데이터 집계와 그룹 연산
데이터 집계와 그룹 연산
데이터셋을 분류하고 각 그룹에 집계나 변형 같은 함수를 적용하는 건 데이터 분석 과정에서 무척 중요한 일이다. 데이터를 불러오고 취합해서 하나의 데이터 집합을 준비하고 나면 그룹 통계를 구하거나 가능하다면 피벗테이블1을 구해서 보고서를 만들거나 시각화하게 된다. 판다스는 데이터 집합을 자연스럽게 나누고 요약할 수 있는 groupby라는 유연한 방법을 제공한다.
관계형 데이터베이스와 SQLStructured Query Language이 인기 있는 이유 중 하나는 데이터를 쉽게 합치고 걸러내고 변형하고 집계할 수 있기 때문이다. 하지만 SQL 같은 쿼리문은 그룹 연산에 제약이 있다. 앞으로 살펴보겠지만 파이썬과 판다스의 강력한 표현력을 잘 이용하면 아주 복잡한 그룹 연산도 판다스 객체나 NumPy 배열을 받는 함수의 조합으로 해결할 수 있다. 여기서는 다음 내용을 배우게 된다.
-
하나 이상의 키(함수, 배열, 데이터프레임의 칼럼 이름)를 이용해서 판다스 객체를 여러 조각으로 나누는 방법
-
합계, 평균, 표준편차, 사용자 정의 함수 같은 그룹 요약 통계를 계산하는 방법
-
정규화, 선형회귀, 등급 또는 부분집합 선택 같은 집단 내 변형이나 다른 조작을 적용하는 방법
-
피벗테이블과 교차일람표를 구하는 방법
-
변위치 분석과 다른 통계 집단 분석을 수행하는 방법
GroupBy 메카닉
다수의 인기 있는 R 프로그래밍 패키지의 저자인 해들리 위캠Hadley Wickham은 분리-적용-결합split-apply-combine이라는 그룹 연산에 대한 새로운 용어를 만들었는데, 이 말이 그룹 연산에 대한 훌륭한 설명이라고 생각한다. 그룹 연산의 첫 번째 단계에서는 시리즈, 데이터프레임 같은 판다스 객체나 아니면 다른 객체에 들어 있는 데이터를 하나 이상의 키를 기준으로 분리한다. 객체는 하나의 축을 기준으로 분리하는데, 예를 들어 데이터프레임은 로우(axis=0)로 분리하거나 칼럼(axis=1)으로 분리할 수 있다. 분리하고 나서는 함수를 각 그룹에 적용시켜 새로운 값을 얻어낸다. 마지막으로 함수를 적용한 결과를 하나의 객체로 결합한다. 결과를 담는 객체는 보통 데이터에 어떤 연산을 했는지에 따라 결정된다. 간단한 그룹 연산의 예시를 살펴보자.
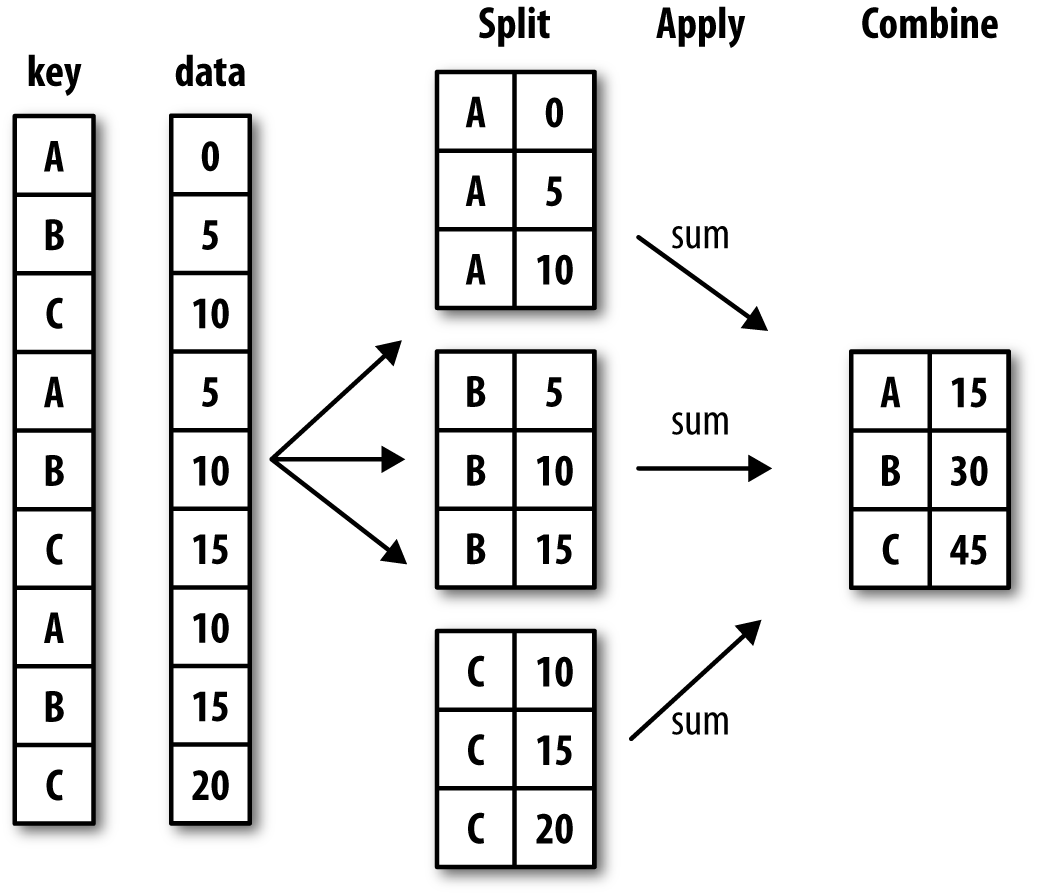
