype: int64 <class 'pandas.core.series.Series'>
세 번째 pipe() 메서드가 하나의 값을 반환하는 케이스를 보자. total_number_missing(x) 함수는 데이터프레임을 입력받으면 각 열의 누락 데이터(NaN)의 개수를 합산하여 반환한다.
result_value = df.pipe(total_number_missing)
print(result_value)
print('\n')
7
값 치환하기
fillna() 메서드를 사용해서 누락된 값을 채우는 일은 일반적인 값 치환 작업이라고 볼 수 있다. 위에서 살펴봤듯이 map() 메서드를 한 객체 안에서 값의 부분집합을 변경하는데 사용했다면 replace() 메서드는 같은 작업에 대해 좀 더 간단하고 유연한 방법을 제공한다.
data = pd.Series([1., -999., 2., -999., -1000., 3.])
data
0 1.0 1 -999.0 2 2.0 3 -999.0 4 -1000.0 5 3.0 dtype: float64
-999는 누락된 데이터를 나타낸 값이다. replace() 메서드를 이용하면 이 값을 판다스에서 인식할 수 있는 NA 값으로 치환한 새로운 시리즈를 생성할 수 있다.
data.replace(-999, NA)
0 1.0 1 NaN 2 2.0 3 NaN 4 -1000.0 5 3.0 dtype: float64
여러 개의 값을 한 번에 치환하려면 하나의 값 대신 치환하려는 값의 리스트를 넘기면 된다.
data.replace([-999, -1000], NA)
0 1.0 1 NaN 2 2.0 3 NaN 4 NaN 5 3.0 dtype: float64
치환하려는 값마다 다른 값으로 치환하려면 누락된 값 대신 새로 지정할 값의 리스트를 사용하면 된다.
data.replace([-999, -1000], [NA, 0])
0 1.0 1 NaN 2 2.0 3 NaN 4 0.0 5 3.0 dtype: float64
두 개의 리스트 대신 사전을 이용하는 것도 가능하다.
data.replace({-999: NA, -1000: 0})
0 1.0 1 NaN 2 2.0 3 NaN 4 0.0 5 3.0 dtype: float64
축 인덱스 이름 바꾸기
데이터의 전반적인 특징을 파악하고 나면 본격적으로 분석하기 전에 변수명을 수정하는 작업을 해야 한다. 변수명을 이해하기 쉬운 단어로 바꾸면 데이터를 수월하게 다룰 수 있다. 특히 변수명이 기억하기 어려운 문자로 되어 있으면 쉬운 단어로 바꾸는 게 좋다.
시리즈의 값들처럼 축 이름 역시 유사한 방식으로 함수나 새롭게 바꿀 값을 이용해서 변환할 수 있다. 새로운 자료구조를 만들지 않고 그 자리에서 바로 축 이름을 변경하는 것이 가능하다.
data = pd.DataFrame(np.arange(12).reshape((3, 4)),
index=['Ohio', 'Colorado', 'New York'],
columns=['one', 'two', 'three', 'four'])
data
| one | two | three | four | |
|---|---|---|---|---|
| Ohio | 0 | 1 | 2 | 3 |
| Colorado | 4 | 5 | 6 | 7 |
| New York | 8 | 9 | 10 | 11 |
시리즈와 마찬가지로 축 인덱스에도 map() 메서드가 있다.
transform = lambda x: x[:4].upper()
data.index.map(transform)
Index(['OHIO', 'COLO', 'NEW '], dtype='object')
대문자로 변경된 축 이름을 데이터프레임의 index에 바로 대입할 수 있다.
data.index = data.index.map(transform)
data
| one | two | three | four | |
|---|---|---|---|---|
| OHIO | 0 | 1 | 2 | 3 |
| COLO | 4 | 5 | 6 | 7 |
| NEW | 8 | 9 | 10 | 11 |
원래 객체를 변경하지 않고 새로운 객체를 생성하려면 rename() 메서드를 사용한다.
data.rename(index=str.title, columns=str.upper) # str.title: 첫글자만 대문자, str.upper: 모두 대문자
| ONE | TWO | THREE | FOUR | |
|---|---|---|---|---|
| Ohio | 0 | 1 | 2 | 3 |
| Colo | 4 | 5 | 6 | 7 |
| New | 8 | 9 | 10 | 11 |
특히 rename() 메서드는 사전 형식의 객체를 이용해서 축 이름 중 일부만 변경하는 것도 가능하다.
