그래프와 시각화
그래프와 시각화
데이터를 보기 쉽게 그림으로 표현한 것을 그래프graph라고 한다. 데이터 원자료나 통계표는 수많은 숫자와 문자로 구성되어 있어서 내용을 파악하기 어렵다. 데이터를 시각화하여 그래프로 표현하면 추세, 경향성 그리고 구조가 드러나기 때문에 특징을 쉽게 이해할 수 있고, 그래프를 만드는 과정에서 새로운 패턴을 발견하기도 한다. 또한, 특잇값을 찾아내거나, 데이터 변형이 필요한지 알아보거나, 모델에 대한 아이디어를 찾기 위한 과정이 일부이기도 하다. 특히 분석 결과를 발표할 때 그래프를 활용하면 데이터의 특징을 잘 전달할 수 있다. 이처럼 다양한 관점에서 데이터에 관한 통찰력을 제공하는 정보 시각화는 데이터 분석에서 무척 중요한 일 중 하나다.
파이썬의 대표적인 시각화 패키지인 matplotlib는 주로 2D 그래프를 위한 데스크톱 패키지로, 출판물 수준의 그래프를 만들어내도록 설계되었다. matplotlib 프로젝트는 파이썬에서 매트랩과 유사한 인터페이스를 지원하기 위해 2002년 존 헌터John Hunter가 시작했다. 그 후 IPython과 matplotlib 커뮤니티의 협력을 통해 IPython 셸(지금의 주피터 노트북)에서 대화형 시각화를 구현해냈다. matplotlib은 모든 운영체제의 다양한 GUI 백엔드를 지원하고 있으며 PDF, SVG, JPG, PNG, BMP, GIF 등 일반적으로 널리 사용되는 벡터 포맷과 래스터 포맷으로 그래프를 저장할 수 있다. 또한 객체지향 프로그래밍을 지원하므로 그래프 요소를 세세하게 꾸밀 수 있다.
하지만, matplotlib는 너무 세분화된 API로 익히기가 번거롭고 시각적인 디자인 부분에서도 투박한 면이 있다. 단순히 시각화를 위해 데이터 분석가/과학자가 작성하는 코드가 길어지기 때문에 효율이 떨어지고 불편함이 늘어날 수 있다. 이를 보완하기 위한 여러 시각화 패키지가 출시되고 있는데, 대표적으로 seaborn 라이브러리가 있다.
여기서 진행할 코드 예제를 실행시키는 가장 손쉬운 방법은 주피터 노트북의 대화형 시각화 기능을 사용하는 것이다. 이 기능을 활성화하려면 주피터 노트북을 싱행시킨 후 다음 명령을 입력한다.
%matplotlib notebook
대화형 시각화 기능을 사용하지 않고 일반적인 그래프만을 출력하려면 다음 명령을 입력한다.
%matplotlib inline
matplotlib API 간략하게 살펴보기
앞으로도 계속 그러겠지만, matplotlib을 아래와 같은 네이밍 컨벤션으로 임포트하겠다.
import matplotlib.pyplot as plt
주피터 노트북 환경에서 간단한 그래프를 그려보자.
import numpy as np
data = np.arange(10)
display(data)
plt.plot(data)
plt.show()
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])

나중에 seaborn 라이브러리나 판다스로 그래프를 그리는 방법과 그래프가 만들어지는 세부 사항에 관한 내용을 다루게 되는데, 함수에서 제공하는 옵션만 사용하는 데 그치지 않고 그 이상의 최적화를 하고 싶다면 matplotlib API도 어느 정도 알고 있어야 한다.
figure과 서브플롯
matplotlib에서 그래프는 Figure 객체 내에 존재한다. 그래프를 위한 새로운 figure(그래프를 그릴 공간/종이) 는 plt.figure()를 사용해서 생성할 수 있다.
fig = plt.figure()

IPython에서 실행했다면 빈 윈도우가 나타날 것이다. 반면 주피터에서는 몇 가지 명령을 더 입력하기 전에는 아무것도 나타나지 않을 것이다. plt.figure() 에는 다양한 옵션이 있는데 그중 figsize 는 파일에 저장할 경우를 위해 만들려는 figure 의 크기와 비율을 지정할 수 있다.
빈 figure로는 그래프를 그릴 수 없다. add_subplot() 를 사용해서 최소 하나 이상의 subplots 를 생성해야 한다. ax(axes)는 figure 의 공간 중 지금 내가 사용할 부분이라고 생각하자.
ax1 = fig.add_subplot(2, 2, 1)
위 코드는 figure 가 2x2 크기이고 4개의 서브플롯 중에서 첫 번째를 선택하겠다는 의미다(서브플롯은 1부터 숫자가 매겨진다). 다음처럼 2개의 서브플롯을 더 추가해보겠다.
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
주피터 노트북을 사용할 때는 실행되는 셀마다 그래프가 리셋된다. 따라서 복잡한 그래프를 그릴 때는 단일 노트북 셀에 그래프를 그리는 코드를 전부 입력해야 한다.
아래와 같은 코드를 같은 셀에서 실행한다.
fig = plt.figure()
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)

plt.plot() 명령으로 그래프를 띄우면 matplotlib은 가장 최근의 figure 와 그 서브플롯에 그린다. 서브플롯이 없다면 서브플롯 하나를 생성한다. 이렇게 해서 figure 와 서브플롯이 생성되는 과정을 숨겨준다. 따라서 다음 명령을 실행하면 마지막 서브플롯에 그래프를 그린다.
plt.plot(np.random.randn(50).cumsum(), 'k--')
[<matplotlib.lines.Line2D at 0x1efa95ff5b0>]
‘k–’ 옵션은 검은 점선을 그리기 위한 스타일 옵션이다. fig.add_subplot()에서 반환되는 객체는 AxesSubplot 인데, 각각의 인스턴스 메서드를 호출해서 다른 빈 서브플롯에 직접 그래프를 그릴 수 있다.
_ = ax1.hist(np.random.randn(100), bins=20, color='k', alpha=0.3)
ax2.scatter(np.arange(30), np.arange(30) + 3 * np.random.randn(30))
<matplotlib.collections.PathCollection at 0x1efa9619040>
위 명령어를 반복해서 실행하면 기존에 있던 그래프 위에 겹쳐서 계속 나오니 주의하자.
matplotlib 문서에서 여러 가지 그래프 종류를 확인할 수 있다.
특정한 배치에 맞추어 여러 개의 서브플롯을 포함하는 figure 를 생성하는 일은 흔히 접하게 되는 업무인데 이를 위한 plt.subplots()라는 편리한 메서드가 있다. 이 메서드는 서브플롯 객체를 담고 있는 NumPy 배열을 새로 생성하여 반환한다.
fig, axes = plt.subplots(2, 3)
display(axes)
type(axes)

array([[<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>],
[<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>]], dtype=object)
numpy.ndarray
axes 배열은 axes[0, 1] 처럼 2차원 배열로 쉽게 인덱싱할 수 있어서 편리하게 사용할 수 있다. 서브플롯이 같은 x축 혹은 y축을 가져야 한다면 각각 sharex 와 sharey 를 사용해서 지정할 수 있다. 같은 범위 내에서 데이터를 비교해야 할 경우 특히 유용하다. 그렇지 않으면 matplotlib 은 각 그래프의 범위를 독립적으로 조정한다. 이 메서드에 대한 자세한 내용은 다음 pyplot.subplots() 옵션을 정리한 표와 후에 다룰 내용을 참조하자.
| 인자 | 설명 |
|---|---|
| nrows | 서브플롯의 로우 수 |
| ncols | 서브플롯의 칼럼 수 |
| sharex | 모든 서브플롯이 같은 x축 눈금을 사용하도록 한다(xlim 값을 조절하면 모든 서브플롯에 적용된다). |
| sharey | 모든 서브플롯이 같은 y축 눈금을 사용하도록 한다(ylim 값을 조절하면 모든 서브플롯에 적용된다). |
| subplot_kw | add_subplot을 사용해서 각 서브플롯을 생성할 때 사용할 키워드를 담고 있는 사전 |
| **fig_kw | figure를 생성할 때 사용할 추가적인 키워드 인자. 예를 들면 plt.subplots(2, 2, figsize=(8, 6)) |
서브플롯 간의 간격 조절하기
matplotlib 은 서브플롯 간에 적당한 간격spacing과 여백padding을 추가해준다. 이 간격은 전체 그래프의 높이와 너비에 따라 상대적으로 결정된다. 그러므로 프로그램을 이용하든 아니면 직접 GUI 윈도우의 크기를 조정하든 그래프의 크기가 자동으로 조절된다. 서브플롯 간의 간격은 Figure 객체의 subplots_adjust() 메서드를 사용해서 쉽게 바꿀 수 있다. subplots_adjust() 메서드는 최상위 함수로도 존재한다.
subplots_adjust(left=None, bottom=None, right=None, top=None,
wspace=None, hspace=None)
wspace 와 hspace 는 서브플롯 간의 간격을 위해 각각 figure 의 너비와 높이에 대한 비율을 조절한다. 다음 코드는 서브플롯 간의 간격을 주지 않은 그래프를 생성하는 코드다.
fig, axes = plt.subplots(2, 2, sharex=True, sharey=True)
for i in range(2):
for j in range(2):
axes[i, j].hist(np.random.randn(500), bins=50, color='k', alpha=0.5)
plt.subplots_adjust(wspace=0, hspace=0)

그래프를 그렸을 때 축 이름이 겹치는 경우가 있다. matplotlib 은 그래프에서 이름이 겹치는지 검사하지 않기 때문에 이와 같은 경우에는 눈금 위치와 눈금 이름을 명시적으로 직접 지정해야 한다.
색상, 마커, 선 스타일
matplotlib 에서 가장 중요한 plot() 함수는 x 와 y 좌푯값이 담긴 배열과 추가적으로 색상과 선 스타일을 나타내는 축약 문자열을 인자로 받는다. 예를 들어 녹색 점선으로 그려진 x 대 y 그래프는 아래처럼 나타낼 수 있다.
ax.plot(x, y, 'g--')
이와 같이 문자열로 색상과 선 스타일을 지정하는 방법은 편의를 위해 제공되고 있는데, 실무에서 프로그램으로 그래프를 생성할 때는 그래프를 원하는 형식으로 생성하기 위해 문자열을 지저분하게 섞어 쓰고 싶지 않을 것이다. 위에서 만든 그래프는 아래처럼 좀 더 명시적인 방법으로 표현 가능하다.
ax.plot(x, y, linestyle='--', color='g')
흔히 사용되는 색상을 위해 몇 가지 색상 문자열이 존재하지만 RGB 값(예: #CECEFCE)을 직접 지정해서 색상표에 있는 어떤 색상이라도 지정할 수 있다. 선 스타일에 대한 전체 목록은 plot() 메서더의 도움말을 참고하자(IPython이나 주피터에서 plot?을 입력한다).
선그래프는 특정 지점의 실제 데이터를 돋보이게 하기 위해 마커를 추가하기도 한다. matplotlib 은 점덜을 잇는 연속된 선그래프를 생성하기 때문에 어떤 지점에 마커를 설정해야 하는지 확실치 않은 경우가 종종 있다. 마커도 스타일 문자열에 포함시킬 수 있는데 색상 다음에 마커 스타일이 오고 그 뒤에 선 스타일을 지정한다.
from numpy.random import randn
fig = plt.figure()
plt.plot(randn(30).cumsum(), 'ko--')

[<matplotlib.lines.Line2D at 0x1efac5630a0>]
이 역시 좀 더 명시적인 방법으로 표현할 수 있다.
plot(randn(30).cumsum(), color='k', linestyle='dashed', marker='o')
선그래프를 보면 일정한 간격으로 연속된 지점이 연결되어 있다. 이 역시 drawstyle 옵션을 이용해서 바꿀 수 있다. 다음은 선형으로 연결한 그래프 하나, 계단형으로 연결한 그래프 하나를 보여준다.
data = np.random.randn(30).cumsum()
fig = plt.figure()
plt.plot(data, 'k--', label='Default', marker='o')
plt.plot(data, 'k-', drawstyle='steps-post', label='steps-post')
plt.legend(loc='best')

<matplotlib.legend.Legend at 0x28bb4d59940>
이 코드를 실행해보면 그래프와 <matplotlib.legend.Legend at 0x1efae2cc160> 과 같은 결과를 확인할 수 있다. matplotlib 은 방금 추가된 그래프의 하위 컴포넌트에 대한 레퍼런스 객체를 리턴한다. 이 결과는 무시해도 된다. 여기서는 plot() 에 label 인자를 전달했기 때문에 plt.legend() 를 이용해서 각 선그래프의 범례를 추가할 수 있다. 이 설명 메시지를 숨기고 싶다면 그래프 출력 코드 뒤에 ‘;’을 입력한다.
범례를 생성하려면 그래프를 그릴 때 label 옵션 지정 여부와 상관없이 반드시 plt.legend() 를 호출해야 한다(축에 대한 범례를 추가하려면 ax.legend() 를 호출하자). 다만, 모든 그래프의 label 옵션을 지정하지 않으면 No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument. 과 같은 문구가 뜨며 범례가 표시되지 않는다.
눈금, 라벨, 범례
그래프를 꾸미는 방법은 크게 2가지가 있다. pyplot 인터페이스를 사용해서 순차적으로 꾸미든가(즉, matplotlib.pyplot) 아니면 matplotlib 이 제공하는 API를 사용해서 좀 더 객체지향적인 방법으로 꾸미는 것이다.
pyplot 인터페이스는 대화형 사용에 맞추어 설계되었으며 xlim(), xticks(), xticklabels() 같은 메서드로 이루어져 있다. 이런 메서드로 표의 범위를 지정하거나 눈금 위치, 눈금 이름을 조절할 수 있다.
-
아무런 인자 없이 호출하면 현재 설정되어 있는 매개변수의 값을 반환한다.
plt.xlim()메서드는 현재 x축의 범위를 반환한다. -
인자를 전달하면 매개변수의 값을 설정한다. 예를 들어
plt.xlim([0, 10])을 호출하면 x축의 범위가 0부터 10까지로 설정된다.
이 모든 메서드는 현재 활성화된 혹은 가장 최근에 생성된 AxesSubplot 객체에 대해 동작한다. 위에서 소개한 모든 메서드는 서브플롯 객체의 set()/get() 메서드로도 존재하는데, xlim() 이라면 ax.get_lim()과 ax.set_xlim() 메서드가 존재한다. 명시적인 이유로(특히 여러 개의 서브플롯을 다룰 때) 서브플롯 인스턴스를 사용하는 것이 좋지만, 각자에게 편리한 메서드를 사용해도 상관없다.
제목, 축 이름, 눈금, 눈금 이름 설정하기
축을 꾸미는 방법을 설명하기 위해 무자구이 값으로 간단한 그래프를 하나 생성해보겠다.
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(np.random.randn(1000).cumsum())
plt.show()

x축의 눈금을 변경하기 위한 가장 쉬운 방법은 set_xticks()와 set_xticklabels() 메서드를 사용하는 것이다. set_xticks() 메서드는 전체 데이터 범위를 따라 눈금을 어디에 배치할지 지정한다. 기본적으로 이 위치(해당 값)에 인자로 전달한 수가 눈금에 들어간다. 하지만 그 위치(해당 값)에 다른 눈금 이름을 지정하고 싶다면 set_xticklabels()를 사용하면 된다.
ticks = ax.set_xticks([0, 250, 500, 750, 1000])
labels = ax.set_xticklabels(['one', 'two', 'three', 'four', 'five'],
rotation=30, fontsize='small')
마지막으로 set_xlabel() 메서드는 x축에 대한 이름을 지정하고 set_title() 메서드는 서브플롯의 제목을 지정한다.
ax.set_title('My first matplotlib plot')
ax.set_xlabel('Stages')
Text(0.5, 10.888891973024519, 'Stages')
물론 x대신 y를 써서 같은 과정을 y축에 대해 진행할 수 있다. axes 클래스는 플롯의 속성을 설정할 수 있도록 set() 메서드를 제공한다. 위 예제는 아래와 같이 작성할 수도 있다.
props = {
'title': 'My first matplotlib plot',
'xlabel': 'Stages'
}
ax.set(**props) </code>
범례 추가하기
범례는 그래프 요소를 확인하기 위한 중요한 요소다. 범례를 추가하는 몇 가지 방법이 있는데 가장 쉬운 방법은 각 그래프에 label 인자를 넘기는 것이다.
from numpy.random import randn
fig = plt.figure(); ax = fig.add_subplot(1, 1, 1)
ax.plot(randn(1000).cumsum(), 'k', label='one')
ax.plot(randn(1000).cumsum(), 'k--', label='two')
ax.plot(randn(1000).cumsum(), 'k.', label='three')
plt.show()