각 3단계의 과정을 정리하면
1단계) 분할(split): 데이터를 특정 조건에 의해 분할
2단계) 적용(apply): 데이터를 집계, 변환, 필터링하는데 필요한 메서드 적용
3단계) 결합(combine): 2단계의 처리 결과를 하나로 결합
각 그룹의 색인은 다음과 같이 다양한 형태가 될 수 있으며, 모두 같은 타입일 필요도 없다.
-
그룹으로 묶을 축과 동일한 길이의 리스트나 배열
-
데이터프레임의 칼럼 이름을 지칭하는 값
-
그룹으로 묶을 값과 그룹 이름에 대응하는 사전이나 시리즈 객체
-
축 색인 혹은 색인 내의 개별 이름에 대해 실행되는 함수
앞 목록에서 마지막 세 방법은 객체를 나눌 때 사용할 배열을 생성하기 위한 방법이라는 것을 기억하자. 아직까지 확실한 개념이 잡히지 않는다고 너무 걱정하지 말자. 앞으로 차차 이 방법들을 사용하는 다양한 예제를 살펴보게 될 것이다. 먼저 다음과 같이 데이터프레임으로 표현되는 간단한 표 형식의 데이터가 있다고 하자.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a'],
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
df
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | a | one | 1.897363 | -0.267253 |
| 1 | a | two | 0.414906 | 0.784932 |
| 2 | b | one | 0.178935 | -1.864723 |
| 3 | b | two | -0.958280 | 0.692412 |
| 4 | a | one | 1.233095 | 0.793427 |
데이터프레임의 groupby()는 RDBMS SQL의 groupby 키워드와 유사하면서도 다른 면이 있기 때문에 주의가 필요하다. SQL, 판다스 모두 groupby()를 분석 작업에 매우 많이 활용한다. 데이터프레임의 `groupby()` 사용 시 입력 파라미터 by에 칼럼을 입력하면 대상 칼럼으로 groupby된다. 데이터프레임에 groupby()를 호출하면 DataFrameGroupBy라는 또 다른 형태의 데이터프레임을 반환한다. data1에 대해 groupby() 메서드를 호출하고 key1 칼럼을 넘겨서 이 데이터를 key1으로 묶고 각 그룹에서 data1의 평균을 구해보자.