data.rename(index={'OHIO': 'INDIANA'},
columns={'three': 'peekaboo'})
| one | two | peekaboo | four | |
|---|---|---|---|---|
| INDIANA | 0 | 1 | 2 | 3 |
| COLO | 4 | 5 | 6 | 7 |
| NEW | 8 | 9 | 10 | 11 |
rename() 메서드를 사용하면 데이터프레임을 직접 복사해서 index와 columns 속성을 갱신할 필요 없이 바로 변경할 수 있다. 원본 데이터를 바로 변경하려면 inplace=True 옵션을 넘겨주면 된다.
data.rename(index={'OHIO': 'INDIANA'}, inplace=True)
data
| one | two | three | four | |
|---|---|---|---|---|
| INDIANA | 0 | 1 | 2 | 3 |
| COLO | 4 | 5 | 6 | 7 |
| NEW | 8 | 9 | 10 | 11 |
개별화와 양자화
데이터 분석 알고리즘에 따라서는 연속 데이터를 그대로 사용하기 보다는 일정한 구간(bin)으로 나눠서 분석하는 것이 효율적인 경우가 있다. 가격, 비용, 효율 등 연속적인 값을 일정한 수준이나 정도를 나타내는 이산적인 값으로 나타내어 구간별 차이를 드러내는 것이다.
이처럼 연속 변수를 일정한 구간으로 나누고, 각 구간을 범주형 이산 변수로 변환하는 과정을 구간 분할(binning)이라고 한다. 판다스 cut() 함수를 이용하면 연속 데이터를 여러 구간으로 나누고 범주형 데이터로 변환할 수 있다. 예시로 수업에 참여하는 학생 그룹 데이터가 있고, 나이대에 따라 분류한다고 가정하자.
ages = [20, 22, 25, 27, 21, 23, 37, 31, 64, 45, 41, 32]
이 데이터를 판다스의 cut() 함수를 이용해서 18-25, 26-35, 35-60, 60 이상 그룹으로 나누어보자.
bins = [18, 25, 35, 60, 100]
cats = pd.cut(ages, bins)
cats
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35, 60], (35, 60], (25, 35]] Length: 12 Categories (4, interval[int64, right]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
판다스에서 반환하는 객체는 Categorical이라는 특수한 객체다. 결과에서 보이는 그룹은 cut()으로 계산된 것이다. 이 객체는 그룹 이름이 담긴 배열이라고 생각하면 된다. 이 Categorical 객체는 codes 속성에 있는 ages 데이터에 대한 카테고리 이름을 categories라는 배열에 내부적으로 담고 있다. 즉 codes 속성 배열 내부에 있는 정수형 데이터는 categories의 배열이 나타내는 각 데이터의 범위에 해당하는 숫자다.
cats.codes
array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8)
cats.categories
IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]], dtype='interval[int64, right]')
pd.value_counts(cats)
(18, 25] 5 (25, 35] 3 (35, 60] 3 (60, 100] 1 dtype: int64
pd.value_counts(cats)는 pandas.cut() 결과에 대한 그룹 수다.
간격을 나타내는 표기법은 소괄호로 시작해서 대괄호로 끝나는데 소괄호 쪽의 값은 포함하지 않고개구간 대괄호 쪽의 값은 포함폐구간하는 간격을 나타낸다. right=False를 넘겨서 소괄호 대신 대괄호 쪽이 포함되지 않도록 바꿀 수 있다.
pd.cut(ages, [18, 26, 36, 61, 100], right=False)
[[18, 26), [18, 26), [18, 26), [26, 36), [18, 26), ..., [26, 36), [61, 100), [36, 61), [36, 61), [26, 36)] Length: 12 Categories (4, interval[int64, left]): [[18, 26) < [26, 36) < [36, 61) < [61, 100)]
labels 옵션으로 그룹의 이름을 직접 넘겨줄 수도 있다.
group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
pd.cut(ages, bins, labels=group_names)
['Youth', 'Youth', 'Youth', 'YoungAdult', 'Youth', ..., 'YoungAdult', 'Senior', 'MiddleAged', 'MiddleAged', 'YoungAdult'] Length: 12 Categories (4, object): ['Youth' < 'YoungAdult' < 'MiddleAged' < 'Senior']
만약 cut() 함수에 명시적으로 그룹의 경곗값을 넘기지 않고 그룹의 개수를 넘겨주면 데이터에서 최솟값과 최댓값을 기준으로 균등한 길이의 그룹을 자동으로 계산한다. 어떤 균등분포 내에서 4개의 그룹으로 나누는 경우를 생각해보자.
data = np.random.rand(20)
pd.cut(data, 4, precision=2) # precision=2 옵션은 소수점 아래 2자리까지로 제한한다.