이렇게 하면 ax.legend()나 plt.legend()를 실행했을 때 자동으로 범례가 생성된다.
ax.legend(loc='best')
<matplotlib.legend.Legend at 0x28bb4d7f940>
legend() 메서드는 범례 위치를 지정하기 위한 loc 인자를 제공한다. legend() 메서드의 문서에서 더 자세한 정보를 확인할 수 있다(ax.legend? 명령으로 확인해보자).
loc은 범례를 그래프에서 어디에 위치시킬지 지정해주는 인자다. 까다로운 사람이 아니라면 최대한 방해가 되지 않는 곳에 두는 ‘best’ 옵션만으로 충분할 것이다. 범례에서 제외하고 싶은 요소가 있다면 label 인자를 넘기지 않거나 label=’_nolegend_’ 옵션을 사용하면 된다.
주석과 그림 추가하기
일반적인 그래프에 추가적으로 글자나 화살표 혹은 다른 도형으로 자기만의 주석을 그리고 싶은 경우가 있다. 주석과 글자는 text(), arrow(), annotate() 함수를 이용해서 추가할 수 있다. text() 함수는 그래프 내의 주어진 좌표 (x, y)에 부가적인 스타일로 글자를 그려준다.
ax.text(x, y, 'Hello world!',
family='monospace', fontsize=10)
주석은 글자와 화살표를 함께 써서 그릴 수 있는데, 예를 들어 야후! 파이낸스에서 얻은 2007년부터의 S&P 500 지수 데이터로 그래프를 생성하고 2008-2009년 사이에 있었던 재정위기 중 중요한 날짜를 주석으로 추가해보자. 주피터 노트북의 단일 셀 안에서 코드 예제를 실행하면 쉽게 그래프를 그릴 수 있다.
그래프에 대한 설명을 덧붙이는 주석은 annotate() 함수를 사용한다. 주석 내용(텍스트)을 넣을 위치와 정렬 방법 등을 annotate() 함수에 함께 전달한다. arrowprops 옵션을 사용하면 텍스트 대신 화살표가 표시된다. 화살표 스타일, 시작점과 끝점의 좌표를 입력한다. annotate() 함수로 화살표와 텍스트 위치를 잡아서 배치한다.
annotate() 함수의 rotation 옵션에서 양(+)의 회전 방향은 반시계방향이다. 글자를 위아래 세로 방향으로 정렬하는 va(verticalalignment) 옵션은 ‘center’, ‘top’, ‘bottom’, ‘baseline’이 있다. 좌우 가로 방향으로 정렬하는 ha(horizontalalignment) 옵션에는 ‘center’, ‘left’, ‘right’가 있다. 상세 옵션에 대한 정보는 다음의 링크를 참조한다.
*참조: https://matplotlib.org/api/_as_gen/matplotlib.pyplot.annotate.html
from datetime import datetime
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
data = pd.read_csv('examples/spx.csv', index_col=0, parse_dates=True)
spx = data['SPX']
spx.plot(ax=ax, style='k-')
crisis_data = [
(datetime(2007, 10, 11), 'Peak of bull market'),
(datetime(2008, 3, 12), 'Bear Stearns Fails'),
(datetime(2008, 9, 15), 'Lehman Bankruptcy')
]
for date, label in crisis_data:
ax.annotate(label, xy=(date, spx.asof(date) + 75),
xytext=(date, spx.asof(date) + 225),
arrowprops=dict(facecolor='black', headwidth=4, width=2,
headlength=4),
horizontalalignment='left', verticalalignment='top')
# 2007-2010 구간으로 확대
ax.set_xlim(['1/1/2007', '1/1/2011'])
ax.set_ylim([600, 1800])
ax.set_title('Important dates in the 2009-2009 financial crisis')
plt.show()

이 그래프에서는 알고 넘어가야 할 몇몇 중요한 내용이 있는데, ax.annotate() 메서드를 이용해서 x, y 좌표로 지정한 위치에 라벨을 추가했으며 set_xlim()과 set_ylim() 메서드를 이용해서 그래프의 시작과 끝 경계를 직접 지정했다. 마지막으로 ax.set_title() 메서드로 그래프의 제목을 지정했다.
온라인에서 matplotlib 갤러리를 둘러보면 배울 만한 여러 가지 다양한 주석 예제를 확인할 수 있다.
도형을 그리려면 좀 더 신경을 써야 한다. matplotlib 은 일반적인 도형을 표현하기 위한 patches 라는 객체를 제공한다. 그중 Rectangle()과 Circle() 같은 것은 matplotlib.pyplot 에서도 찾을 수 잇지만 전체 모음은 matplotlib.patches 에 있다.
그래프에 도형을 추가하려면 patches 객체인 shp 를 만들고 서브플롯에 ax.add_patch(shp)를 호출한다.
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# 왼쪽 모서리의 좌표, 너비, 높이
rect = plt.Rectangle((0.2, 0.75), 0.4, 0.15, color='k', alpha=0.3)
# 중심의 좌표, 반지름
circ = plt.Circle((0.7, 0.2), 0.15, color='b', alpha=0.3)
# 각 점의 좌표
pgon = plt.Polygon([[0.15, 0.15], [0.35, 0.4], [0.2, 0.6]],
color='g', alpha=0.5)
ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon)
plt.show()

보기 좋은 여러 가지 그래프를 잘 살펴보면 다양한 patches를 잘 조합했다는 사실을 확인할 수 있을 것이다.
그래프를 파일로 저장하기
활성화된 figure는 plt.savefig() 메서드를 이용해서 파일을 저장할 수 있다. 이 메서드는 figure 객체의 인스턴스 메서드인 savefig()와 동일하다. figure를 SVG 포맷으로 저장하려면 다음처럼 하면 된다.
plt.savefig('figpath.svg')
파일 종류는 확장자로 결정된다. 그러므로 .svg 대신에 .pdf를 입력하면 PDF 파일을 얻게 된다. 출판용 그래픽 파일을 생성할 때 자주 사용하는 몇 가지 중요한 옵션이 있는데 바로 dpi와 bbox_inches다. dpi는 인치당 도트 해상도를 조절하고 bbox_inches는 실제 figure 둘레의 공백을 잘라낸다. 그래프 간 최소 공백을 가지는 400DPI짜리 PNG 파일을 만들려면 아래와 같이 입력한다.
plt.savefig('figpath.png', dpi=400, bbox_inches='tight')
savefig() 메서드는 파일에 저장할 뿐만 아니라 BytesIO처럼 파일과 유사한 객체에 저장하는 것도 가능하다.
from io import BytesIO
buffer = BytesIO()
plt.savefig(buffer)
plot_data = buffer.getvalue()
다음은 Figure.savefig() 메서드의 옵션을 정리한 것이다.
| 인자 | 설명 |
|---|---|
| fname | 파일 경로나 파이썬의 파일과 유사한 객체를 나타내는 문자열. 저장되는 포맷은 파일 확장자를 통해 결정된다. 예를 들어 .pdf는 PDF 포맷, .png는 PNG 포맷 |
| dpi | figure의 인치당 도트 해상도. 기본값은 100이며, 설정 가능하다. |
| facecolor, edgecolor | 서브플롯 바깥 배경 색상. 기본값은 'w'(흰색)다. |
| format | 명시적인 파일 포맷('png', 'pdf', 'svg', 'ps', 'eps', ...) |
| bbox_inches | figure에서 저장할 부분. 만약 'tight'를 지정하면 figure 둘레의 비어 있는 공간을 모두 제거한다. |
matplotlib 설정
그래프 설정 바꾸기
matplotlib은 출판물용 그래프를 만드는 데 손색이 없는 기본 설정과 색상 스키마를 함께 제공한다. 다행스럽게도 거의 모든 기본 동작은 많은 전역 인자를 통해 설정 가능한데, 그래프 크기, 서브플롯 간격, 색상, 글자 크기, 격자 스타일과 같은 것들을 설정 가능하다. matplotlib의 환경 설정 시스템은 두 가지 방법으로 다룰 수 있는데, 첫 번째는 rc() 메서드를 사용해서 프로그래밍적으로 설정하는 방법이다. 예를 들어 figure의 크기를 10 x 10 으로 전역 설정해두고 싶다면 다음 코드를 실행한다.
plt.rc('figure', figsize=(10, 10))
rc() 메서드의 첫 번째 인자는 설정하고자 하는 ‘figure’, ‘axes’, ‘xtick’, ‘ytick’, ‘grid’, ‘legend’ 및 다른 컴포넌트의 이름이다. 그다음으로 설정할 값에 대한 키워드 인자를 넘기게 된다. 이 옵션을 쉽게 작성하려면 파이썬의 사전 타입을 사용한다.
font_options = {'family': 'monospace',
'weight': 'bold',
'size': 'small'}
plt.rc('font', **font_options)
또는 다음과 같이 바꿀 수도 있다.
plt.rcParams.update({'figure.dpi': '150', # 해상도, 기본값 72
'figure.figsize': [8, 6], # 가로, 세로 크기, 기본값 [6, 4]
'font.size': '15', # 글자 크기, 기본값 10
'font.family': 'Malgun Gothic'}) # 폰트, 기본값 sans-serif
더 많은 설정과 옵션의 종류는 matplotlib/mpl-data 디렉터리에 matplotlibrc라는 파일에 저장되어 있다. 만약 이 파일을 적절히 수정해서 사용자 홈 디렉터리에 .matplotlibrc라는 이름으로 저장해두면 matplotlib을 사용할 때마다 불러오게 된다.
Matplotlib 한글 폰트 오류 해결
matplotlib은 한글 폰트를 지원하지 않는 문제가 있다. 축 이름이나 차트 제목 등을 한글로 설정하면 한글 부분이 네모 박스로 표시되는 것처럼, 그래프를 출력할 때 한글 폰트가 깨지는 현상이 발생한다. 오류를 해결하려면 matplotlib을 사용하는 파이썬 프로그램의 앞부분에 한글 폰트를 지정하는 다음의 코드를 추가한다.
# matplotlib 한글 폰트 오류 문제 해결
from matplotlib import font_manager, rc
font_path = "./malgun.ttf" # 폰트 파일 위치
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
설정하고자 하는 원하는 한글 폰트 파일을 다운로드 받아서 해당 작업 경로의 폴더에 저장한다. 또는 윈도우 설치 폴더에서 사용할 한글 폰트를 찾아서 파일 경로를 font_path에 할당하는 방법도 가능하다(예: font_path = “c:/Windows/Fonts/malgun.ttf”).
Matplotlib 스타일 서식의 종류
matplotlib의 스타일 서식 지정은 색, 폰트 등 디자인적 요소를 사전에 지정된 스타일로 빠르게 일괄 변경한다. 단 스타일 서식을 지정하는 것은 matplotlib 실행 환경 설정을 변경하는 것이므로 다른 코드를 실행할 때도 계속 적용되는 점에 유의한다.
다음과 같이 현재 실행환경에서 사용 가능한 matplotlib의 스타일 옵션을 확인할 수 있다. 각자 원하는 스타일을 선택하여 그래프를 적용해 본다.
다음 절에서 살펴보겠지만 seaborn 패키지는 내부적으로 matplotlib 설정을 사용하는 내장 테마 혹은 스타일을 제공한다.
print(plt.style.available)
['Solarize_Light2', '_classic_test_patch', '_mpl-gallery', '_mpl-gallery-nogrid', 'bmh', 'classic', 'dark_background', 'fast', 'fivethirtyeight', 'ggplot', 'grayscale', 'seaborn', 'seaborn-bright', 'seaborn-colorblind', 'seaborn-dark', 'seaborn-dark-palette', 'seaborn-darkgrid', 'seaborn-deep', 'seaborn-muted', 'seaborn-notebook', 'seaborn-paper', 'seaborn-pastel', 'seaborn-poster', 'seaborn-talk', 'seaborn-ticks', 'seaborn-white', 'seaborn-whitegrid', 'tableau-colorblind10']
스타일이 어떻게 적용되는지 상세한 정보가 필요하다면 다음의 링크를 참조한다.
*참조: https://matplotlib.org/gallery/style_sheets/style_sheets_reference.html
설정 되돌리기
설정한 내용은 JupyterLab을 새로 실행하거나 커널을 새로 실행하면 원래대로 돌아간다. JupyterLab이나 커널을 새로 실행하지 않고 설정을 되돌리려면 다음 코드를 실행하면 된다.
# 모든 설정 되돌리기
plt.rcParams.update(plt.rcParamsDefault)
그래프를 이미지 파일로 저장하기
그래프에 마우스 커서를 올리고 shift + 마우스 오른쪽 클릭한 다음 <이미지를 다른 이름으로 저장>을 클릭하면 그래프를 미지 파일로 저장한다. <이미지 복사>는 그래프를 메모리에 저장하는 기능이다. 이 버튼을 클릭한 다음 엑셀, 파워포인트 등 다른 프로그램에서 붙여넣기를 클릭하면 그래프가 삽입된다.