grouped = df['data1'].groupby(df['key1'])
grouped
<pandas.core.groupby.generic.SeriesGroupBy object at 0x000002D5DAB5BA00>
이 grouped 변수는 GroupBy 객체다. df[‘key1’]로 참조되는 중간값에 대한 것 외에는 아무것도 계산되지 않은 객체다. SQL의 groupby와 다르게, 데이터프레임에 groupby()를 호출해 반환된 결과에 aggregation 함수를 호출하면 groupby() 대상 칼럼을 제외한 모든 칼럼에 해당 aggregation 함수를 적용한다. 이 객체는 그룹 연산을 위해 필요한 모든 정보를 가지고 있어서 각 그룹에 어떤 연산을 적용할 수 있게 해준다. 예를 들어 그룹별 평균을 구하려면 GroupBy 객체의 mean() 메서드를 사용하면 된다.
grouped.mean()
key1 a 1.181788 b -0.389673 Name: data1, dtype: float64
.mean() 메서드를 호출했을 때의 자세한 내용은 나중에 설명하기로 하고, 이 예제에서 중요한 점은 데이터(시리즈 객체)가 그룹 색인에 따라 수집되고 key1 칼럼에 있는 유일한 값으로 색인되는 새로운 시리즈 객체가 생성된다는 것이다. 새롭게 생성된 시리즈 객체의 색인은 ‘key1’인데, 그 이유는 전달된 인자가 데이터프레임 칼럼인 df[‘key1’] 이기 때문이다.
만약 여러 개의 배열을 리스트로 넘겼다면 조금 다른 결과를 얻었을 것이다. 여러 개의 기준 값을 사용하기 때문에 반환되는 그룹 객체의 인덱스는 다중 구조를 갖는다.
means = df['data1'].groupby([df['key1'], df['key2']]).mean()
means
key1 key2
a one 1.565229
two 0.414906
b one 0.178935
two -0.958280
Name: data1, dtype: float64
여기서는 데이터를 두 개의 색인으로 묶었고, 그 결과 계층적 색인을 가지는 시리즈를 얻을 수 있었다.
means.unstack() # default: level=-1
| key2 | one | two |
|---|---|---|
| key1 | ||
| a | 1.565229 | 0.414906 |
| b | 0.178935 | -0.958280 |
이 예제에서는 그룹의 색인 모두 시리즈 객체인데, 길이만 같다면 어떤 배열이라도 상관없다.
states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])
years = np.array([2005, 2005, 2006, 2005, 2006])
df['data1'].groupby([states, years]).mean()
California 2005 0.414906
2006 0.178935
Ohio 2005 0.469541
2006 1.233095
Name: data1, dtype: float64
한 그룹으로 묶을 정보는 주로 같은 데이터프레임 안에서 찾게 되는데, 이 경우 칼럼 이름(문자열, 숫자 혹은 다른 파이썬 객체)을 넘겨서 그룹의 색인으로 사용할 수 있다.
df.groupby('key1').mean()
| data1 | data2 | |
|---|---|---|
| key1 | ||
| a | 1.181788 | 0.437035 |
| b | -0.389673 | -0.586156 |
df.groupby(['key1', 'key2']).mean()
| data1 | data2 | ||
|---|---|---|---|
| key1 | key2 | ||
| a | one | 1.565229 | 0.263087 |
| two | 0.414906 | 0.784932 | |
| b | one | 0.178935 | -1.864723 |
| two | -0.958280 | 0.692412 |
위에서 df.groupby('key1').mean() 코드를 보면 key2 칼럼이 결과에서 빠져 있는 것을 확인할 수 있다. 그 이유는 df[‘key2’]는 숫자 데이터가 아니기 때문인데, 이런 칼럼은 성가신 칼럼nuisance column이라고 부르며 결과에서 제외시킨다. 기본적으로 모든 숫자 칼럼이 수집되지만 곧 살펴보듯이 원하는 부분만 따로 걸러내는 것도 가능하다.
groupby()를 쓰는 목적과 별개로, 일반적으로 유용한 GroupBy 메서드는 그룹의 크기를 담고 있는 시리즈를 반환하는 size() 메서드다.
df.groupby(['key1', 'key2']).size()
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
그룹 색인에서 누락된 값은 결과에서 제외된다는 것을 기억하자.