[(0.64, 0.83], (0.45, 0.64], (0.073, 0.26], (0.64, 0.83], (0.64, 0.83], ..., (0.26, 0.45], (0.073, 0.26], (0.073, 0.26], (0.26, 0.45], (0.64, 0.83]] Length: 20 Categories (4, interval[float64, right]): [(0.073, 0.26] < (0.26, 0.45] < (0.45, 0.64] < (0.64, 0.83]]
이를 위한 가장 적합한 함수로 qcut()이 있는데 표본 변위치(분위수)를 기반으로 데이터를 나눠준다. cut() 함수를 사용하면 데이터의 분산에 따라 각각의 그룹마다 데이터의 수가 다르게 나뉘는 경우가 많은데 qcut()은 표준 변위치를 사용하기 때문에 적당히 같은 크기의 그룹으로 나눌 수 있다.
data = np.random.randn(1000) # 정규 분포
cats = pd.qcut(data, 4) # 4분위로 분류
cats
[(-0.0385, 0.709], (-0.672, -0.0385], (0.709, 3.185], (0.709, 3.185], (0.709, 3.185], ..., (-0.672, -0.0385], (-3.4779999999999998, -0.672], (0.709, 3.185], (0.709, 3.185], (-3.4779999999999998, -0.672]] Length: 1000 Categories (4, interval[float64, right]): [(-3.4779999999999998, -0.672] < (-0.672, -0.0385] < (-0.0385, 0.709] < (0.709, 3.185]]
pd.value_counts(cats)
(-3.4779999999999998, -0.672] 250 (-0.672, -0.0385] 250 (-0.0385, 0.709] 250 (0.709, 3.185] 250 dtype: int64
cut() 함수와 유사하게 변위치를 직접 지정해줄 수 있다(변위치는 0부터 1까지다).
cats = pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.])
cats
[(-0.0385, 1.332], (-1.339, -0.0385], (1.332, 3.185], (-0.0385, 1.332], (-0.0385, 1.332], ..., (-1.339, -0.0385], (-3.4779999999999998, -1.339], (1.332, 3.185], (1.332, 3.185], (-1.339, -0.0385]] Length: 1000 Categories (4, interval[float64, right]): [(-3.4779999999999998, -1.339] < (-1.339, -0.0385] < (-0.0385, 1.332] < (1.332, 3.185]]
pd.value_counts(cats)
(-1.339, -0.0385] 400 (-0.0385, 1.332] 400 (-3.4779999999999998, -1.339] 100 (1.332, 3.185] 100 dtype: int64
정리하자면 cut()은 동일한 길이로 나누는 것이고, qcut()은 동일한 개수로 나누는 것이다.
치환과 임의 샘플링
numpy.random.permutation() 함수를 이용하면 시리즈나 데이터프레임의 로우를 쉽게 임의 순서로 재배치할 수 있다. 순서를 바꾸고 싶은 만큼의 길이를 permutation() 함수로 넘기면 바뀐 순서가 담긴 정수 배열이 생성된다.
df = pd.DataFrame(np.arange(5 * 4).reshape((5, 4)))
sampler = np.random.permutation(5)
sampler
array([0, 2, 4, 1, 3])
이 배열은 iloc 기반의 인덱싱이나 take() 함수에서 사용 가능하다.
df
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
| 3 | 12 | 13 | 14 | 15 |
| 4 | 16 | 17 | 18 | 19 |
df.take(sampler)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 2 | 8 | 9 | 10 | 11 |
| 4 | 16 | 17 | 18 | 19 |
| 1 | 4 | 5 | 6 | 7 |
| 3 | 12 | 13 | 14 | 15 |
치환 없이 일부만 임의로 선택하려면 시리즈나 데이터프레임의 sample() 메서드를 사용하면 된다.
df.sample(n=3)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 4 | 16 | 17 | 18 | 19 |
| 2 | 8 | 9 | 10 | 11 |
(반복 선택을 허용하며) 표본을 치환을 통해 생성해내려면 sample()에 replace=True 옵션을 넘긴다.
choices = pd.Series([5, 7, -1, 6, 4])
draws = choices.sample(n=10, replace=True)
draws
1 7 4 4 0 5 2 -1 1 7 2 -1 3 6 1 7 1 7 3 6 dtype: int64
표시자/더미 변수 계산하기
카테고리를 나타내는 범주형 데이터를 회귀분석 등 머신러닝 알고리즘에 바로 사용할 수 없는 경우가 있는데, 이를 컴퓨터가 인식 가능한 입력값으로 변환해야 한다. 즉 통계 모델이나 머신러닝 애플리케이션을 위한 또 다른 데이터 변환은 분류값을 숫자 0 또는 1로 표현되는 ‘더미’나 ‘표시자’ 행렬로 전환하는 것이다. 여기서 0과 1은 수의 크고 작음을 나타내지 않고, 어떤 특성이 있는지 없는지 여부만을 표시한다. 해당 특성이 존재하면 1로 표현하고, 존재하지 않으면 0으로 구분하는 개념이다.