matplotlib에서 사용할 수 있는 색의 종류
matplotlib 라이브러리를 사용할 때 색상(컬러)을 지정하는 경우가 있다. 이럴 때 사용할 수 있는 색상의 종류를 확인할 수 있다면 매우 유용하다.
# 라이브러리 불러오기
import matplotlib
# 컬러 정보를 담을 빈 딕셔너리 생성
colors = {}
# 컬러 이름과 헥사코드를 확인하여 딕셔너리에 입력
for name, hex in matplotlib.colors.cnames.items():
colors[name] = hex
# 딕셔너리 출력
print(colors)
{'aliceblue': '#F0F8FF', 'antiquewhite': '#FAEBD7', 'aqua': '#00FFFF', 'aquamarine': '#7FFFD4', 'azure': '#F0FFFF', 'beige': '#F5F5DC', 'bisque': '#FFE4C4', 'black': '#000000', 'blanchedalmond': '#FFEBCD', 'blue': '#0000FF', 'blueviolet': '#8A2BE2', 'brown': '#A52A2A', 'burlywood': '#DEB887', 'cadetblue': '#5F9EA0', 'chartreuse': '#7FFF00', 'chocolate': '#D2691E', 'coral': '#FF7F50', 'cornflowerblue': '#6495ED', 'cornsilk': '#FFF8DC', 'crimson': '#DC143C', 'cyan': '#00FFFF', 'darkblue': '#00008B', 'darkcyan': '#008B8B', 'darkgoldenrod': '#B8860B', 'darkgray': '#A9A9A9', 'darkgreen': '#006400', 'darkgrey': '#A9A9A9', 'darkkhaki': '#BDB76B', 'darkmagenta': '#8B008B', 'darkolivegreen': '#556B2F', 'darkorange': '#FF8C00', 'darkorchid': '#9932CC', 'darkred': '#8B0000', 'darksalmon': '#E9967A', 'darkseagreen': '#8FBC8F', 'darkslateblue': '#483D8B', 'darkslategray': '#2F4F4F', 'darkslategrey': '#2F4F4F', 'darkturquoise': '#00CED1', 'darkviolet': '#9400D3', 'deeppink': '#FF1493', 'deepskyblue': '#00BFFF', 'dimgray': '#696969', 'dimgrey': '#696969', 'dodgerblue': '#1E90FF', 'firebrick': '#B22222', 'floralwhite': '#FFFAF0', 'forestgreen': '#228B22', 'fuchsia': '#FF00FF', 'gainsboro': '#DCDCDC', 'ghostwhite': '#F8F8FF', 'gold': '#FFD700', 'goldenrod': '#DAA520', 'gray': '#808080', 'green': '#008000', 'greenyellow': '#ADFF2F', 'grey': '#808080', 'honeydew': '#F0FFF0', 'hotpink': '#FF69B4', 'indianred': '#CD5C5C', 'indigo': '#4B0082', 'ivory': '#FFFFF0', 'khaki': '#F0E68C', 'lavender': '#E6E6FA', 'lavenderblush': '#FFF0F5', 'lawngreen': '#7CFC00', 'lemonchiffon': '#FFFACD', 'lightblue': '#ADD8E6', 'lightcoral': '#F08080', 'lightcyan': '#E0FFFF', 'lightgoldenrodyellow': '#FAFAD2', 'lightgray': '#D3D3D3', 'lightgreen': '#90EE90', 'lightgrey': '#D3D3D3', 'lightpink': '#FFB6C1', 'lightsalmon': '#FFA07A', 'lightseagreen': '#20B2AA', 'lightskyblue': '#87CEFA', 'lightslategray': '#778899', 'lightslategrey': '#778899', 'lightsteelblue': '#B0C4DE', 'lightyellow': '#FFFFE0', 'lime': '#00FF00', 'limegreen': '#32CD32', 'linen': '#FAF0E6', 'magenta': '#FF00FF', 'maroon': '#800000', 'mediumaquamarine': '#66CDAA', 'mediumblue': '#0000CD', 'mediumorchid': '#BA55D3', 'mediumpurple': '#9370DB', 'mediumseagreen': '#3CB371', 'mediumslateblue': '#7B68EE', 'mediumspringgreen': '#00FA9A', 'mediumturquoise': '#48D1CC', 'mediumvioletred': '#C71585', 'midnightblue': '#191970', 'mintcream': '#F5FFFA', 'mistyrose': '#FFE4E1', 'moccasin': '#FFE4B5', 'navajowhite': '#FFDEAD', 'navy': '#000080', 'oldlace': '#FDF5E6', 'olive': '#808000', 'olivedrab': '#6B8E23', 'orange': '#FFA500', 'orangered': '#FF4500', 'orchid': '#DA70D6', 'palegoldenrod': '#EEE8AA', 'palegreen': '#98FB98', 'paleturquoise': '#AFEEEE', 'palevioletred': '#DB7093', 'papayawhip': '#FFEFD5', 'peachpuff': '#FFDAB9', 'peru': '#CD853F', 'pink': '#FFC0CB', 'plum': '#DDA0DD', 'powderblue': '#B0E0E6', 'purple': '#800080', 'rebeccapurple': '#663399', 'red': '#FF0000', 'rosybrown': '#BC8F8F', 'royalblue': '#4169E1', 'saddlebrown': '#8B4513', 'salmon': '#FA8072', 'sandybrown': '#F4A460', 'seagreen': '#2E8B57', 'seashell': '#FFF5EE', 'sienna': '#A0522D', 'silver': '#C0C0C0', 'skyblue': '#87CEEB', 'slateblue': '#6A5ACD', 'slategray': '#708090', 'slategrey': '#708090', 'snow': '#FFFAFA', 'springgreen': '#00FF7F', 'steelblue': '#4682B4', 'tan': '#D2B48C', 'teal': '#008080', 'thistle': '#D8BFD8', 'tomato': '#FF6347', 'turquoise': '#40E0D0', 'violet': '#EE82EE', 'wheat': '#F5DEB3', 'white': '#FFFFFF', 'whitesmoke': '#F5F5F5', 'yellow': '#FFFF00', 'yellowgreen': '#9ACD32'}
pandas에서 seaborn으로 그래프 그리기
matplotlib은 사실 꽤 저수준의 라이브러리다. 데이터를 어떻게 보여줄 것인지부터 (선그래프, 막대그래프, 산포도 등) 범례와 제목, 눈금 라벨, 주석 같은 기본 컴포넌트로 그래프를 작성해야 한다.
판다스를 사용하다 보면 로우와 칼럼 라벨을 가진 다양한 칼럼의 데이터를 다루게 된다. 판다스는 시리즈와 데이터프레임 객체를 간단하게 시각화할 수 있는 내장 메서드를 제공한다. 다른 라이브러리로는 마이클 와스콤Michael Waskom이 만든 통계 그래픽 라이브러리인 seaborn이 있다. seaborn은 흔히 사용하는 다양한 시각화 패턴을 쉽게 구현할 수 있도록 도와준다.
seaborn은 matplotlib을 기반으로 만들었지만, 판다스와의 쉬운 연동, 더 함축적인 API, 분석을 위한 다양한 유형의 그래프/차트 제공 등으로 파이썬 기반의 데이터 분석가/과학자에게 인기를 얻고 있다. 하지만 seaborn을 사용하기 위해서는 matplotlib을 어느 정도 알고 있어야 한다. seaborn이 matplotlib의 API를 이용해 더 함축적으로 만든 라이브러리지만, 여전히 세밀한 부분의 제어는 matplotlib의 API를 그대로 사용하고 있기 때문이다.
seaborn 라이브러리를 임포트하면 더 나은 가독성과 미려함을 위해 matplotlib의 기본 컬러 스킨과 플롯 스타일을 변경한다. 일부 분석가/개발자는 seaborn API를 사용하지 않더라도 일반적인 matplotlib 그래프의 스타일을 개선하기 위한 간편한 방법으로 seaborn 라이브러리를 임포트하는 것을 선호하곤 한다.
차트
차트의 5대 기법
-
Comparison and Ranking
-
Part to whole
-
Trend
-
Correlation
-
Distribution
차트의 5대 기법으로 나누어 각 범주를 대표하는 차트를 나눠서 작성했지만, 꼭 이 차트가 해당 범주에만 속하는 것이 아닌 여러 범주에 속할 수 있다. 예를 들어, Pareto Chart 같은 경우 Comparision and Ranking 부분에 작성했지만, Distribution 부분의 Histogram 에 속할 수도 있으므로 반드시 한 부분에 속한다는 관념은 벗어두자.
Comparison and Ranking
Bar Chart
막대 그래프는 통계를 낼 때 데이터의 값(아이템, 시계열 등)의 크기에 비례한 높이를 갖는 막대로 표현한 그래프를 말한다. 막대 높이의 상대적 길이 차이를 통해 값의 크고 작음을 설명한다. 크고 작음을 한 눈에 이해할 수 있기 때문에 이해하기엔 가장 편리하다. 다만 시간의 흐름에 따라 변하는 내용을 표현하는 것은 주로 꺾은선그래프가 이용된다.
막대 그래프의 표현은 막대를 세로로 할 수도 있고 가로로 할 수도 있다. 세로형 막대 그래프는 시계열 데이터를 표현하는데 적합하지만, 정보 제공 측면에서 보면 선 그래프와 큰 차이가 없다. 가로형 막대 그래프는 각 변수 사이 값의 크기 차이를 설명하는데 적합하다. 참고로 가독성 면에선 항목이 적을수록 가로가 좋고 항목이 많을수록 세로가 좋다.
막대그래프는 여러 값을 비교하는 데 적합하다. 차원 축에는 비교하는 범주 항목이 표시되고 측정값 축에는 각 범주 항목에 대한 값이 표시된다. 막대를 그룹화 및 누적하면 그룹화된 데이터를 시각화하기 쉬워진다. 또한 막대그래프는 값을 나란히 비교하는 경우(예: 여러 연도에 대해 판매량을 예상 판매량과 비교하는 경우) 및 동일한 단위를 사용하여 측정값(이 경우에는 판매량 및 예상 판매량)을 계산하는 경우에도 유용하다.
장점: 쉽게 판독하고 이해할 수 있으며 값의 개요를 한눈에 파악할 수 있다.
단점: 축 길이의 한계로 인해 차원 값이 많으면 잘 작동하지 않는다. 차원이 맞지 않으면 스크롤 막대를 사용하여 스크롤할 수 있지만 전체적인 그림을 보지 못할 수 있다.Qlik.com
plot.bar()와 plot.barh()는 각각 수직막대그래프와 수평막대그래프를 그린다. 이 경우 시리즈 또는 데이터프레임의 인덱스는 수직막대그래프(bar)인 경우 x 눈금, 수평막대그래프(barh)인 경우 y 눈금으로 사용된다.
fig, axes = plt.subplots(2, 1, constrained_layout=True)
data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))
data.plot.bar(ax=axes[0], color='k', alpha=0.7, rot=0)
data.plot.barh(ax=axes[1], color='k', alpha=0.7)
axes[0].set_title('Vertical bar chart')
axes[1].set_title('Horizontal bar chart')
plt.show()

color=’k’ 옵션과 alpha=0.7 옵션은 그래프를 검은색으로 그래고 투명도를 0.7로 지정한 것이다.
참고로 막대그래프를 그릴 때 유용한 방법은 시리즈의 value_counts() 메서드(s.value.counts().plot.bar())를 이용해서 값의 빈도를 그리는 것이다.
데이터프레임에서 막대그래프는 각 로우의 값을 함께 묶어서 하나의 그룹마다 각각의 막대를 보여준다.
df = pd.DataFrame(np.random.rand(6, 4),
index=['one', 'two', 'three', 'four', 'five', 'six'],
columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
display(df)
fig, axes = plt.subplots(1, 2)
df.plot.bar(ax=axes[0])
df.plot.barh(ax=axes[1])
plt.show()
| Genus | A | B | C | D |
|---|---|---|---|---|
| one | 0.185695 | 0.668232 | 0.067356 | 0.518719 |
| two | 0.064528 | 0.534620 | 0.424102 | 0.445191 |
| three | 0.343406 | 0.153433 | 0.839269 | 0.098026 |
| four | 0.058920 | 0.654207 | 0.699364 | 0.206360 |
| five | 0.088163 | 0.580463 | 0.717569 | 0.013099 |
| six | 0.213427 | 0.223794 | 0.052189 | 0.452506 |

데이터프레임의 칼럼 이름인 ‘Genus’가 범례의 제목으로 사용되었음을 확인하자.
누적막대그래프는 stacked=True 옵션을 사용해서 생성할 수 있는데, 각 로우의 값들이 하나의 막대에 누적되어 출력된다. 또한 plot() 메서드에 kind 옵션을 지정해서 다음과 동일한 결과를 얻을 수 있으니 참고하도록 하자.
fig, axes = plt.subplots(2, 1, constrained_layout=True)
df.plot(kind='bar', ax=axes[0], stacked=True, alpha=0.5, rot=0)
#df.plot.bar(ax=axes[0], stacked=True, alpha=0.5)
df.plot(kind='barh', ax=axes[1], stacked=True, alpha=0.5)
#df.plot.barh(ax=axes[1], stacked=True, alpha=0.5)
plt.show()

앞서 공부했던 내용에서 다뤘던 팁 데이터를 다시 살펴보자. 이 데이터에서 요일별 파티 숫자를 뽑고 파티 숫자 대비 팁 비율을 보여주는 막대그래프를 그려보자. read_csv() 메서드를 사용해서 데이터를 불러오고 요일과 파티 숫자에 따라 교차 테이블을 생성했다.
tips = pd.read_csv('examples/tips.csv')
party_counts = pd.crosstab(tips['day'], tips['size'])
display(party_counts)
# 1인과 6인 파티는 제외
party_counts = party_counts.loc[:, 2:5]
display(party_counts)
| size | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| day | ||||||
| Fri | 1 | 16 | 1 | 1 | 0 | 0 |
| Sat | 2 | 53 | 18 | 13 | 1 | 0 |
| Sun | 0 | 39 | 15 | 18 | 3 | 1 |
| Thur | 1 | 48 | 4 | 5 | 1 | 3 |
| size | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| day | ||||
| Fri | 16 | 1 | 1 | 0 |
| Sat | 53 | 18 | 13 | 1 |
| Sun | 39 | 15 | 18 | 3 |
| Thur | 48 | 4 | 5 | 1 |
그리고 각 로우의 합이 1이 되도록 정규화하고 그래프를 그려보자. 참고로 막대 정렬 순서는 그래프를 만드는데 사용한 데이터프레임의 인덱스 순서에 따라 정해지므로 원하는 순서가 있다면 reindex()로 인덱스를 재배치를 한다. 혹시 값의 크기순으로 정렬하고 싶다면 그래프를 만들기 전에 sort_values()를 이용해 데이터프레임을 내림차순으로 정렬해 놓은 후 그래프를 만들면 된다.
# 합이 1이 되도록 정규화
party_pcts = party_counts.div(party_counts.sum(1), axis=0).reindex(pd.Index(['Thur', 'Fri', 'Sat', 'Sun']))
display(party_pcts)
party_pcts.plot.bar()
plt.title('Party size by day of the week')
plt.show()
| size | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| Thur | 0.827586 | 0.068966 | 0.086207 | 0.017241 |
| Fri | 0.888889 | 0.055556 | 0.055556 | 0.000000 |
| Sat | 0.623529 | 0.211765 | 0.152941 | 0.011765 |
| Sun | 0.520000 | 0.200000 | 0.240000 | 0.040000 |