그룹 간 순회하기
GroupBy 객체는 iteration을 지원하는데 그룹 이름과 그에 따른 데이터 묶음을 튜플로 반환한다. 다음 예제를 살펴보자.
for key, group in df.groupby('key1'):
print('* key :', key)
print('* number :', len(group))
print(group)
print('\n')
* key : a * number : 3 key1 key2 data1 data2 0 a one 1.897363 -0.267253 1 a two 0.414906 0.784932 4 a one 1.233095 0.793427 * key : b * number : 2 key1 key2 data1 data2 2 b one 0.178935 -1.864723 3 b two -0.958280 0.692412
이처럼 색인이 여럿 존재하는 경우 튜플의 첫 번째 원소가 색인값이 된다.
for (key1, key2), group in df.groupby(['key1', 'key2']):
print('* key :', (key1, key2))
print('* number :', len(group))
print(group)
print('\n')
* key : ('a', 'one')
* number : 2
key1 key2 data1 data2
0 a one 1.897363 -0.267253
4 a one 1.233095 0.793427
* key : ('a', 'two')
* number : 1
key1 key2 data1 data2
1 a two 0.414906 0.784932
* key : ('b', 'one')
* number : 1
key1 key2 data1 data2
2 b one 0.178935 -1.864723
* key : ('b', 'two')
* number : 1
key1 key2 data1 data2
3 b two -0.95828 0.692412
당연히 이 안에서 원하는 데이터만 골라낼 수 있다. 한 줄이면 그룹별 데이터를 사전형으로 쉽게 바꿔서 유용하게 사용할 수 있다.
pieces = dict(list(df.groupby('key1')))
display(pieces)
display(pieces['b'])
{'a': key1 key2 data1 data2
0 a one 1.897363 -0.267253
1 a two 0.414906 0.784932
4 a one 1.233095 0.793427,
'b': key1 key2 data1 data2
2 b one 0.178935 -1.864723
3 b two -0.958280 0.692412}
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 2 | b | one | 0.178935 | -1.864723 |
| 3 | b | two | -0.958280 | 0.692412 |
groupby() 메서드는 기본적으로 axis=0에 대해 그룹을 만드는데, 다른 축으로 그룹을 만드는 것도 가능하다. 예를 들어 예제로 살펴본 df의 칼럼을 dtype에 따라 그룹으로 묶을 수도 있다.
df.dtypes
key1 object key2 object data1 float64 data2 float64 dtype: object
grouped = df.groupby(df.dtypes, axis=1)
for dtype, group in grouped:
print('* dtype: ', dtype)
print(group)
print('\n')
* dtype: float64
data1 data2
0 1.897363 -0.267253
1 0.414906 0.784932
2 0.178935 -1.864723
3 -0.958280 0.692412
4 1.233095 0.793427
* dtype: object
key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one
칼럼이나 칼럼의 일부만 선택하기
데이터프레임에서 만든 GroupBy 객체를 칼럼 이름이나 칼럼 이름이 담긴 배열로 색인하면 수집을 위해 해당 칼럼을 선택하게 된다.
df.groupby('key1')['data1']
df.groupby('key1')[['data2']]
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002D5DABE10A0>
위 코드는 아래 코드에 대한 syntactic sugar2로 같은 결과를 반환한다.
df['data1'].groupby(df['key1'])
df[['data2']].groupby(df['key1'])
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002D5DABE1550>
특히 대용량 데이터를 다룰 경우 소수의 칼럼만 집계하고 싶을 때가 종종 있는데, 예를 들어 위 데이터에서 data2 칼럼에 대해서만 평균을 구하고 결과를 데이터프레임으로 받고 싶다면 아래와 같이 작성한다.
# syntactic sugar: df[['data2']].groupby([df['key1'], df['key2']]).mean()
df.groupby(['key1', 'key2'])[['data2']].mean()
| data2 | ||
|---|---|---|
| key1 | key2 | |
| a | one | 0.263087 |
| two | 0.784932 | |
| b | one | -1.864723 |
| two | 0.692412 |
색인으로 얻은 객체는 groupby() 메서드에 리스트나 배열을 넘겼을 경우 DataFrameGroupBy 객체가 되고, 단일 값으로 하나의 칼럼 이름만 넘겼을 경우 SeriesGroupBy 객체가 된다.
s_grouped = df.groupby(['key1', 'key2'])['data2']
display(s_grouped)
display(s_grouped.mean())
<pandas.core.groupby.generic.SeriesGroupBy object at 0x000002D5DABFAAC0>
key1 key2
a one 0.263087
two 0.784932
b one -1.864723
two 0.692412
Name: data2, dtype: float64
사전과 Series에서 그룹핑하기
그룹 정보는 배열이 아닌 형태로 존재하기도 한다. 다른 데이터프레임 예제를 살펴보자.