이처럼 범주형 데이터를 컴퓨터가 인식할 수 있도록 숫자 0과 1로만 구성되는 원핫벡터(one hot vector)로 변환한다고 해서 원핫인코딩(one-hot-encoding)이라고도 부른다. 이를 위해 판다스는 get_dummies() 함수를 제공한다.
df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],
'data1': range(6)})
df
| key | data1 | |
|---|---|---|
| 0 | b | 0 |
| 1 | b | 1 |
| 2 | a | 2 |
| 3 | c | 3 |
| 4 | a | 4 |
| 5 | b | 5 |
pd.get_dummies(df['key'])
| a | b | c | |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 2 | 1 | 0 | 0 |
| 3 | 0 | 0 | 1 |
| 4 | 1 | 0 | 0 |
| 5 | 0 | 1 | 0 |
표시자 데이터프레임 안에 있는 칼럼에 접두어prefix를 추가한 후 다른 데이터와 병합하고 싶을 경우가 있다. get_dummies() 함수의 prefix 인자를 사용하면 이를 수행할 수 있다.
dummies = pd.get_dummies(df['key'], prefix='key')
df_with_dummy = df[['data1']].join(dummies)
df_with_dummy
| data1 | key_a | key_b | key_c | |
|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 | 0 |
| 2 | 2 | 1 | 0 | 0 |
| 3 | 3 | 0 | 0 | 1 |
| 4 | 4 | 1 | 0 | 0 |
| 5 | 5 | 0 | 1 | 0 |
만약 데이터프레임의 한 로우가 여러 카테고리에 속한다면 다음과 같은 방법을 사용해보자.
mnames = ['movie_d', 'title', 'genres']
movies = pd.read_table('datasets/movielens/movies.dat', sep='::',
header=None, names=mnames, engine='python')
movies[:10]
| movie_d | title | genres | |
|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Animation|Children's|Comedy |
| 1 | 2 | Jumanji (1995) | Adventure|Children's|Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
| 5 | 6 | Heat (1995) | Action|Crime|Thriller |
| 6 | 7 | Sabrina (1995) | Comedy|Romance |
| 7 | 8 | Tom and Huck (1995) | Adventure|Children's |
| 8 | 9 | Sudden Death (1995) | Action |
| 9 | 10 | GoldenEye (1995) | Action|Adventure|Thriller |
각 장르마다 표시자 값을 추가하려면 약간의 수고를 해야 하는데 먼저 데이터 묶음에서 유일한 장르 목록을 추출해야 한다.
all_genres = []
for x in movies.genres:
all_genres.extend(x.split('|'))
genres = pd.unique(all_genres)
genres
array(['Animation', "Children's", 'Comedy', 'Adventure', 'Fantasy',
'Romance', 'Drama', 'Action', 'Crime', 'Thriller', 'Horror',
'Sci-Fi', 'Documentary', 'War', 'Musical', 'Mystery', 'Film-Noir',
'Western'], dtype=object)
이제 표시자 데이터프레임을 생성하기 위해 0으로 초기화된 데이터프레임을 생성하자.
zero_matrix = np.zeros((len(movies), len(genres)))
dummies = pd.DataFrame(zero_matrix, columns=genres)
dummies
| Animation | Children's | Comedy | Adventure | Fantasy | Romance | Drama | Action | Crime | Thriller | Horror | Sci-Fi | Documentary | War | Musical | Mystery | Film-Noir | Western | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3878 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3879 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3880 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3881 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3882 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
3883 rows × 18 columns
각 영화를 순회하면서 dummies의 각 로우의 항목을 1로 설정한다. 각 장르의 칼럼 인덱스를 계산하기 위해 dummies.columns를 사용하자.
gen = movies.genres[0]
gen.split('|')
['Animation', "Children's", 'Comedy']
dummies.columns.get_indexer(gen.split('|'))
array([0, 1, 2], dtype=int64)
그리고 .iloc를 이용해서 인덱스에 맞게 값을 대입하자.
for i, gen in enumerate(movies.genres):
indices = dummies.columns.get_indexer(gen.split('|'))
dummies.iloc[i, indices] = 1
그리고 앞에서 한 것처럼 movies와 조합하면 된다.