이 데이터에서 파티의 규모는 주말에 커지는 경향이 있음을 알 수 있다.
그래프를 그리기 전에 요약을 해야 하는 데이터는 seaborn 패키지를 이용하면 훨씬 간단하게 처리할 수 있다. 이번에는 seaborn 패키지로 팁 데이터를 다시 그려보자.
import seaborn as sns
tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip'])
display(tips.head())
fig = plt.figure()
# orient='h' 옵션으로 수평그래프
sns.barplot(x='tip_pct', y='day', data=tips, orient='h')
plt.title('Tip ratio graph by day of the week, including error bars')
plt.show()
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.063204 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.191244 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.199886 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.162494 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.172069 |

seaborn은 barplot() 함수를 사용할 때 각 막대에 기본적으로 오차막대(error bar)가 함께 나타나도록 되어 있다.
그리고 이 오차막대를 그리는 범위는 기본적으로 ‘부트스트랩 신뢰구간(Bootstrap confidence interval)’이라는 것을 사용한다. “이 데이터를 기반으로 유사한 상황의 95 %가 이 범위 내에서 결과를 얻을 것”을 의미한다. 이 신뢰 구간은 평균(mean) 외에도 중앙값(median), 최빈값(mode) 등의 다른 값들을 함께 고려해서 계산하는 것이기 때문에 꽤나 훌륭한 수치라고 봐도 된다.
아무튼 워라밸
seaborn 플로팅 함수의 data 인자는 판다스의 데이터프레임을 받는다. 다른 인자들은 칼럼 이름을 참조한다. day 칼럼의 각 값에 대한 데이터는 여럿 존재하므로 tip_pct의 평균값으로 막대그래프를 그린다. 막대그래프 위에 덧그려진 검은 선은 95%의 신뢰구간을 나타낸다(이 값은 ci 옵션으로 설정 가능하다).
seaborn.barplot() 메서드의 hue 옵션을 이용하면 추가 분류에 따라 나눠 그릴 수 있다.
fig = plt.figure()
sns.barplot(x='tip_pct', y='day', hue='time', data=tips, orient='h')
plt.title('Percentage of tips by day of the week and time')
plt.show()

sns.barplot() 에 estimator 옵션으로 집계 방법을 변경할 수 있다. 예를 들어 중앙값은 estimator=np.median 으로 처리하고, 빈도수는 estimator=len 으로 처리할 수 있다.
sns.barplot() 대신 sns.countplot()을 이용하면 앞서 설명했듯이 value_counts()를 이용해 칼럼별 데이터의 빈도수를 구하는 작업을 생략하고 원자료를 이용해 곧바로 빈도 막대 그래프를 만들 수 있다.
sns.countplot(data=tips, x='day');

sns.countplot()으로 만든 그래프의 막대를 정렬하려면 order 옵션에 원하는 순서로 값을 입력하면 된다. 물론 sns.barplot()에도 똑같이 적용된다.
sns.countplot(data=tips, x='day', order=['Thur', 'Fri', 'Sat', 'Sun']);

sns.countplot()의 order 옵션에 tips['day'].value_counts().index 를 입력하면 day의 빈도가 높은 순으로 막대를 정렬한다. .value_counts().index는 빈도가 높은 순으로 변수의 값을 출력하는 기능을 한다.
# day의 값을 빈도가 높은 순으로 출력
tips['day'].value_counts().index
Index(['Sat', 'Sun', 'Thur', 'Fri'], dtype='object')
# day 빈도 높은 순으로 세로형 막대 정렬
tips_countplot = sns.countplot(data=tips, x='day',
order=tips['day'].value_counts().index)
tips_countplot.set_title('count by day', fontsize=18)
tips_countplot.set_xlabel('Day', fontdict={'size': 16})
tips_countplot.set_ylabel('Count', fontdict={'size': 16})
plt.show()

# day 빈도 높은 순으로 가로형 막대 정렬
tips_countplot = sns.countplot(data=tips, y='day',
order=tips['day'].value_counts().index)
tips_countplot.set_title('count by day', fontsize=18)
tips_countplot.set_xlabel('Count', fontdict={'size': 16})
tips_countplot.set_ylabel('Day', fontdict={'size': 16})
plt.show()

# day 빈도 높은 순으로 막대 정렬 (hue='smoker')
tips_countplot = sns.countplot(data=tips, x='day',
order=tips['day'].value_counts().index,
hue='smoker')
tips_countplot.set_title('count by day', fontsize=18)
tips_countplot.set_xlabel('Day', fontdict={'size': 16})
tips_countplot.set_ylabel('Count', fontdict={'size': 16})
plt.show()

다음 예제는 위와 비슷하지만, 축 방향으로 hue 변수를 분리하지 않고 위로 쌓아 올리는 누적 그래프로 출력했다. 그래프 색 구성을 다르게 하려면 palette 옵션으로 변경하여 적용한다.
# dodge=False 옵션 추가(축 방향으로 분리하지 않고 누적 그래프로 출력)
tips_countplot = sns.countplot(data=tips, x='day',
order=tips['day'].value_counts().index,
hue='smoker',
palette='Set3',
dodge=False)
tips_countplot.set_title('count by day', fontsize=18)
tips_countplot.set_xlabel('Day', fontdict={'size': 16})
tips_countplot.set_ylabel('Count', fontdict={'size': 16})
plt.show()

seaborn 라이브러리는 자동으로 기본 색상 팔레트, 그래프 배경, 그리드 선 색상 같은 꾸밈새를 변경한다. seaborn.set() 메서드를 이용해서 이런 꾸밈새를 변경할 수 있다.
sns.set(style="whitegrid")
Dual Axis and Pareto chart
지금까지 그래프를 그릴 때 y축을 한 개만 사용하였다. Dual Axis chart는 y축에 보조 축을 추가하여 1개의 x축에 2개의 y축을 동시에 표시하는 방법을 말한다. Pareto chart는 문제의 원인을 가장 중요한 것에서 가장 덜 중요한 것으로 분류하는 그래픽 도구로, 80%의 결과가 가능한 원인의 20%에서 비롯된다는 파레토 원리를 기반으로 한다. 이는 관찰자가 결과에 가장 큰 영향을 미치는 인자를 이해하는 데 도움을 준다.
남북한 발전량 데이터셋을 사용하여 보조 축을 설정하는 방법을 살펴보자. 기존 축에는 막대 그래프의 값을 표시하고 보조 축에는 선 그래프의 값을 표시한다. 막대 그래프는 연도별 북한의 발전량을 나타내고 선 그래프는 북한 발전량의 전년 대비 증감률을 백분률로 나타낸다.
증감률을 계산하기 위해 rename() 메서드로 ‘합계’열의 이름을 ‘총발전량’으로 바꾸고, shift() 메서드를 이용하여 ‘총발전량’ 열의 데이터를 1행씩 뒤로 이동시켜서 ‘총발전량 - 1년’열을 새로 생성한다. 그리고 두 열의 데이터를 이용하여 전년도 대비 변동율을 계산한 결과를 ‘증감률’열에 저장한다.
ax1 객체는 막대 그래프에 stacked=True 옵션을 지정하여, ‘수력’, ‘화력’ 열의 값을 아래 위로 쌓은 형태의 세로형 막대 그래프를 그린다. ax1 객체에 twinx() 메서드를 적용하여 ax1 객체의 쌍둥이 객체를 만들고, 쌍둥이 객체를 ax2 변수에 저장한다. ax2 객체에 plot() 메서드를 적용하여 선 그래프를 그린다. 그래프를 그리는데 사용할 데이터는 ‘증감률’ 열에서 가져온다.
# matplotlib 한글 폰트 오류 문제 해결
from matplotlib import font_manager, rc
font_path = './malgun.ttf' # 폰트 파일 위치
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
plt.style.use('ggplot') # 스타일 서식 지정
plt.rcParams['axes.unicode_minus'] = False # 마이너스 부호 출력 설정
# Excel 데이터를 데이터프레임으로 변환
df = pd.read_excel('./남북한발전전력량.xlsx')
df = df.loc[5:9] # 북한의 데이터만 가져옴
df.drop('전력량 (억㎾h)', axis='columns', inplace=True)
df.set_index('발전 전력별', inplace=True)
df = df.rename(columns={'수력':'water power'})
df = df.T
# 증감률(변동률) 계산
df = df.rename(columns={'합계':'총발전량'})
df['총발전량 - 1년'] = df['총발전량'].shift()
df['증감률'] = ((df['총발전량']/df['총발전량 - 1년']) - 1) * 100
# 2축 그래프 그리기
ax1 = df[['수력', '화력']].plot(kind='bar', figsize=(20, 10), width=0.7, stacked=True)
ax2 = ax1.twinx()
ax2.plot(df.index, df.증감률, ls='--', marker='o', markersize=20,
color='red', label='전년대비 증감률(%)')
ax1.set_ylim(0, 500)
ax2.set_ylim(-50, 50)
ax1.set_xlabel('연도', size=20)
ax2.set_ylabel('발전량(억 KWh)')
ax2.set_ylabel('전년 대비 증감률(%)')
plt.title('북한 전력 발전량 (1990~2016)', size=30)
ax1.legend(loc='upper left', fontsize=16)
plt.show()

2015년 수력 발전량이 일시적으로 급감한 사실이 있다. 기사를 검색해 보면 2015년에 북한의 가뭄이 심각했다는 뉴스를 찾아볼 수 있다.
다음은 차량 통행 데이터로 Pareto Chart를 표현한 것이다. 서울에서 출발해서 도착하는 지점의 영업소 코드로 통행횟수를 알 수 있다. 위의 예시와 마찬가지로 보조 축을 생성하고 cumsum() 메서드로 누적 비율을 구해서 선그래프로 나타냈다.
# Data 준비
data = pd.read_csv('datasets/data_2020.csv')
data_destination_counting = data['도착영업소코드'].value_counts()
x = data_destination_counting.index
x = [str(i) for i in x]
y = data_destination_counting.values
ratio = y / y.sum()
ratio_sum = ratio.cumsum()
# Pareto Chart 그리기
fig, barChart = plt.subplots(figsize=(20, 10))
barChart.bar(x, y)
lineChart = barChart.twinx()
lineChart.plot(x, ratio_sum, '-bo', alpha=0.5)
ranges = lineChart.get_yticks()
lineChart.set_yticklabels(['{0:,.1%}'.format(x) for x in ranges])
ratio_sum_percentages = ['{0:.0%}'.format(x) for x in ratio_sum]
for i, txt in enumerate(ratio_sum_percentages):
lineChart.annotate(txt, (x[i], ratio_sum[i]), fontsize=14)
barChart.set_xlabel('도착 영업소 코드', fontdict={'size':16})
barChart.set_ylabel('통행횟수', fontdict={'size':16})
plt.title('Pareto Chart', fontsize=18)
plt.show()
C:\Users\Sangjin\AppData\Local\Temp\ipykernel_101584\2130087102.py:16: UserWarning: FixedFormatter should only be used together with FixedLocator
lineChart.set_yticklabels(['{0:,.1%}'.format(x) for x in ranges])

파레토 법칙처럼 앞에서부터 4개의 도착 영업소 코드의 누적합이 80%가 되는 것을 확인할 수 있다. 4개의 영업소 코드(105, 110, 115, 140)는 각각 기흥, 목천, 대전, 부산으로 서울에서 출발하는 차량의 80%는 기흥, 목천, 대전 그리고 부산을 가는 것을 알 수 있다.
Part to Whole
Pie Chart
파이 차트(pie chart)는 원을 파이 조각처럼 나누어서 표현한다. 조각의 크기는 해당 변수에 속하는 데이터 값의 크기에 비례한다. plot() 메서드에 kind=’pie’ 옵션을 사용하여 그린다.
예제에서는 데이터 개수를 세기 위해 숫자 1을 원소로 갖는 ‘count’ 열을 먼저 만든다. 그리고 groupby() 메서드를 사용하여 데이터프레임 df의 모든 데이터를 ‘origin’ 열 값인 ‘1’(=USA), ‘2’(=EU), ‘3’(=JPN)을 기준으로 3개의 그룹으로 나눈다. sum() 메서드로 각 그룹별 합계를 집계하여 df_origin 변수에 저장한다. 그룹 연산에 대해서는 다음에 다룰 예정이다.
각 제조국가별로 데이터 값들의 합계가 계산되는데, 우리가 필요한 데이터는 ‘count’ 열이다. 여기에 plot() 메서드를 적용하면 국가별 점유율을 나타내는 파이 차트를 그린다. ‘%1.1f%%’ 옵션은 숫자를 퍼센트(%)로 나타내는데, 소수점 이하 첫째자리까지 표기한다는 뜻이다.
plt.style.use('default') # 스타일 서식 지정
# read_csv() 함수로 df 생성
df = pd.read_csv('auto-mpg.csv', header=None)
# 열 이름 지정
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight',
'acceleration', 'model year', 'origin', 'name']
# 데이터 개수 카운트를 위해 값 1을 가진 열 추가
df['count'] = 1
df_origin = df.groupby('origin').sum() # origin 열을 기준으로 그룹화, 합계 연산
print(df_origin.head()) # 그룹 연산 결과 출력
# 제조국가(origin) 값을 실제 지역명으로 변경
df_origin.index = ['USA', 'EU', 'JPN']
# 제조국가(origin) 열에 대한 파이 차트 그리기 - count 열 데이터 사용
df_origin['count'].plot(kind='pie',
figsize=(7, 5),
autopct='%1.1f%%', # 퍼센트 % 표시
startangle=10, # 파이 조각을 나누는 시작점(각도 표시)
colors=['chocolate', 'bisque', 'cadetblue'], # 색상 리스트
shadow=True, # 그림자 추가
explode=[0.2, 0, 0], # 넘침의 정도
counterclock=True # 반시계 방향
)
plt.title('Model Origin', size=20)
plt.axis('equal') # 파이 차트의 비율을 같게(원에 가깝게) 조정
plt.legend(labels=df_origin.index, loc='upper right') # 범례 표시
plt.show()
mpg cylinders displacement weight acceleration model year \
origin
1 5000.8 1556 61229.5 837121.0 3743.4 18827
2 1952.4 291 7640.0 169631.0 1175.1 5307
3 2405.6 324 8114.0 175477.0 1277.6 6118
count
origin
1 249
2 70
3 79