people = pd.DataFrame(np.random.randn(5, 5),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])
people.iloc[2:3, [1, 2]] = np.nan # nan 값을 추가하자.
people
| a | b | c | d | e | |
|---|---|---|---|---|---|
| Joe | 0.211223 | -1.669961 | -0.881966 | -1.957147 | 0.599661 |
| Steve | -0.640144 | -0.416552 | -0.102563 | 0.374840 | 0.661327 |
| Wes | 0.150227 | NaN | NaN | 0.171901 | -0.900277 |
| Jim | 1.053917 | 0.805950 | -0.795517 | 0.101326 | 1.632543 |
| Travis | -0.818808 | -2.066885 | 1.222610 | 1.210709 | 0.848762 |
이제 각 칼럼을 나타낼 그룹 목록이 있고, 그룹별로 칼럼의 값을 모두 더한다고 해보자.
mapping = {'a': 'red', 'b': 'red', 'c': 'blue',
'd': 'blue', 'e': 'red', 'f': 'orange'}
mapping
{'a': 'red', 'b': 'red', 'c': 'blue', 'd': 'blue', 'e': 'red', 'f': 'orange'}
이 사전에서 groupby() 메서드로 넘길 배열을 뽑아낼 수 있지만 그냥 이 사전을 groupby() 메서드로 넘기자(사용하지 않는 그룹 키가 포함되어 있어도 문제없다는 것을 보이기 위해 ‘f’도 포함시켰다).
by_column = people.groupby(mapping, axis=1)
by_column.sum()
| blue | red | |
|---|---|---|
| Joe | -2.839113 | -0.859076 |
| Steve | 0.272277 | -0.395369 |
| Wes | 0.171901 | -0.750049 |
| Jim | -0.694192 | 3.492410 |
| Travis | 2.433319 | -2.036931 |
시리즈에 대해서도 같은 기능을 수행할 수 있는데, 고정된 크기의 맵이라고 보면 된다. 여기서 말하는 고정된 크기란 시리즈 칸을 생각하면 될 것 같다.
map_series = pd.Series(mapping)
map_series
a red b red c blue d blue e red f orange dtype: object
people.groupby(map_series, axis=1).count()
| blue | red | |
|---|---|---|
| Joe | 2 | 3 |
| Steve | 2 | 3 |
| Wes | 1 | 2 |
| Jim | 2 | 3 |
| Travis | 2 | 3 |
Wes 행의 데이터가 다른 이유는 nan 값 때문이다. aggregation 함수는 nan 값을 자동으로 제외하고 연산을 한다.
함수로 그룹핑하기
파이썬 함수를 사용하는 것은 사전이나 시리즈를 사용해서 그룹을 매핑하는 것보다 좀 더 일반적인 방법이다. 그룹 색인을 넘긴 함수는 색인값 하나마다 한 번씩 호출되며, 반환값이 그 그룹의 이름으로 사용된다. 좀 더 구체적으로 말하면 좀 전에 살펴본 예제에서 people 데이터프레임은 사람의 이름을 색인값으로 사용했다. 만약 이름의 길이별로 그룹을 묶고 싶다면 이름의 길이가 담긴 배열을 만들어 넘기는 대신 len() 함수를 넘기면 된다.
people.groupby(len).sum()
| a | b | c | d | e | |
|---|---|---|---|---|---|
| 3 | 1.415368 | -0.864011 | -1.677483 | -1.683921 | 1.331927 |
| 5 | -0.640144 | -0.416552 | -0.102563 | 0.374840 | 0.661327 |
| 6 | -0.818808 | -2.066885 | 1.222610 | 1.210709 | 0.848762 |
내부적으로는 모두 배열로 변환되므로 함수를 배열, 사전 또는 시리즈와 섞어 쓰더라도 전혀 문제가 되지 않는다.