movies_windic = movies.join(dummies.add_prefix('Genre_'))
movies_windic
| movie_d | title | genres | Genre_Animation | Genre_Children's | Genre_Comedy | Genre_Adventure | Genre_Fantasy | Genre_Romance | Genre_Drama | ... | Genre_Crime | Genre_Thriller | Genre_Horror | Genre_Sci-Fi | Genre_Documentary | Genre_War | Genre_Musical | Genre_Mystery | Genre_Film-Noir | Genre_Western | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Animation|Children's|Comedy | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 2 | Jumanji (1995) | Adventure|Children's|Fantasy | 0.0 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3878 | 3948 | Meet the Parents (2000) | Comedy | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3879 | 3949 | Requiem for a Dream (2000) | Drama | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3880 | 3950 | Tigerland (2000) | Drama | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3881 | 3951 | Two Family House (2000) | Drama | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3882 | 3952 | Contender, The (2000) | Drama|Thriller | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
3883 rows × 21 columns
이보다 더 큰 데이터라면 이 방법으로 다중 멤버십을 갖는 표시자 변수를 생성하는 것은 그다지 빠른 방법이 아니다. 속도를 높이려면 직접 NumPy 배열에 접근하는 저수준의 함수를 작성해서 데이터프레임에 결과를 저장하도록 해야 한다.
get_dummies()와 cut() 같은 이산함수를 잘 조합하면 통계 애플리케이션에서 유용하게 사용할 수 있다.
np.random.seed(12345)
values = np.random.rand(10)
values
array([0.92961609, 0.31637555, 0.18391881, 0.20456028, 0.56772503,
0.5955447 , 0.96451452, 0.6531771 , 0.74890664, 0.65356987])
bins = [0, 0.2, 0.4, 0.6, 0.8, 1]
pd.get_dummies(pd.cut(values, bins))
| (0.0, 0.2] | (0.2, 0.4] | (0.4, 0.6] | (0.6, 0.8] | (0.8, 1.0] | |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 | 0 |
| 5 | 0 | 0 | 1 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 1 |
| 7 | 0 | 0 | 0 | 1 | 0 |
| 8 | 0 | 0 | 0 | 1 | 0 |
| 9 | 0 | 0 | 0 | 1 | 0 |
문자열 다루기
파이썬은 문자열이나 텍스트 처리의 용이함 덕분에 원시 데이터를 처리하는 인기 있는 언어가 되었다. 대부분의 텍스트 연산은 문자열 객체의 내장 메서드로 간단하게 처리할 수 있다. 좀 더 복잡한 패턴 매칭이나 텍스트 조작은 정규 표현식을 필요로 한다. 판다스는 배열 데이터 전체에 쉽게 정규 표현식을 적용하고, 누락된 데이터를 편리하게 처리할 수 있는 기능을 포함하고 있다.
문자열 객체 메서드
문자열을 다뤄야 하는 대부분의 애플리케이션은 내장 문자열 메서드만으로도 충분하다. 예를 들어 쉼표로 구분된 문자열은 split() 메서드를 이용해서 분리할 수 있다.
val = 'a,b, guido'
val.split(',')
['a', 'b', ' guido']
split() 메서드는 종종 공백 문자(줄바꿈 문자 포함)를 제거하는 strip() 메서드와 조합해서 사용하기도 한다.
pieces = [x.strip() for x in val.split(',')]
pieces
['a', 'b', 'guido']
이렇게 분리된 문자열은 더하기 연산을 사용해서 :: 문자열과 합칠 수도 있다.
first, second, third = pieces
first + '::' + second + '::' + third
'a::b::guido'
하지만 이 방법은 실용적이면서 범용적인 메서드는 아니다. 빠르고 좀 더 파이썬스러운 방법은 리스트나 튜플을 :: 문자열의 join() 메서드로 전달하는 것이다.
'::'.join(pieces)
'a::b::guido'
일치하는 부분문자열의 위치를 찾는 방법도 있다. index()나 find()를 사용하는 것도 가능하지만 파이썬의 in 예약어를 사용하면 일치하는 부분문자열을 쉽게 찾을 수 있다.
'guido' in val
True
val.index(',')
1
val.find(':')
-1
find()와 index()의 차이점은 index()의 경우 문자열을 찾지 못하면 예외를 발생시키지만 find()의 경우에는 -1을 반환한다.
val.index(':')
count()는 특정 부분문자열이 몇 건 발견되었는지 반환한다.
val.count(',')
2
replace()는 찾아낸 패턴을 다른 문자열로 치환한다. 이 메서드는 대체할 문자열로 비어 있는 문자열을 넘겨서 패턴을 삭제하기 위한 방법으로 자주 사용되기도 한다.
val.replace(',', '::')
'a::b:: guido'
val.replace(',', '')
'ab guido'
다음은 파이썬의 내장 문자열 함수이다.