사실 위 코드는 다음과 같이 편하게 나타낼 수 있다.
df['origin'].value_counts().plot(kind='pie',
figsize=(7, 5),
autopct='%1.1f%%',
startangle=10,
colors=['chocolate', 'bisque', 'cadetblue'],
shadow=True,
explode=[0.2, 0, 0],
counterclock=True)
Trend
Line Chart
선 그래프(line plot)는 연속하는 데이터 값들을 직선 또는 곡선으로 연결하여 데이터 값 사이의 관계를 나타낸다. 특히 시계열 데이터와 같이 연속적인 값의 변화와 패턴을 파악하는데 적합하다. 예를 들어 환율, 주가지수 등 경제지표가 시간에 따라 변하는 양상을 선 그래프로 표현할 수 있다.
시리즈와 데이터프레임은 둘 다 plot() 메서드를 이용해 다양한 형태의 그래프를 생성할 수 있다. 기본적으로 plot() 메서드는 선그래프를 생성한다.
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
s.plot();

시리즈 객체의 인덱스는 matplotlib에서 그래프를 생성할 때 x축으로 해석되며 use_index=False 옵션을 넘겨서 인덱스를 그래프의 축으로 사용하는 것을 막을 수 있다. x축의 눈금과 범위는 xticks 와 xlim 옵션으로 조절할 수 있으며 y축 역시 yticks 와 ylim 옵션으로 조절할 수 있다.
대부분의 판다스 그래프 메서드는 부수적으로 ax 인자를 받는데, 이 인자는 matplotlib의 서브플롯 객체가 될 수 있다. 이를 이용해 그리드 배열 상에서 서브플롯의 위치를 좀 더 유연하게 가져갈 수 있다.
데이터프레임의 plot() 메서드는 하나의 서브플롯 안에 각 칼럼별로 선그래프를 그리고 자동적으로 범례를 생성한다.
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0),
columns=['A', 'B', 'C', 'D'],
index=np.arange(0, 100, 10))
df.plot();

plot 속성에는 다양한 종류의 그래프 패밀리가 존재한다. 예를 들어 df.plot()은 df.plot.line()과 동일하다.
plot() 메서드에 전달할 수 있는 부수적인 키워드 인자들은 그대르 matplotlib의 함수로 전달된다. 따라서 matplotlib API를 자세히 공부하면 더 다양한 방식으로 그래프를 꾸밀 수 있다.
다음은 시리즈의 plot() 메서드 인자를 정리한 것이다.
| 인자 | 설명 |
|---|---|
| label | 그래프의 범례 이름 |
| ax | 그래프를 그릴 matplotlib의 서브플롯 객체. 만약 아무것도 넘어오지 않으면 현재 활성화되어 있는 matplotlib의 서브플롯을 사용한다. |
| style | matplotlib에 전달할 'ko--' 같은 스타일 문자열 |
| alpha | 그래프 투명도(0부터 1까지) |
| kind | 그래프 종류. 'area', 'bar', 'barh', 'density', 'hist', 'kde', 'line', 'pie' |
| logy | y축에 대한 로그 스케일링 |
| use_index | 객체의 인덱스를 눈금 이름으로 사용할지 여부 |
| rot | 눈금 이름을 로테이션(0부터 360까지) |
| xticks | x축으로 사용할 값 |
| yticks | y축으로 사용할 값 |
| xlim | x축 범위(예: [0, 10]) |
| ylim | y축 범위 |
| grid | 축의 그리드를 표시할지 여부(기본값은 True) |
데이터프레임에는 칼럼을 쉽게 다루기 위한 몇 가지 옵션이 있는데, 예를 들어 모든 칼럼을 같은 서브플롯에 그릴 것인지 아니면 각각의 서브플롯을 따로 만들 것인지 지정할 수 있다. 다음 데이터프레임의 plot() 메서드 인자의 옵션을 정리한 표를 보자.
| 인자 | 설명 |
|---|---|
| subplots | 각 데이터프레임의 칼럼을 독립된 서브플롯에 그린다. |
| sharex | subplots=True인 경우 같은 x축을 공유하고 눈금과 범위를 연결한다. |
| sharey | subplots=True인 경우 같은 y축을 공유한다. |
| figsize | 생성될 그래프의 크기를 튜플로 지정한다. |
| title | 그래프의 제목을 문자열로 지정한다. |
| legend | 서브플롯의 범례를 추가한다(기본값은 True). |
| sort_columns | 칼럼을 알파벳 순서로 그린다. 기본값은 존재하는 칼럼 순서 |
시계열 데이터
일별 환율처럼, 일정 시간 간격을 두고 나열된 데이터를 시계열 데이터time series data라 하고, 시계열 데이터를 선으로 표현한 그래프를 시계열 그래프time series chart라고 한다. 시계열 데이터에 대한 자세한 내용은 후에 알아볼 예정이므로 지금은 선 그래프가 시계열 데이터에 쓰이는 방법에 대한 맛보기 정도라고 생각하자.
미국의 여러 가지 경제 지표를 월별로 나타낸 데이터인 ‘economics’를 이용해 시계열 그래프를 만들어보고 시간에 따라 실업자 수가 어떻게 변하는지 파악해보자.
# economics 데이터 불러오기
economics = pd.read_csv('economics.csv')
# 'date' 칼럼의 데이터형을 문자(object)에서 날짜 시간 타입(datetime64)로 변경
economics['date'] = pd.to_datetime(economics['date'])
# 연도 변수 추가
economics['year'] = economics['date'].dt.year
# x축 눈금 표시
plt.xticks(range(1970, 2016, 5))
# x축에 연도 표시, 신뢰구간(confidence interval; ci) 제거
sns.lineplot(data=economics, x='year', y='unemploy', ci=None);

출력된 그래프를 보면 실업자 수가 약 5년 주기로 등락을 반복하고, 2005년부터 급격하게 증가했다가 2010년부터 다시 감소하는 추세라는 것을 알 수 있다.
다음 예시는 통계청에서 제공하는 시도 간 인구 이동 데이터셋을 이용한 선 그래프 활용이다. 데이터셋을 원하는 방향으로 전처리 한 후 그래프를 표시하고
annotate() 함수로 화살표와 텍스트 위치를 잡아서 배치한다. 위치를 나타내는 (x, y) 좌표에서 x값은 인덱스 번호를 사용한다. y 좌표값에 들어갈 인구수 데이터는 숫자값이므로 그대로 사용할 수 있다. 예를 들어 xy=(20, 62000)은 인덱스 번호 20을 x값으로 하고 62000명을 y값으로 한다는 뜻이다.
# Excel 데이터를 데이터프레임으로 변환
df = pd.read_excel('시도별 전출입 인구수.xlsx', header=0)
# 누락값(NaN)을 앞 데이터로 채움(엑셀 양식 병합 부분)
df = df.fillna(method='ffill')
# 서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis=1)
df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True)
df_seoul.set_index('전입지', inplace=True)
# 서울에서 경기도로 이동한 인구 데이터 값만 선택
sr_one = df_seoul.loc['경기도']
# 스타일 서식 지정
plt.style.use('ggplot')
# 그림 사이즈 지정(가로 14인치, 세로 5인치)
plt.figure(figsize=(14, 5))
# x축 눈금 라벨 회전하기
plt.xticks(rotation='vertical')
# x, y축 데이터를 plot 함수에 입력
plt.plot(sr_one, marker='o', markersize=10) # 마커 표시 추가
plt.title('서울 -> 경기 인구 이동') # 차트 제목
plt.xlabel('기간') # x축 이름
plt.ylabel('이동 인구수') # y축 이름
plt.legend(labels=['서울 -> 경기'], loc='best') # 범례 표시
# y축 범위 지정(최소값, 최대값)
plt.ylim([50000, 800000])
# 주석 표시 - 화살표
plt.annotate('',
xy=(20, 620000), # 화살표의 머리 부분(끝점)
xytext=(2, 290000), # 화살표의 꼬리 부분(시작점)
xycoords='data', # 좌표체계
arrowprops=dict(arrowstyle='->', color='skyblue', lw=5), # 화살표 서식
)
plt.annotate('',
xy=(47, 450000), # 화살표의 머리 부분(끝점)
xytext=(30, 580000), # 화살표의 꼬리 부분(시작점)
xycoords='data', # 좌표체계
arrowprops=dict(arrowstyle='->', color='olive', lw=5), # 화살표 서식
)
# 주석 표시 - 텍스트
plt.annotate('인구 이동 증가(1970-1995)', # 텍스트 입력
xy=(11, 380000), # 텍스트 위치 기준점
rotation=25, # 텍스트 회전 각도
va='baseline', # 텍스트 상하 정렬
ha='center', # 텍스트 좌우 정렬
fontsize=15, # 텍스트 크기
)
plt.annotate('인구 이동 감소(1995-2017)', # 텍스트 입력
xy=(39, 490000), # 텍스트 위치 기준점
rotation=-11, # 텍스트 회전 각도
va='baseline', # 텍스트 상하 정렬
ha='center', # 텍스트 좌우 정렬
fontsize=15, # 텍스트 크기
)
plt.show() # 변경사항 저장하고 그래프 출력

우리나라 인구의 절반이 산다는 서울특별시와 경기도 간의 인구 이동 변화가 화살표 주석과 함께 선 그래프로 표시된다. 1990년대 중반까지 경기도권 5대 신도시(분당, 일산 등) 개발로 서울 인구의 대규모 경기도 유입이 있었음을 추정할 수 있다. 이 시기를 정점으로 서울을 벗어나 경기권으로 이동하는 인구는 현재까지 계속 감소하는 트렌드를 보이고 있다.
화면 분할하여 그래프 여러 개 그리기 - axe 객체 활용
화면을 여러 개로 분할하고 분할된 각 화면에 서로 다른 그래프를 그리는 방법이다. 여러 개의 axe 객체를 만들고, 분할된 화면마다 axe 객체를 하나씩 배정한다. axe 객체는 각각 서로 다른 그래프를 표현할 수 있다. 한 화면에서 여러 개의 그래프를 비교하거나 다양한 정보를 동시에 보여줄 때 사용하면 좋다. 단, axe 객체를 1개만 생성하는 경우에는 하나의 그래프만 표시된다.
figure() 함수를 사용하여 그래프를 그리는 그림틀(fig)을 만든다. figsize 옵션으로 (가로, 세로) 그림틀의 크기를 설정한다. fig 객체에 add_subplot() 메서드를 적용하여 그림틀을 여러 개로 분할한다. 이때 나눠진 각 부분을 axe 객체라고 부른다.
add_subplot() 메서드의 인자에 “행의 크기, 열의 크기, 서브플롯 순서”를 순서대로 입력한다. 예를 들어 ax1 = fig.add_subplot(2, 1, 1)의 코드는 앞의 두 숫자 중에서 2는 행의 개수를 의미하고, 1은 열의 개수를 나타낸다. 즉, fig를 2부분(2행x1열)으로 분할한다는 뜻이다. 3번째 숫자 1은 분할된 2부분(axe 객체) 중에서 1번째 부분(axe 객체)을 나타낸다.
각 axe 객체에 plot() 메서드를 적용하여 그래프를 출력한다. 첫 번째 그래프(ax1)에 ‘o’ 옵션을 인자로 전달하여 선을 그리지 않고 점으로만 표시한다. 두 번째 그래프(ax2)에 marker=’o’ 옵션을 사용하여 원 모양의 마커를 가진 선 그래프가 된다. ax2 객체에는 label 옵션을 추가하고 legend() 메서드를 적용하여 범례를 표시한다. 또한 y축의 최소값, 최대값 한계를 설정하기 위해 set_ylim() 메서드를 사용한다. 연도를 나타내는 x축 눈금 라벨(1970~2017)의 글씨가 서로 겹치지 않도록 set_xticklabels() 메서드를 사용하여 글자를 반시계 방향으로 75º회전시킨다.
ax1 객체에 set_title() 메서드를 적용하여 제목을 추가하였고 set_ylabel() 메서드로 y축 이름을 지정하였다. ax2 객체에는 set_xlabel()과 set_ylabel() 메서드로 x축과 y축의 이름을 지정했고 tick_params() 메서드로 축 눈금 라벨의 크기를 조절하였다.
# Excel 데이터를 데이터프레임으로 변환
df = pd.read_excel('시도별 전출입 인구수.xlsx', header=0)
# 누락값(NaN)을 앞 데이터로 채움(엑셀 양식 병합 부분)
df = df.fillna(method='ffill')
# 서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis=1)
df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True)
df_seoul.set_index('전입지', inplace=True)
# 서울에서 경기도로 이동한 인구 데이터 값만 선택
sr_one = df_seoul.loc['경기도']
# 스타일 서식 지정
plt.style.use('ggplot')
# 그래프 객체 생성(figure에 2개의 서브 플롯 생성)
fig = plt.figure(figsize=(10, 10))
ax1 = fig.add_subplot(2, 1, 1)
ax2 = fig.add_subplot(2, 1, 2)
# axe 객체에 plot 함수로 그래프 출력
ax1.plot(sr_one, 'o', markersize=10)
ax2.plot(sr_one, marker='o', markerfacecolor='green', markersize=10,
color='olive', linewidth=2, label='서울 -> 경기')
ax2.legend(loc='best')
# 차트 제목 추가
fig.suptitle('서울 -> 경기 인구 이동', size=20)
# 축 이름 추가
ax2.set_xlabel('기간', size=12)
ax2.set_ylabel('인구 이동수', size=12)
ax1.set_ylabel('인구 이동수', size=12)
# y축 범위 지정(최소값, 최대값)
ax1.set_ylim([50000, 800000])
ax2.set_ylim([50000, 800000])
# 축 눈금 라벨 지정 및 75도 회전
ax1.set_xticklabels(sr_one.index, rotation=75)
ax2.set_xticklabels(sr_one.index, rotation=75)
# 축 눈금 라벨 크기
ax2.tick_params(axis="x", labelsize=10)
ax2.tick_params(axis="y", labelsize=10)
plt.show() # 변경사항 저장하고 그래프 출력