key_list = ['one', 'one', 'one', 'two', 'two']
people.groupby([len, key_list]).min()
| a | b | c | d | e | ||
|---|---|---|---|---|---|---|
| 3 | one | 0.150227 | -1.669961 | -0.881966 | -1.957147 | -0.900277 |
| two | 1.053917 | 0.805950 | -0.795517 | 0.101326 | 1.632543 | |
| 5 | one | -0.640144 | -0.416552 | -0.102563 | 0.374840 | 0.661327 |
| 6 | two | -0.818808 | -2.066885 | 1.222610 | 1.210709 | 0.848762 |
색인 단계로 그룹핑하기
계층적으로 색인된 데이터는 축 색인의 단계 중 하나를 사용해서 편리하게 집계할 수 있는 기능을 제공한다. 다음 예제를 보자.
columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'],
[1, 3, 5, 1, 3]],
names=['cty', 'tenor'])
columns
MultiIndex([('US', 1),
('US', 3),
('US', 5),
('JP', 1),
('JP', 3)],
names=['cty', 'tenor'])
hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)
hier_df
| cty | US | JP | |||
|---|---|---|---|---|---|
| tenor | 1 | 3 | 5 | 1 | 3 |
| 0 | -1.538885 | -0.088384 | 0.093003 | -1.025512 | -0.181741 |
| 1 | -0.649020 | 1.003128 | 0.330653 | -1.825196 | -1.139156 |
| 2 | -0.463565 | -1.247414 | 1.180932 | -1.117207 | 1.312400 |
| 3 | -0.187331 | 1.577278 | 0.380216 | 1.717873 | -1.178039 |
이 기능을 사용하려면 level 예약어를 사용해서 레벨 번호나 이름을 넘기면 된다.
hier_df.groupby(level='cty', axis=1).count()
| cty | JP | US |
|---|---|---|
| 0 | 2 | 3 |
| 1 | 2 | 3 |
| 2 | 2 | 3 |
| 3 | 2 | 3 |
데이터 집계
데이터 집계(aggreagation)는 배열로부터 스칼라값을 만들어내는 모든 데이터 변환 작업을 말한다. 위 예제에서는 mean(), count(), min(), sum()을 이용해서 스칼라값을 구했다. GroupBy 객체에 대해 mean()을 수행하면 어떤 일이 생기는지 궁금할 것이다. 밑의 표에 있는 것과 같이 일반적인 데이터 집계는 데이터 묶음에 대한 준비된 통계를 계산해내는 최적화된 구현을 가지고 있다. 하지만 이 메서드만 사용해야 하는 건 아니다.
| 함수 | 설명 |
|---|---|
| count | 그룹에서 NA가 아닌 값의 수를 반환한다. |
| sum | NA가 아닌 값들의 합을 구한다. |
| mean | NA가 아닌 값들의 평균을 구한다. |
| median | NA가 아닌 값들의 산술 중간값을 구한다. |
| std, var | 편향되지 않은(n - 1을 분모로 하는) 표준편차와 분산 |
| min, max | NA가 아닌 값들 중 최솟값과 최댓값 |
| prod | NA가 아닌 값들의 곱 |
| first, last | NA가 아닌 값들 중 첫째 값과 마지막 값 |
직접 고안한 집계함수를 사용하고 추가적으로 그룹 객체에 이미 정의된 메서드를 연결해서 사용하는 것도 가능하다. 예를 들어 quantile() 메서드가 시리즈나 데이터프레임의 칼럼의 변위치를 계산한다는 점을 생각해보자.
quantile() 메서드는 GroupBy만을 위해 구현된 건 아니지만 시리즈 메서드이기 때문에 여기서 사용할 수 있다. 내부적으로 GroupBy는 시리즈를 효과적으로 잘게 자르고, 각 조각에 대해 piece.quantile(0.9)를 호출한다. 그리고 이 결과들을 모두 하나의 객체로 합쳐서 반환한다. 이는 위에서 보았던 분할-적용-결합의 원리이다.
df
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | a | one | 1.897363 | -0.267253 |
| 1 | a | two | 0.414906 | 0.784932 |
| 2 | b | one | 0.178935 | -1.864723 |
| 3 | b | two | -0.958280 | 0.692412 |
| 4 | a | one | 1.233095 | 0.793427 |
grouped = df.groupby('key1')
grouped['data1'].quantile(0.9)
key1 a 1.764509 b 0.065213 Name: data1, dtype: float64
자신만의 데이터 집계함수를 사용하려면 배열의 aggregate()나 agg() 메서드에 해당 함수를 넘기면 된다.