| 인자 | 설명 |
|---|---|
| count | 문자열에서 겹치지 않는 부분문자열의 개수를 반환한다. |
| endswith | 문자열이 주어진 접미사로 끝날 경우 True를 반환한다. |
| startswith | 문자열이 주어진 접두사로 시작할 경우 True를 반환한다. |
| join | 문자열을 구분자로 하여 다른 문자열을 순서대로 이어붙인다. |
| index | 부분문자열의 첫 번째 글자의 위치를 반환한다. 부분문자열이 없을 경우 ValueError 예외가 발생한다. |
| find | 첫 번째 부분문자열의 첫 번째 글자의 위치를 반환한다. index와 유사하지만 부분문자열이 없을 경우 -1을 반환한다. |
| rfind | 마지막 부분문자열의 첫 번째 글자의 위치를 반환한다. 부분문자열이 없을 경우 -1을 반환한다. |
| replace | 문자열을 다른 문자열로 치환한다. |
| strip, rstrip, lstrip | 개행 문자를 포함한 공백 문자를 제거한다. lstrip은 문자열의 시작 부분에 있는 공백 문자만 제거하며, rstrip은 문자열의 마지막 부분에 있는 공백 문자만 제거한다. |
| split | 문자열을 구분자를 기준으로 부분문자열의 리스트로 분리한다. |
| lower | 알파벳 문자를 소문자로 변환한다. |
| upper | 알파벳 문자를 대문자로 변환한다. |
| casefold | 문자를 소문자로 변환한다. 지역 문자들은 그에 상응하는 대체 문자로 교체된다. |
| ljust, rjust | 문자열을 오른쪽 또는 왼쪽으로 정렬하고 주어진 길이에서 문자열의 길이를 제외한 나머지 부분은 공백 문자를 채워 넣는다. |
정규 표현식
정규 표현식은 텍스트에서 문자열 패턴을 찾는 유연한 방법을 제공한다. 흔히 regex라 불리는 단일 표현식은 정규 표현 언어로 구성된 문자열이다. 파이썬에는 re 모듈이 내장되어 있어서 문자열에 대한 정규 표현식을 처리한다.
re 모듈 함수는 패턴 매칭, 치환, 분리 세 가지로 나눌 수 있다. 물론 이 세 가지는 모두 서로 연관되어 있는데, 정규 표현식은 텍스트 내에 존재하는 패턴을 표현하고 이를 여러 가지 다양한 목적으로 사용할 수 있도록 되어 있다. 간단한 예제를 하나 살펴보자. 여러 가지 공백 문자(탭, 스페이스, 개행 문자)가 포함된 문자열을 나누고 싶다면 하나 이상의 공백 문자를 의미하는 \s+를 사용해서 문자열을 분리한다.
import re
text = "foo bar\t bax \nqux"
print(text)
re.split('\s+', text)
foo bar bax qux
['foo', 'bar', 'bax', 'qux']
re.split('\s+', text)를 사용하면 먼저 정규 표현식이 컴파일되고 그다음에 split()메서드가 실행된다. re.compile()로 직접 정규 표현식을 컴파일하고 그렇게 얻은 정규 표현식 객체를 재사용하는 것도 가능하다.
regex = re.compile('\s+')
regex.split(text)
['foo', 'bar', 'bax', 'qux']
정규 표현식에 매칭되는 모든 패턴의 목록을 얻고 싶다면 findall() 메서드를 사용한다.
regex.findall(text)
[' ', '\t ', ' \n']
같은 정규 표현식을 다른 문자열에도 적용해야 한다면 re.compile()을 이용해서 정규 표현식 객체를 만들어 쓰는 방법을 추천한다. 이렇게 하면 CPU 사용량을 아낄 수 있다.
정규 표현식에서 \ 문자가 이스케이프되는 문제를 피하려면 raw 문자열 표기법을 사용한다. 그러면 \를 이스케이프 문자로 처리하지 않고 일반 문자로 처리하기 때문에 \를 간단하게 표현할 수 있다. 즉, ‘C:\x’ 대신 r’C:\x’를 사용한다.
text1 = 'foo\\t boo'
text2 = r'foo\t boo'
print(text1)
print(text2)
foo\t boo foo\t boo
match()와 search()는 findall() 메서드와 관련이 있다. findall()은 문자열에서 일치하는 모든 부분문자열을 찾아주지만 search() 메서드는 패턴과 일치하는 첫 번째 존재를 반환한다. match() 메서드는 이보다 더 엄격해서 문자열의 시작부분에서 일치하는 것만 찾아준다. 약간 복잡한 예제로 이메일 주소를 검사하는 정규 표현식을 한 번 살펴보자.