동일한 그림(axe 객체)에 여러 개의 그래프를 추가하는 것도 가능하다. 다음 예제에서는 서울특별시에서 충청남도, 경상북도, 강원도로 이동한 인구 변화 그래프 3개를 하나의 같은 화면에 그려본다. 먼저 각 지역에 해당하는 행을 선택하고, 동일한 axe 객체(ax)에 선 그래프로 출력하는 plot() 메서드를 3번 적용한다. 그리고 범례와 차트 제목 등을 표시한다.
# Excel 데이터를 데이터프레임으로 변환
df = pd.read_excel('시도별 전출입 인구수.xlsx', header=0)
# 누락값(NaN)을 앞 데이터로 채움(엑셀 양식 병합 부분)
df = df.fillna(method='ffill')
# 서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis=1)
df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True)
df_seoul.set_index('전입지', inplace=True)
# 서울에서 '충청남도', '경상북도', '강원도'로 이동한 인구 데이터 값만 선택
col_years = list(map(str, range(1970, 2018)))
df_3 = df_seoul.loc[['충청남도', '경상북도', '강원도'], col_years]
# 스타일 서식 지정
plt.style.use('ggplot')
# 그래프 객체 생성(figure에 1개의 서브 플롯 생성)
fig = plt.figure(figsize=(20, 5))
ax = fig.add_subplot(1, 1, 1)
# axe 객체에 plot 함수로 그래프 출력
ax.plot(col_years, df_3.loc['충청남도', :], marker='o', markerfacecolor='green',
markersize=10, color='olive', linewidth=2, label='서울 -> 충남')
ax.plot(col_years, df_3.loc['경상북도', :], marker='o', markerfacecolor='blue',
markersize=10, color='skyblue', linewidth=2, label='서울 -> 경북')
ax.plot(col_years, df_3.loc['강원도', :], marker='o', markerfacecolor='red',
markersize=10, color='magenta', linewidth=2, label='서울 -> 강원')
# 범례 표시
ax.legend(loc='best')
# 차트 제목 추가
ax.set_title('서울 -> 충남, 경북, 강원 인구 이동', size=20)
# 축 이름 추가
ax.set_xlabel('기간', size=12)
ax.set_ylabel('이동 인구수', size=12)
# 축 눈금 라벨 지정 및 90도 회전
ax.set_xticklabels(col_years, rotation=90)
# 축 눈금 라벨 크기
ax.tick_params(axis="x", labelsize=10)
ax.tick_params(axis="y", labelsize=10)
plt.show() # 변경사항 저장하고 그래프 출력

이처럼 같은 axe 객체에 그래프 여러 개를 동시에 표시할 수 있다. 서울에서 서로 다른 3개 지역으로 빠져나간 인구 이동을 비교 파악하기가 쉽다. 특히 지리적으로 가까운 충남 지역으로 이동한 인구가 다른 두 지역에 비해 많은 편이다. 전반적으로 1970~80년대에는 서울에서 지방으로 전출하는 인구가 많았으나, 1990년 이후로는 줄곧 감소하는 패턴을 보이고 있다.
서울특별시에서 충청남도, 경상북도, 강원도, 전라남도 4개 지역으로 이동한 인구 변화 그래프를 그려본다. ax1~ax4까지 4개의 axe 객체를 생성한다. 각 지역에 해당하는 4개의 행을 선택하고, axe 객체에 하나씩 plot() 메서드를 적용한다. 그리고 범례와 차트 제목 등을 표시한다.
# Excel 데이터를 데이터프레임으로 변환
df = pd.read_excel('시도별 전출입 인구수.xlsx', header=0)
# 누락값(NaN)을 앞 데이터로 채움(엑셀 양식 병합 부분)
df = df.fillna(method='ffill')
# 서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis=1)
df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True)
df_seoul.set_index('전입지', inplace=True)
# 필요한 리스트들
markerfacecolors = ['green', 'blue', 'red', 'orange']
colors = ['olive', 'skyblue', 'magenta', 'yellow']
area = ['충청남도', '경상북도', '강원도', '전라남도']
labels = ['서울 -> 충남', '서울 -> 경북', '서울 -> 강원', '서울 -> 전남']
# 서울에서 '충청남도', '경상북도', '강원도'로 이동한 인구 데이터 값만 선택
col_years = list(map(str, range(1970, 2018)))
df_4 = df_seoul.loc[area, col_years]
# 스타일 서식 지정
plt.style.use('ggplot')
# 그래프 객체 생성(figure에 1개의 서브 플롯 생성)
fig, axes = plt.subplots(2, 2, figsize=(20, 10), constrained_layout=True)
# axe 객체를 하나씩 참조해가며 생성
for i in range(len(axes)):
for j in range(len(axes[0])):
# axe 객체에 plot 함수로 그래프 출력
axes[i, j].plot(col_years, df_4.loc[area[i*len(axes[0])+j], :], marker='o',
markerfacecolor=markerfacecolors[i*len(axes[0])+j],
markersize=10, color=colors[i*len(axes[0])+j], linewidth=2,
label=labels[i*len(axes[0])+j])
# 범례 표시
axes[i, j].legend(loc='best')
# 차트 제목 추가
axes[i, j].set_title(labels[i*len(axes[0])+j] + ' 인구 이동')
# 축 눈금 라벨 지정 및 90도 회전
axes[i, j].set_xticklabels(col_years, rotation=90)
plt.show() # 변경사항 저장하고 그래프 출력

Area plot
면적 그래프(area plot)는 각 열의 데이터를 선 그래프로 구현하는데, 선 그래프와 x축 사이의 공간에 색이 입혀진다. 색의 투명도(alpha)는 기본값 0.5로 투과되어 보인다(투명도: 0~1 범위). 선 그래프를 그리는 plot() 메서드에 kind=’area’ 옵션을 추가하면 간단하게 그릴 수 있다.
그래프를 누적할지 여부를 설정할 수 있는데, 기본값은 stacked=True 옵션이다. 각 열의 선 그래프를 다른 열의 선 그래프 위로 쌓아 올리는 방식으로 표현된다. 각 열의 패턴과 함께 열 전체의 합계가 어떻게 변하는지 파악할 수 있게 된다. 따라서, 면적 그래프를 선 그래프를 확장한 개념으로 누적 선 그래프(stacked line plot)라고 부르기도 한다.
stacked=False 옵션을 지정하면 각 열의 선 그래프들이 누적되지 않고 서로 겹치도록 표시된다. 선 그래프를 동일한 화면에 여러 개를 그린 거소가 같은 결과가 된다.
다음 예제에서는 그래프를 간단하게 그리기 위해 데이터프레임에 바로 plot() 메서드를 적용한다. stacked=False 옵션을 지정하여 데이터를 누적하지 않는 unstacked 버전부터 그려본다. 서로 겹쳐지는 부분이 잘 투과되어 보이도록 alpha=0.2 옵션을 적용한다(기본값: 0.5).
# Excel 데이터를 데이터프레임으로 변환
df = pd.read_excel('시도별 전출입 인구수.xlsx', header=0)
# 누락값(NaN)을 앞 데이터로 채움(엑셀 양식 병합 부분)
df = df.fillna(method='ffill')
# 서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis=1)
df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True)
df_seoul.set_index('전입지', inplace=True)
# 서울에서 '충청남도', '경상북도', '강원도'로 이동한 인구 데이터 값만 선택
col_years = list(map(str, range(1970, 2018)))
df_5 = df_seoul.loc[['충청남도', '경상북도', '강원도'], col_years]
df_5 = df_5.transpose()
# 스타일 서식 지정
plt.style.use('ggplot')
# 데이터프레임의 인덱스를 정수형으로 변경(x축 눈금 라벨 표시)
df_5.index = df_5.index.map(int)
# 면적 그래프 그리기
fig, axes = plt.subplots(1, 2, figsize=(20, 10))
df_5.plot(ax=axes[0], kind='area', stacked=False, alpha=0.2, xlabel='기간', ylabel='이동 인구 수')
df_5.plot(ax=axes[1], kind='area', stacked=True, alpha=0.2, xlabel='기간')
# figure 전체 제목
fig.suptitle('서울 -> 타시도 인구 이동', size=30)
# 변경사항 저장하고 그래프 출력
plt.show()

Correlation
Scatter plot
산점도scatter plot, point plot는 서로 다른 두 변수 사이의 관계를 나타내고자 할 때 유용한 그래프다. 이때 각 변수는 연속되는 값을 갖고 일반적으로 정수형(int64) 또는 실수형(float64) 값이다. 2개의 연속 변수를 각각 x축과 y축에 하나씩 놓고, 데이터 값이 위치하는 (x, y) 좌표를 찾아서 점으로 표시한다.
두 연속 변수의 관계를 보여준다는 점에서 선 그래프와 비슷하다. 선 그래프를 그릴 때 plot() 메서드에 ‘o’ 옵션을 사용하면 선 없이 점으로만 표현되는데, 사실상 산점도라고 볼 수 있다.
plot() 메서드에 kind=’scatter’ 옵션을 사용하여 산점도를 그린다. x=’weight’ 옵션을 사용하여 x축에 위치할 변수(데이터프레임의 열)를 선택한다. 마찬가지로 y=’mpg’ 옵션을 지정하여 ‘mpg’열을 y축에 놓을 변수로 선택한다. 점의 색상(c)과 크기(s)를 설정하는 옵션을 추가한다.
plt.style.use('default') # 스타일 서식 지정
# read_csv() 함수로 df 생성
df = pd.read_csv('auto-mpg.csv', header=None)
# 열 이름 지정
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight',
'acceleration', 'model year', 'origin', 'name']
# 연비(mpg)와 차중(weight) 열에 대한 산점도 그리기
df.plot(kind='scatter', x='weight', y='mpg', c=df.origin, cmap='viridis', s=10, figsize=(10, 5))
plt.title('Scatter Plot - mpg vs weight')
plt.show()

Bubble chart
앞에서 자동차 무게와 연비 사이의 관계를 산점도로 표현하였다. 여기에 새로운 변수를 추가해서 점의 크기 또는 색상으로 표현할 수 있다. 여기서는 3번째 변수로 실린더 개수(‘cyliinders’ 열)를 추가해 보자.
실린더 개수를 나타내는 정수를 그대로 쓰는 대신, 해당 열의 최대값 대비 상대적 크기를 나타내는 비율을 계산하여 cylinders_size 변수에 저장한다. cylinders_size는 0~1 범위의 실수 값의 배열(시리즈)이다. 점의 크기를 정하는 s 옵션에 cylinders_size를 입력하여 값의 크기에 따라 점의 크기를 값에 따라 다르게 표시한다. 이처럼 점의 크기에 변화를 주면 모양이 비눗방울 같다고 해서 버블(bubble) 차트라고 부르기도 한다. 추가로 c 옵션에는 엔진을 만든 국가(‘origin’ 열)을 추가하여 값에 따라 색상을 다르게 표시한다.
# cylinders 개수의 상대적 비율을 계산하여 시리즈 생성
cylinders_size = df.cylinders / df.cylinders.max() * 300
# 3개의 변수로 산점도 그리기
df.plot(kind='scatter', x='weight', y='mpg', c=df.origin, cmap='viridis', figsize=(10, 5),
s=cylinders_size, alpha=0.3)
plt.title('Scatter Plot: mpg-weight-cylinders-origin')
plt.show()

statsmodels 프로젝트에서 macrodata 데이터 묶음을 불러온 다음 몇 가지 변수를 선택하고 로그차를 구해보자.
macro = pd.read_csv('examples/macrodata.csv')
data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]
trans_data = np.log(data).diff().dropna()
trans_data.tail()
| cpi | m1 | tbilrate | unemp | |
|---|---|---|---|---|
| 198 | -0.007904 | 0.045361 | -0.396881 | 0.105361 |
| 199 | -0.021979 | 0.066753 | -2.277267 | 0.139762 |
| 200 | 0.002340 | 0.010286 | 0.606136 | 0.160343 |
| 201 | 0.008419 | 0.037461 | -0.200671 | 0.127339 |
| 202 | 0.008894 | 0.012202 | -0.405465 | 0.042560 |
seaborn 라이브러리의 regplot() 함수는 서로 다른 2개의 연속 변수 사이의 산점도를 그리고 선형회귀분석에 의한 회귀선을 함께 나타낸다. fig_reg=False 옵션을 설정하면 회귀선을 안 보이게 할 수 있다.
# 스타일 테마 설정(5가지: darkgrid, whitegrid, dark, white, ticks)
sns.set_style('darkgrid')
# 그래프 객체 생성(figure에 2개의 서브 플롯 생성)
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
# 그래프 그리기 - 선형회귀선 표시(fit_reg=True)
sns.regplot(x='m1', # x축 변수
y='unemp', # y축 변수
data=trans_data, # 데이터
ax=ax1) # axe 객체 - 1번째 그래프
# 그래프 그리기 - 선형회귀선 미표시(fit_reg=False)
sns.regplot(x='m1', # x축 변수
y='unemp', # y축 변수
data=trans_data, # 데이터
ax=ax2, # axe 객체 - 2번째 그래프
fit_reg=False) # 회귀선 미표시
fig.suptitle('Changes in log %s versus log %s' % ('m1', 'unemp'), fontsize=20) # 전체 title 설정
plt.show() # 변경사항을 저장하고 그래프 표시

탐색 데이터 분석에서는 변수 그룹 간의 모든 산포도를 살펴보는 일이 매우 유용한데, 이를 짝지은 그래프 또는 산포도 행렬이라고 부른다. 이런 그래프를 직접 그리는 과정은 다소 복잡하기 때문에 seaborn에서는 pairplot() 함수를 제공하여 대각선을 다라 각 변수에 대한 히스토그램이나 밀도 그래프도 생성할 수 있다. pairplot() 함수는 인자로 전달되는 데이터프레임의 열(변수)을 두 개씩 짝을 지을 수 있는 모든 조합에 대해 표현한다. 그래프를 그리기 위해 만들어진 짝의 개수만큼 화면을 그리드로 나눈다.
다음 예제에서는 4개의 열을 사용하기 때문에 4행x4열 크기로 모두 16개의 그리드를 만든다. 각 그리드에 두 변수 간의 관계를 나타내는 그래프를 하나씩 그린다. 같은 변수끼리 짝을 이루는 대각선 방향으로는 히스토그램을 그리고 서로 다른 변수 간에는 산점도를 그린다.
sns.set(style='whitegrid')
sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha': 0.2})
plt.grid(True)
plt.show()

plot_kws 인자는 각각의 그래프에 전달할 개별 설정값을 지정한다. 설정 옵션에 관한 자세한 내용은 seaborn.pairplot 문서를 참고하자.
범주형 데이터의 산점도
범주형 변수에 들어 있는 각 범주별 데이터의 분포를 확인하는 방법이다. stripplot() 함수와 swarmplot() 함수를 사용할 수 있다. swarmplot() 함수는 데이터의 분산까지 고려하여, 데이터 포인트가 서로 중복되지 않도록 그린다. 즉, 데이터가 퍼져 있는 정도를 입체적으로 볼 수 있다.
# seaborn 제공 데이터셋 가져오기
titanic = sns.load_dataset('titanic')
# 스타일 테마 설정(5가지: darkgrid, whitegrid, dark, white, ticks)
sns.set(style='whitegrid')
# 그래프 객체 생성(figure에 2개의 서브 플롯 생성)
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
# 이산형 변수의 분포 - 데이터 분산 미고려
sns.stripplot(x="class", # x축 변수
y="age", # y축 변수
data=titanic, # 데이터셋 - 데이터프레임
ax=ax1) # axe 객체 - 1번째 그래프
# 이산형 변수의 분포 - 데이터 분산 고려(중복 X)
sns.swarmplot(x="class", # x축 변수
y="age", # y축 변수
data=titanic, # 데이터셋 - 데이터프레임
ax=ax2) # axe 객체 - 2번째 그래프
# 차트 제목 표시
ax1.set_title('Strip Plot')
ax2.set_title('Swarm Plot')
plt.show()