def peak_to_peak(arr):
return arr.max() - arr.min()
grouped.agg(peak_to_peak)
| data1 | data2 | |
|---|---|---|
| key1 | ||
| a | 1.482456 | 1.060680 |
| b | 1.137215 | 2.557135 |
describe() 같은 메서드는 데이터를 집계하지 않는데도 잘 작동함을 확인할 수 있다.
grouped.describe()
| data1 | data2 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | count | mean | std | min | 25% | 50% | 75% | max | |
| key1 | ||||||||||||||||
| a | 3.0 | 1.181788 | 0.742559 | 0.414906 | 0.824001 | 1.233095 | 1.565229 | 1.897363 | 3.0 | 0.437035 | 0.609946 | -0.267253 | 0.25884 | 0.784932 | 0.789180 | 0.793427 |
| b | 2.0 | -0.389673 | 0.804132 | -0.958280 | -0.673976 | -0.389673 | -0.105369 | 0.178935 | 2.0 | -0.586156 | 1.808168 | -1.864723 | -1.22544 | -0.586156 | 0.053128 | 0.692412 |
NOTE_사용자 정의 집계함수는 일반적으로 위의 표에 있는 함수에 비해 무척 느리게 동작하는데, 그 이유는 중간 데이터를 생성하는 과정에서 함수 호출이나 데이터 정렬 같은 오버헤드가 발생하기 때문이다.
칼럼에 여러 가지 함수 적용하기
앞서 살펴본 팁 데이터로 다시 돌아가자. 여기서는 read_csv() 함수로 데이터를 불러온 다음, 팁의 비율을 담기 위한 칼럼인 tip_pct를 추가했다.
tips = pd.read_csv('examples/tips.csv')
# total_bill 에서 팁의 비율을 추가하지.
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.head()
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
이미 살펴봤듯이 시리즈나 데이터프레임의 모든 칼럼을 집계하는 것은 mean()이나 std() 같은 메서드를 호출하거나 원하는 함수에 aggregate()를 사용하는 것이다. 하지만 칼럼에 따라 다른 함수를 사용해서 집계를 수행하거나 여러 개의 함수를 한 번에 적용하길 원한다면 이를 쉽고 간단하게 수행할 수 있다. 앞으로 몇몇 예제를 통해 이를 자세히 알아볼 텐데, 먼저 tips를 day와 smoker별로 묶어보자.
grouped = tips.groupby(['day', 'smoker'])
위 표의 내용과 같은 기술 통계에서는 함수 이름을 문자열로 넘기면 된다.
grouped_pct = grouped['tip_pct']
grouped_pct.agg('mean')
day smoker
Fri No 0.151650
Yes 0.174783
Sat No 0.158048
Yes 0.147906
Sun No 0.160113
Yes 0.187250
Thur No 0.160298
Yes 0.163863
Name: tip_pct, dtype: float64
만일 함수 목록이나 함수 이름을 넘기면 함수 이름을 칼럼 이름으로 하는 데이터프레임을 얻게 된다.
grouped_pct.agg(['mean', 'std', peak_to_peak])
| mean | std | peak_to_peak | ||
|---|---|---|---|---|
| day | smoker | |||
| Fri | No | 0.151650 | 0.028123 | 0.067349 |
| Yes | 0.174783 | 0.051293 | 0.159925 | |
| Sat | No | 0.158048 | 0.039767 | 0.235193 |
| Yes | 0.147906 | 0.061375 | 0.290095 | |
| Sun | No | 0.160113 | 0.042347 | 0.193226 |
| Yes | 0.187250 | 0.154134 | 0.644685 | |
| Thur | No | 0.160298 | 0.038774 | 0.193350 |
| Yes | 0.163863 | 0.039389 | 0.151240 |
여기서는 데이터 그룹에 대해 독립적으로 적용하기 위해 agg()에 집계함수들의 리스트를 넘겼다.