text = """Dave dave@google.com
Steve steve@gmail.com
Rob rob@gmail.com
Ryan ryan@yahoo.com
"""
# 영숫자와 ('.', '_', '%', '+', '-') 로 시작
# @ 필수
# 다음에 영숫자와 ('.', '-') 하나 이상
# . 필수
# 영문자가 2개 이상 4개 이하로 끝나는 패턴
pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}'
# re.IGNORECALSE는 정규 표현식이 대소문자를 가리지 않도록 한다.
regex = re.compile(pattern, flags=re.IGNORECASE)
findall() 메서드를 사용해서 이메일 주소의 리스트를 생성하자.
regex.findall(text)
['dave@google.com', 'steve@gmail.com', 'rob@gmail.com', 'ryan@yahoo.com']
search()는 텍스트에서 첫 번째 이메일 주소만을 찾아준다. 위 정규 표현식에 대한 match 객체는 그 정규 표현 패턴이 문자열 내에서 위치하는 시작점과 끝점만을 알려준다.
m = regex.search(text)
m
<re.Match object; span=(5, 20), match='dave@google.com'>
text[m.start():m.end()]
'dave@google.com'
regex.math()는 그 정규 표현 패턴이 문자열의 시작점에서부터 일치하는지 검사하기 때문에 None을 반환한다.
print(regex.match(text))
None
sub() 메서드는 찾은 패턴을 주어진 문자열로 치환하여 새로운 문자열을 반환한다.
print(regex.sub('REDACTED', text))
Dave REDACTED Steve REDACTED Rob REDACTED Ryan REDACTED
이메일 주소를 찾아서 동시에 각 이메일 주소를 사용자 이름, 도메인 이름, 도메인 접미사 세 가지 컴포넌트로 나눠야 한다면 각 패턴을 괄호로 묶어준다.
pattern = r'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})'
regex = re.compile(pattern, flags=re.IGNORECASE)
이렇게 만든 match 객체를 이용하면 groups() 메서드로 각 패턴 컴포넌트의 튜플을 얻을 수 있다.
m = regex.match('wesm@bright.net')
m.groups()
('wesm', 'bright', 'net')
패턴에 그룹이 존재한다면 findall() 메서드는 튜플의 목록을 반환한다.
regex.findall(text)
[('dave', 'google', 'com'),
('steve', 'gmail', 'com'),
('rob', 'gmail', 'com'),
('ryan', 'yahoo', 'com')]
sub() 역시 마찬가지로 \1, \2 같은 특수한 기호를 사용해서 각 패턴 그룹에 접근할 수 있다. \1은 첫 번째로 찾은 그룹을 의미하고, \2는 두 번째로 찾은 그룹을 의미한다.
print(regex.sub(r'Username: \1, Domain: \2, Suffix: \3', text))
Dave Username: dave, Domain: google, Suffix: com Steve Username: steve, Domain: gmail, Suffix: com Rob Username: rob, Domain: gmail, Suffix: com Ryan Username: ryan, Domain: yahoo, Suffix: com
다음은 정규 표현식 메서드 중 일부를 설명한 것이다.
| 인자 | 설명 |
|---|---|
| findall | 문자열에서 겹치지 않는 모든 발견된 패턴을 리스트로 반환한다. |
| finditer | findall과 같지만 발견된 패턴을 이터레이터를 통해 하나씩 반환한다. |
| match | 문자열의 시작점부터 패턴을 찾고 선택적으로 패턴 컴포턴트를 그룹으로 나눈다. 일치하는 패턴이 있다면 match 객체를 반환하고 그렇지 않으면 None을 반환한다. |
| search | 문자열에서 패턴과 일치하는 내용을 검색하고 match 객체를 반환한다. match 메서드와는 다르게 시작부터 일치하는 내용만 찾지 않고 문자열 어디든 일치하는 내용이 있다면 반환한다. |
| split | 문자열에서 패턴과 일치하는 부분을 분리한다. |
| sub, subn | 문자열에서 일치하는 모든 패턴(sub) 혹은 처음 n개의 패턴(subn)을 대체 표현으로 치환한다. 대체 표현 문자열은 \1, \2, ...와 같은 기호를 사용해서 매치 그룹의 요소를 참조한다. |
판다스의 벡터화된 문자열 함수
뒤죽박죽인 데이터를 분석을 위해 정리하는 일은 문자열을 다듬고 정규화하는 작업을 필요로 한다. 문자열을 담고 있는 칼럼에 누락된 값이 있다면 일을 더 복잡하게 만든다.