Heatmap
Seaborn 라이브러리는 히트맵(heatmap)을 그리는 heatmap() 메서드를 제공한다. 2개의 범주형 변수를 각각 x, y축에 놓고 데이터를 매트릭스 형태로 분류한다. 데이터프레임을 피벗테이블로 정리할 때 한 변수(‘sex’ 열)를 행 인덱스로 나머지 변수(‘class’ 열)를 열 이름으로 설정한다. aggfunc=’size’ 옵션은 데이터 값의 크기를 기준으로 집계한다는 뜻이다. 피벗테이블에 대해서는 다음에 자세히 알아본다.
# Seaborn 제공 데이터셋 가져오기
titanic = sns.load_dataset('titanic')
# 스타일 테마 설정(5가지: darkgrid, whitegrid, dark, white, ticks)
sns.set_style('darkgrid')
# 피벗테이블로 범주형 변수를 각각 행, 열로 재구분하여 정리
# table = pd.crosstab(titanic['sex'], titanic['class']) 와 같은 결과
table = titanic.pivot_table(index=['sex'], columns=['class'], aggfunc='size')
# 히트맵 그리기
sns.heatmap(table, # 데이터프레임
annot=True, fmt='d', # 데이터 값 표시 여부, 정수형 포맷
cmap='YlGnBu', # 컬러 맵
linewidth=.5, # 구분 선
cbar=False) # 컬러 바 표시 여부
plt.show() # 변경 사항 저장하고 그래프 출력

히트맵을 보면 타이타닉호에는 여자(female) 승객보다 남자(male) 승객이 상대적으로 많은 편이다. 특히 3등석 남자 승객의 수가 압도적으로 많은 것을 알 수 있다. 여기서는 cbar=False 옵션을 사용하여 컬러 바가 표시되지 않았는데, cbar=True 옵션으로 표시할 수도 있다.
Distribution
Histogram and Density graph
히스토그램(histogram)은 막대 그래프의 한 종류로, 변수가 하나인 단변수 데이터의 빈도수를 그래프로 표현한다. x축을 같은 크기의 여러 구간으로 나누고 각 구간에 속하는 데이터 값의 개수(빈도)를 y축에 표시한다. 구간을 나누는 간격의 크기에 따라 빈도가 달라지고 히스토그램의 모양이 변한다. 앞에서 살펴본 팁 데이터를 사용해서 전체 결제금액 대비 팁 비율을 시리즈의 plot.hist() 메서드를 사용해서 만들어보자.
# tips['tip_pct'].plot(kind='hist', bins=50);
tips['tip_pct'].plot.hist(bins=50);

이와 관련 있는 다른 그래프로 밀도 그래프가 있는데 밀도 그래프는 관찰값을 사용해서 추정되는 연속된 확률 분포를 그린다. 일반적인 과정은 kernel() 메서드를 잘 섞어서 이 분포를 근사하는 방법인데 이보다 단순한 정규 분포다. 그래서 밀도 그래프는 KDEKernel Density Estimate(커널 밀도 추정) 그래프라고도 알려져 있다. plot.kde()를 이용해서 밀도 그래프를 표준 KDE 형식으로 생성한다.
# tips['tip_pct'].plot(kind='density');
tips['tip_pct'].plot.density();

단변수(하나의 변수) 데이터의 분포를 확인할 때 seaborn 라이브러리의 distplot() 메서드를 이용해서 히스토그램과 밀도 그래프를 한 번에 손쉽게 그릴 수 있다. 기본값으로 히스토그램과 커널 밀도 함수1
hist=False 옵션을 추가하면 히스토그램이 표시되지 않고, kde=False 옵션을 전달하면 커널 밀도 그래프를 표시하지 않는다. 예를 들어 두 개의 다른 표준정규분포로 이루어진 양봉분포bimodal distribution를 생각해보자.
# 평균이 0, 표준편차가 1 인 정규분포에서 200개의 랜덤 추출
comp1 = np.random.normal(0, 1, size=200)
# 평균이 10, 표준편차가 2 인 정규분포에서 200개의 랜덤 추출
comp2 = np.random.normal(10, 2, size=200)
# shape: (400,)
values = pd.Series(np.concatenate([comp1, comp2]))
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 3, 1)
ax2 = fig.add_subplot(1, 3, 2)
ax3 = fig.add_subplot(1, 3, 3)
# 기본값
sns.distplot(values, bins=100, color='k', ax=ax1)
# hist=False
sns.distplot(values, bins=100, color='k', hist=False, ax=ax2)
# kde=False
sns.distplot(values, bins=100, color='k', kde=False, ax=ax3)
# 차트 제목 표시
ax1.set_title('bimodal distribution - hist/kde')
ax2.set_title('bimodal distribution - kde')
ax3.set_title('bimodal distribution - hist')
plt.show()

distplot()은 나중에 deprecated 될 예정이므로 seaborn 라이브러리에서는 displot() 이나 histplot()을 권장한다.
# sns.displot(values, bins=100, color='k', kde='kernel');
sns.displot(values, bins=100, color='k', kde=True);

# sns.histplot(values, bins=100, color='k', kde='kernel');
sns.histplot(values, bins=100, color='k', kde=True);

Box plot and Violin plot
박스 플롯(boxplot)은 데이터의 분포 또는 퍼져 있는 형태를 직사각형 상자 모양으로 표현한 그래프로 범주형 데이터의 분포를 파악하는데 적합하다. 다음 그림을 보면 박스 플롯은 5개의 통계 지표(최소값: 위 극단치 경계, 1분위값, 중간값, 3분위값, 최대값: 아래 극단치 경계)를 제공한다.
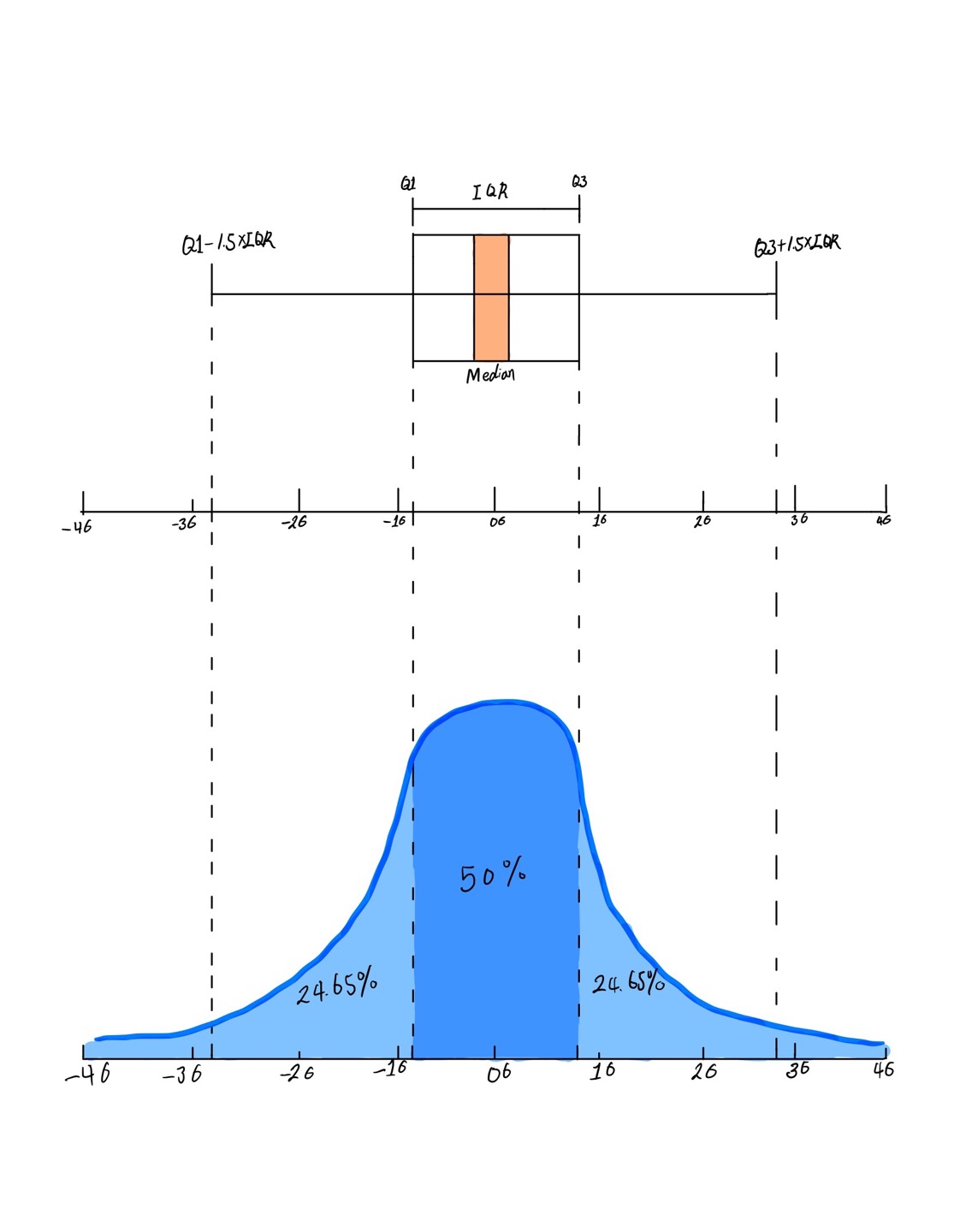
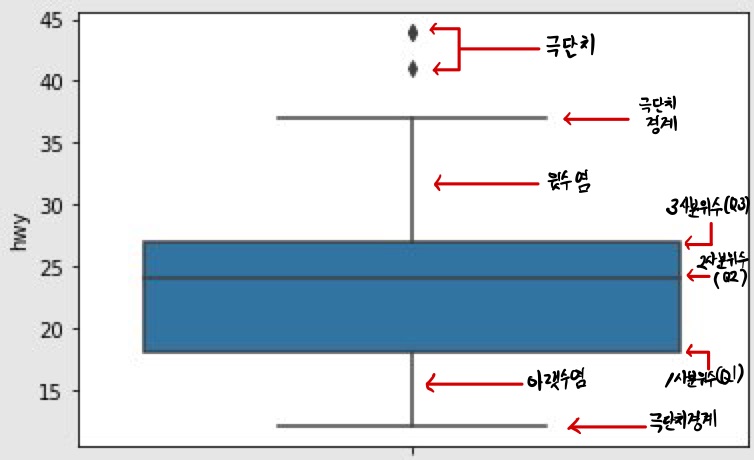
상자 그림은 값을 크기순으로 나열해 4등분 했을 때 위치하는 값인 ‘사분위수’를 이용해 만든다. 다음은 상자 그림의 요소가 나타내는 값이다.
| 상자 그림 | 값 | 설명 |
|---|---|---|
| 상자 아래 세로선 | 아랫수염 | 하위 0 ~ 25% 내에 해당하는 값 |
| 상자 밑면 | 1사분위수(Q1) | 하위 25% 위치 값 |
| 상자 내 굵은 선 | 2사분위수(Q2) | 하위 50% 위치 값(중앙값) |
| 상자 윗면 | 3사분위수(Q3) | 하위 75% 위치 값 |
| 상자 위 세로선 | 윗수염 | 하위 75 ~ 100% 내에 해당하는 값 |
| 상자 밖 가로선 | 극단치 경계 | Q1, Q3 밖 1.5 IQR 내 최대값 |
| 상자 밖 점 표식 | 극단치 | Q1, Q3 밖 1.5 IQR을 벗어난 값 |
‘IQR(사분위 범위)’은 1사분위수와 3사분위수의 거리를 뜻하고, ‘1.5 IQR’은 IQR의 1.5배를 뜻한다.
앞에서 출력한 상자 그림을 보면 hwy 값을 크기순으로 나열했을 때 하위 25% 지점에 18, 중앙에 24, 75% 지점에 27이 위치한다는 것을 알 수 있다. 직사각형 밖에 있는 아래, 위 가로선을 보면 12~37을 벗어난 값이 극단치로 분류된다는 것을 알 수 있다. 가로선 밖에 표현된 점 표식은 극단치를 의미한다.
다음의 예제에서 제조국가별 연비 분포를 보여주는 박스 플롯을 그린다. 각 axe 객체에 박스 플롯을 그리는 boxplot() 메서드를 적용한다. ‘origin’ 값이 1인 ‘mpg’열, ‘origin’값이 2인 ‘mpg’열, ‘origin’ 값이 3인 ‘mpg’ 열의 데이터 분포를 출력한다. 박스 플롯에 넣을 열 3개를 리스트에 담아서 x 옵션에 할당한다. labels 옵션을 이용하여 각 열을 나타내는 라벨을 정의한다. 화면 오른쪽 ax2 객체에 vert=False 옵션을 사용하여 수평 박스 플롯을 그린다.
plt.style.use('seaborn-poster') # 스타일 서식 지정
plt.rcParams['axes.unicode_minus'] = False # 마이너스 부포 출력 설정
# read_csv() 함수로 df 생성
df = pd.read_csv('auto-mpg.csv', header=None)
# 열 이름 지정
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight',
'acceleration', 'model year', 'origin', 'name']
# 그래프 객체 생성(figure에 2개의 서브 플롯 생성)
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
# axe 객체에 boxplot 메서드로 그래프 출력
ax1.boxplot(x=[df[df['origin']==1]['mpg'],
df[df['origin']==2]['mpg'],
df[df['origin']==3]['mpg']],
labels=['USA', 'EU', 'JAPAN'])
ax2.boxplot(x=[df.query('origin==1')['mpg'],
df.query('origin==2')['mpg'],
df.query('origin==3')['mpg']],
labels=['USA', 'EU', 'JAPAN'],
vert=False)
ax1.set_title('제조국가별 연비 분포(수직 박스 플롯)')
ax2.set_title('제조국가별 연비 분포(수평 박스 플롯)')
plt.show()

박스 플롯은 범주형 데이터 분포와 주요 통계 지표를 함께 제공한다. 다만, 박스 플롯만으로는 데이터가 퍼져 있는 분산의 정도를 정확하게 알기는 어렵기 때문에 커널 밀도 함수 그래프를 y축 방향에 추가하여 바이올린 그래프를 그리는 경우도 있다. 박스 플롯은 boxplot() 함수로 그리고 바이올린 그래프는 violinplot() 함수로 그린다. 예제에서는 타이타닉 생존자의 분포를 파악한다. hue 변수에 ‘sex’ 열을 추가하면 남녀 데이터를 구분하여 표시할 수 있다.
# Seaborn 제공 데이터셋 가져오기
titanic = sns.load_dataset('titanic')
# 스타일 테마 설정(5가지: darkgrid, whitegrid, dark, white, ticks)
sns.set(style='whitegrid', palette='pastel')
# 그래프 객체 생성(figure에 4개의 서브 플롯 생성)
fig = plt.figure(figsize=(15, 10), constrained_layout=True)
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
ax4 = fig.add_subplot(2, 2, 4)
# 박스 플롯 - 기본값
sns.boxplot(x='alive', y='age', data=titanic, ax=ax1)
# 박스 플롯 - hue 변수 추가
sns.boxplot(x='alive', y='age', hue='sex', data=titanic, ax=ax2)
# 바이올린 그래프 - 기본값
sns.violinplot(x='alive', y='age', data=titanic, ax=ax3)
# 바이올린 그래프 - hue 변수 추가
sns.violinplot(x='alive', y='age', hue='sex', data=titanic, ax=ax4)
plt.show()