data = {'Dave': 'dave@google.com', 'Steve': 'steve@gmail.com',
'Rob': 'rob@gmail.com', 'Wes': NA}
data = pd.Series(data)
data
Dave dave@google.com Steve steve@gmail.com Rob rob@gmail.com Wes NaN dtype: object
data.isnull()
Dave False Steve False Rob False Wes True dtype: bool
문자열과 정규 표현식 메서드는 map()을 사용해서 각 값에 적용(lambda 혹은 다른 함수를 넘겨서)할 수 있지만 NA 값을 만나면 실패하게 된다. 이런 문제에 대처하기 위해 시리즈에는 NA 값을 건너뛰도록 하는 간결한 문자열 처리 메서드가 있다. 이는 시리즈의 str 속성을 이용하는데, 예를 들어 각 이메일 주소가 ‘gmail’을 포함하고 있는지 str.contains()를 이용해서 검사할 수 있다.
data.str.contains('gmail')
Dave False Steve True Rob True Wes NaN dtype: object
정규 표현식을 IGNORECASE 같은 re 옵션과 함께 사용하는 것도 가능하다.
pattern
'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\\.([A-Z]{2,4})'
data.str.findall(pattern, flags=re.IGNORECASE)
Dave [(dave, google, com)] Steve [(steve, gmail, com)] Rob [(rob, gmail, com)] Wes NaN dtype: object
matches = data.str.match(pattern, flags=re.IGNORECASE)
matches
Dave True Steve True Rob True Wes NaN dtype: object
벡터화된 요소를 꺼내오는 몇 가지 방법이 있는데 str.get()을 이용하거나 str 속성의 인덱스를 이용한다. 내재된 리스트의 원소에 접근하기 위해서는 인덱스를 넘기면 된다.
data.str.get(1)
Dave a Steve t Rob o Wes NaN dtype: object
data.str[0]
Dave d Steve s Rob r Wes NaN dtype: object
아래 문법으로 문자열을 잘라낼 수 있다.
data.str[:5]
Dave dave@ Steve steve Rob rob@g Wes NaN dtype: object
다음은 판다스의 벡터화된 문자열 메서드를 정리한 것이다.
| 메서드 | 설명 |
|---|---|
| cat | 선택적인 구분자와 함께 요소별로 문자열을 이어붙인다. |
| contains | 문자열이 패턴이나 정규 표현식을 포함하는지 나타내는 불리언 배열을 반환한다. |
| count | 일치하는 패턴 수를 반환한다. |
| extract | 문자열이 담긴 시리즈에서 하나 이상의 문자열을 추출하기 위해 정규 표현식을 이용한다. 결과는 각 그룹이 하나의 칼럼이 되는 데이터프레임이다. |
| endswith | 각 요소에 대해 x.endswith(pattern)과 동일한 동작을 한다. |
| startswith | 각 요소에 대해 x.startswith(pattern)과 동일한 동작을 한다. |
| findall | 각 문자열에 대해 일치하는 패턴/정규 표현식의 전체 목록을 구한다. |
| get | i번째 요소를 반환한다. |
| isalnum | 내장 함수 str.isalnum과 동일 |
| isalpha | 내장 함수 str.isalpha와 동일 |
| isdecimal | 내장 함수 str.isdecimal과 동일 |
| isdigit | 내장 함수 str.isdigit와 동일 |
| islower | 내장 함수 str.islower와 동일 |
| isnumeric | 내장 함수 str.isnumeric와 동일 |
| isupper | 내장 함수 str.isupper와 동일 |
| join | 시리즈의 각 요소를 주어진 구분자로 연결한다. |
| len | 각 문자열의 길이를 구한다. |
| lower, upper | 대소문자로 변환한다. 각 요소에 대한 x.lower(), x.upper()와 같다. |
| match | 주어진 정규 표현식으로 각 요소에 대한 re.match를 수행하여 일치하는 그룹을 리스트로 반환한다. |
| pad | 문자열의 좌, 우 혹은 양쪽에 공백을 추가한다. |
| center | pad(side='both')와 동일 |
| repeat | 값을 복사한다. 예를 들어 s.str.repeat(3)은 각 문자열에 대한 x * 3과 동일하다. |
| replace | 패턴/정규 표현식과 일치하는 내용을 다른 문자열로 치환한다. |
| slice | 시리즈 안에 있는 각 문자열을 자른다. |
| split | 정규 표현식 혹은 구분자로 문자열을 나눈다. |
| strip | 개행 문자를 포함하여 왼쪽과 오른쪽의 공백 문자를 제거한다. |
| rstrip | 오른쪽의 공백 문자를 제거한다. |
| lstrip | 왼쪽의 공백 문자를 제거한다. |
효율적인 데이터 준비 과정은 분석 준비를 하는 데 드는 시간을 줄이고 실제 분석에 좀 더 많은 시간을 쓸 수 있도록 하여 결과적으로는 생산성을 향상시킨다.
댓글남기기