Geo Chart
Folium 라이브러리는 지도 위에 시각화할 때 유용한 도구이다. 세계 지도를 기본 지원하고 다양한 스타일의 지도 이미지를 제공하고 있다.
Folium 설치하기
Folium을 사용하기 위해서는 먼저 라이브러리를 설치해야 한다. 아나콘다 배포판을 사용하는 경우에도 설치가 필요하다. 설치 방법은 아나콘다 프롬프트를 실행하고, conda install -c conda-forge folium을 입력하고 enter를 치면 설치된다.
지도 만들기
Folium 라이브러리의 Map() 함수를 이용하면 간단하고 지도 객체를 만들 수 있다. 지도 화면은 고정된 것이 아니고 줌(zoom) 기능과 화면 이동(scroll)이 모두 가능하다.
단, 예제 코드를 스파이더(Spyder)와 같은 IDE에서 실행해도 지도가 표시되지 않는다. 그 이유는 Folium은 웹 기반 지도를 만들기 때문인데, 오직 웹 환경에서만 지도를 확인할 수 있다. 따라서 스파이더를 사용하는 경우라면 지도 객체를 바로 확인할 수 없다. 지도를 보려면 지도 객체에 save() 메서드를 적용하여 HTML 파일로 저장하고, 웹브라우저에서 파일을 열어서 확인해야 한다. 한편 Jupyter Notebook 등 웹 기반 IDE에서는 지도 객체를 바로 확인할 수 있다.
여기서는 스파이더를 기준으로 HTML 파일을 저장해서 웹브라우저로 확인하는 방법으로 설명한다. 지도 객체를 생성하는 Map() 함수의 location 옵션에 [위도, 경도] 수치를 입력하면 그 지점을 중심으로 지도를 보여준다. zoom_start 옵션을 사용하면 화면 확대 비율을 조절할 수 있다.
# 라이브러리 불러오기
import folium
# 서울 지도 만들기
seoul_map = folium.Map(location=[37.55, 126.98], zoom_start=12)
# 지도를 HTML 파일로 저장하기
seoul_map.save('./seoul.html')
# 지도 출력
display(seoul_map)
지도 스타일 적용하기
Map() 함수에 tiles 옵션을 적용하면 지도에 적용하는 스타일을 변경하여 지정할 수 있다. 다음의 예제에서는 ‘Stamen Terrain’ 맵과 ‘Stamen Toner’ 맵의 스타일을 비교한다.
# 서울 지도 불러오기
seoul_map2 = folium.Map(location=[37.55, 126.98], tiles='Stamen Terrain',
zoom_start=12)
seoul_map3 = folium.Map(location=[37.55, 126.98], tiles='Stamen Toner',
zoom_start=15)
# 지도를 HTML 파일로 저장하기
seoul_map2.save('./seoul2.html')
seoul_map2.save('./seoul3.html')
# 지도 출력
display(seoul_map2)
display(seoul_map3)
앞의 예제와 비교해 보면 ‘Stamen Terrain’ 맵은 산악 지형 등의 지형이 보다 선명하게 드러난다. ‘Stamen Toner’ 스타일을 적용한 맵은 흑백 스타일로 도로망을 강조해서 보여준다.
지도에 마커 표시하기
서울 시내 주요 대학교의 위치 데이터를 데이터프레임으로 변환하고, Folium 지도에 위치를 표시해 보자. 마커 위치를 표시하려면 Marker() 함수에 위도, 경도 정보를 전달한다. popup 옵션을 추가하면 마커를 클릭했을 때 팝업창에 표시해주는 텍스트를 넣을 수 있다.
# 대학교 리스트를 데이터프레임으로 변환
df = pd.read_csv('./서울지역 대학교 위치.csv', index_col=0)
# 서울 지도 만들기
seoul_map = folium.Map(location=[37.55, 126.98], tiles='Stamen Terrain',
zoom_start=12)
# 대학교 위치 정보를 Marker로 표시
for name, lat, lng in zip(df.index, df.위도, df.경도):
folium.Marker([lat, lng], popup=name).add_to(seoul_map)
# 지도를 HTML 파일로 저장하기
seoul_map.save('./seoul_colleges.html')
# 지도 출력
display(seoul_map)
서울 주요 대학의 위치에 마커가 표시된다. 각 마커를 클릭했을 때 대학교 이름으로 팝업 메시지가 나타나는 모습을 볼 수 있다.
이번에는 원형 마커를 표시해 보자. 앞의 예제에서 Marker() 함수 대신에 CircleMarker() 함수를 사용한다. 원형 마커의 크기, 색상, 투명도 등을 설정할 수 있다.
# 서울 지도 만들기
seoul_map = folium.Map(location=[37.55, 126.98], tiles='Stamen Terrain',
zoom_start=12)
# 대학교 위치 정보를 CircleMarker로 표시
for name, lat, lng in zip(df.index, df.위도, df.경도):
folium.CircleMarker([lat, lng],
radius=10, # 원의 반지름
color='brown', # 원의 둘레 색상
fill=True,
fill_color='coral', # 원을 채우는 색
fill_opacity=0.7, # 투명도
popup=name
).add_to(seoul_map)
# 지도를 HTML 파일로 저장하기
seoul_map.save('./seoul_colleges2.html')
# 지도 출력하기
display(seoul_map)
지도 영역에 단계구분도(Choropleth Map) 표시하기
행정구역과 같이 지도 상의 어떤 경계에 둘러싸인 영역에 색을 칠하거나 음영 등으로 정보를 나타내는 시각화 방법이다. 전달하려는 정보의 값이 커지면 영역에 칠해진 색이나 음영이 진해진다. 예제에서는 경기도 지역의 시군구별 인구 변화 데이터(2007 - 2017년), 경기도 행정구역 경계 지리 정보를 사용한다. Choropleth() 함수를 이용한다.
# 라이브러리 불러오기
import pandas as pd
import folium
import json
# 경기도 인구변화 데이터를 불러와서 데이터프레임으로 변환
file_path = './경기도인구데이터.xlsx'
df = pd.read_excel(file_path, index_col='구분')
df.columns = df.columns.map(str)
# 경기도 시군구 경계 정보를 가진 geo-json 파일 불러오기
geo_path = './경기도행정구역경계.json'
try:
geo_data = json.load(open(geo_path, encoding='utf-8'))
except:
geo_data = json.load(open(geo_path, encoding='utf-8-sig'))
# 경기도 지도 만들기
g_map = folium.Map(location=[37.5502, 126.982],
tiles='Stamen Terrain', zoom_start=9)
# 출력할 연도 선택(2007~2017년 중에서 선택)
year = '2007'
# Choropleth 클래스로 단계구분도 표시하기
folium.Choropleth(geo_data=geo_data,
data=df[year],
columns=[df.index, df[year]],
fill_color='YlOrRd', fill_opacity=0.7, line_opacity=0.3,
threshold_scale=[10000, 100000, 300000, 500000, 700000],
key_on='feature.properties.name',
).add_to(g_map)
# 지도를 HTML 파일로 저장하기
g_map.save('./gyonggi_population_' + year + '.html')
# 지도 출력하기
display(g_map)
2007년도 경기도 지역의 인구 수를 표시한 지도를 보면 동북부 지역을 제외하고 비교적 균일한 분포를 나타낸다.
# 라이브러리 불러오기
import pandas as pd
import folium
import json
# 경기도 인구변화 데이터를 불러와서 데이터프레임으로 변환
file_path = './경기도인구데이터.xlsx'
df = pd.read_excel(file_path, index_col='구분')
df.columns = df.columns.map(str)
# 경기도 시군구 경계 정보를 가진 geo-json 파일 불러오기
geo_path = './경기도행정구역경계.json'
try:
geo_data = json.load(open(geo_path, encoding='utf-8'))
except:
geo_data = json.load(open(geo_path, encoding='utf-8-sig'))
# 경기도 지도 만들기
g_map = folium.Map(location=[37.5502, 126.982],
tiles='Stamen Terrain', zoom_start=9)
# 출력할 연도 선택(2007~2017년 중에서 선택)
year = '2017'
# Choropleth 클래스로 단계구분도 표시하기
folium.Choropleth(geo_data=geo_data,
data=df[year],
columns=[df.index, df[year]],
fill_color='YlOrRd', fill_opacity=0.7, line_opacity=0.3,
threshold_scale=[10000, 100000, 300000, 500000, 700000],
key_on='feature.properties.name',
).add_to(g_map)
# 지도를 HTML 파일로 저장하기
g_map.save('./gyonggi_population_' + year + '.html')
# 지도 출력하기
display(g_map)
2017년도 경기도 지역의 인구 수를 지도에 표시하였다. 2007년과 비교하면 남양주, 분당, 화성(동탄) 지역의 신도시 개발과 인구 유입으로 인구가 집중되는 현상이 심화된 것을 볼 수 있다.
Folium 라이브러리에 대한 더 자세한 내용은 다음 문서와 공식 홈페이지를 참고하자.
http://suanlab.com/assets/youtubes/dv/Folium.pdf
http://python-visualization.github.io/folium/
시각화 팁
Joint plot
jointplot() 함수는 산점도를 기본으로 표시하고, x-y축에 각 변수에 대한 히스토그램을 동시에 보여준다. 따라서 두 변수의 관계와 데이터가 분산되어 있는 정도를 한눈에 파악하기 좋다. 예제에서는 산점도(기본값), 회귀선 추가(kind=’reg’), 육각 산점도(kind=’hex’), 커널 밀집 그래프(kind=’kde’) 순으로 조인트 그래프를 그리고 차이를 비교한다.
# seaborn 제공 데이터셋 가져오기
titanic = sns.load_dataset('titanic')
# 스타일 테마 설정(5가지: darkgrid, whitegrid, dark, white, ticks)
sns.set_style('whitegrid')
# 조인트 그래프 - 산점도(기본값)
j1 = sns.jointplot(x='fare', y='age', data=titanic)
# 조인트 그래프 - 회귀선
j2 = sns.jointplot(x='fare', y='age', kind='reg', data=titanic)
# 조인트 그래프 - 육각 그래프
j3 = sns.jointplot(x='fare', y='age', kind='hex', data=titanic)
# 조인트 그래프 - 커널 밀집 그래프
j4 = sns.jointplot(x='fare', y='age', kind='kde', data=titanic)
# 차트 제목 표시
j1.fig.suptitle('titanic fare - scatter', size=15)
j2.fig.suptitle('titanic fare - reg', size=15)
j3.fig.suptitle('titanic fare - hex', size=15)
j4.fig.suptitle('titanic fare - kde', size=15)
plt.show()




패싯 그리드와 범주형 데이터
추가적인 그룹 차원을 가지는 데이터는 어떻게 시각화해야 할까? 다양한 범주형 값을 가지는 데이터를 시각화하는 한 가지 방법은 패싯 그리드를 이용하는 것이다. seaborn은 catplot() 이라는 유용한 내장 함수를 제공하여 다양한 면을 나타내는 그래프를 쉽게 그릴 수 있게 도와준다.
sns.catplot(x='day', y='tip_pct', hue='time', col='smoker',
kind='bar', data=tips[tips.tip_pct < 1]);

‘time’으로 그룹을 만드는 대신 패싯 안에서 막대그래프의 색상을 달리해서 보여줄 수 있다. 또한 패싯 그리드에 time 값에 따른 그래프를 추가할 수도 있다.
sns.catplot(x='day', y='tip_pct', row='time',
col='smoker',
kind='bar', data=tips[tips.tip_pct < 1]);

catplot()은 보여주고자 하는 목적에 어울리는 다른 종류의 그래프도 함께 지원한다. 예를 들어 중간값과 사분위 그리고 특잇값을 보여주는 상자그림box plot이 효과적인 시각화 방법일 수도 있다.
sns.catplot(x='tip_pct', y='day', kind='box',
data=tips[tips.tip_pct < 0.5]);

일반적인 용도의 seaborn.FacetGrid 클래스를 이용해서 나만의 패싯 그리드를 만들고 원하는 그래프를 그릴 수도 있다. 자세한 내용은 seaborn 문서를 참고하자.
조건을 적용하여 화면을 그리드로 분할하기
FacetGrid() 함수는 행, 열 방향으로 서로 다른 조건을 적용하여 여러 개의 서브 플롯을 만든다. 그리고 각 서브 플롯에 적용할 그래프 종류를 map() 메서드를 이용하여 그리드 객체에 전달한다.
다음의 예제는 열 방향으로는 ‘who’ 열의 탑승객 구분(man, woman, child) 값으로 구분하고, 행 방향으로는 ‘survived’ 열의 구조 여부(구조 survived=1, 구조실패 survived=0) 값으로 구분하여 2행x3열 모양의 그리드를 만든다. 각 조건에 맞는 탑승객을 구분하여, ‘age’열의 나이를 기준으로 히스토그램을 그려본다. 남성에 비해 여성 생존자가 상대적으로 많은 편이고, 성인 중에서는 활동성이 좋은 20~40대의 생존자가 많은 것으로 나타난다.
# seaborn 제공 데이터셋 가져오기
titanic = sns.load_dataset('titanic')
# 스타일 테마 설정(5가지: darkgrid, whitegrid, dark, white, ticks)
sns.set_style('whitegrid')
# 조건에 따라 그리드 나누기
g = sns.FacetGrid(data=titanic, col='who', row='survived')
# 그래프 적용하기
g = g.map(plt.hist, 'age')

다른 파이썬 시각화 도구
여타 오픈소스와 마찬가지로 파이썬에서 그래프를 그릴 수 있는 라이브러리는 일일이 나열하기 힘들 정도로 많이 존재한다. 2010년부터 웹을 위한 대화형 그래픽 도구 개발이 본격적으로 진행되었는데, Bokeh(보케)나 Plotly(플로틀리) 같은 도구를 이용하면 웹 브라우저 상에서 파이썬으로 동적 대화형 그래프를 그릴 수 있다.
웹이나 출판을 위한 정적 그래프를 생성한다면 matplotlib과 pandas, seaborn을 기본으로 사용하길 추천한다. 기타 다른 데이터 시각화 요구 사항을 위해서라면 계속 생태계가 발전하고 있으므로 다양한 시각화 도구를 직접 살펴보기 추천한다.
-
커널 밀도 함수는 그래프와 x축 사이의 면적이 1이 되도록 그리는 밀도 분포 함수이다.
↩
댓글남기기