GroupBy 객체에서 자동으로 지정하는 칼럼 이름을 그대로 쓰지 않아도 된다. lambda 함수는 이름(함수 이름은 __name__ 속성으로 확인 가능하다)이 ‘<lambda>‘인데, 이를 그대로 쓸 경우 알아보기 힘들어진다. 이때 이름과 함수가 담긴 (name, function) 튜플의 리스트를 넘기면 각 튜플에서 첫 번째 원소가 데이터프레임에서 칼럼 이름으로 사용된다(2개의 튜플을 가지는 리스트가 순서대로 매핑된다).
grouped_pct.agg([('foo', 'mean'), ('bar', np.std)])
| foo | bar | ||
|---|---|---|---|
| day | smoker | ||
| Fri | No | 0.151650 | 0.028123 |
| Yes | 0.174783 | 0.051293 | |
| Sat | No | 0.158048 | 0.039767 |
| Yes | 0.147906 | 0.061375 | |
| Sun | No | 0.160113 | 0.042347 |
| Yes | 0.187250 | 0.154134 | |
| Thur | No | 0.160298 | 0.038774 |
| Yes | 0.163863 | 0.039389 |
또는 grouped.agg()에 mean_pct = ‘mean’처럼 요약값을 할당할 변수명과 ‘=’를 입력한 다음, 값을 요약하는데 사용할 변수와 함수를 괄호 안에 나열하면 된다.
grouped.agg(mean_pct=('tip_pct', 'mean'))
| mean_pct | ||
|---|---|---|
| day | smoker | |
| Fri | No | 0.151650 |
| Yes | 0.174783 | |
| Sat | No | 0.158048 |
| Yes | 0.147906 | |
| Sun | No | 0.160113 |
| Yes | 0.187250 | |
| Thur | No | 0.160298 |
| Yes | 0.163863 |
데이터프레임은 칼럼마다 다른 함수를 적용하거나 여러 개의 함수를 모든 칼럼에 적용할 수 있다. tip_pct와 total_bill 칼럼에 대해 동일한 세 가지 통계를 계산한다고 가정하자.
functions = ['count', 'mean', 'max']
result = grouped['tip_pct', 'total_bill'].agg(functions)
result
| tip_pct | total_bill | ||||||
|---|---|---|---|---|---|---|---|
| count | mean | max | count | mean | max | ||
| day | smoker | ||||||
| Fri | No | 4 | 0.151650 | 0.187735 | 4 | 18.420000 | 22.75 |
| Yes | 15 | 0.174783 | 0.263480 | 15 | 16.813333 | 40.17 | |
| Sat | No | 45 | 0.158048 | 0.291990 | 45 | 19.661778 | 48.33 |
| Yes | 42 | 0.147906 | 0.325733 | 42 | 21.276667 | 50.81 | |
| Sun | No | 57 | 0.160113 | 0.252672 | 57 | 20.506667 | 48.17 |
| Yes | 19 | 0.187250 | 0.710345 | 19 | 24.120000 | 45.35 | |
| Thur | No | 45 | 0.160298 | 0.266312 | 45 | 17.113111 | 41.19 |
| Yes | 17 | 0.163863 | 0.241255 | 17 | 19.190588 | 43.11 | |
위에서 확인할 수 있듯이 반환된 데이터프레임은 계층적인 칼럼을 가지고 있으며 이는 각 칼럼을 따로 계산한 다음 concat() 메서드를 이용해서 keys 인자로 칼럼 이름을 넘겨서 이어붙인 것과 동일하다.
result['tip_pct']
| count | mean | max | ||
|---|---|---|---|---|
| day | smoker | |||
| Fri | No | 4 | 0.151650 | 0.187735 |
| Yes | 15 | 0.174783 | 0.263480 | |
| Sat | No | 45 | 0.158048 | 0.291990 |
| Yes | 42 | 0.147906 | 0.325733 | |
| Sun | No | 57 | 0.160113 | 0.252672 |
| Yes | 19 | 0.187250 | 0.710345 | |
| Thur | No | 45 | 0.160298 | 0.266312 |
| Yes | 17 | 0.163863 | 0.241255 |
위에서처럼 칼럼 이름과 메서드가 담긴 튜플의 리스트를 넘기는 것도 가능하다.3
ftuples = [('Durchschnitt', 'mean'), ('Abweichung', np.var)]
grouped['tip_pct', 'total_bill'].agg(ftuples)
| tip_pct | total_bill | ||||
|---|---|---|---|---|---|
| Durchschnitt | Abweichung | Durchschnitt | Abweichung | ||
| day | smoker | ||||
| Fri | No | 0.151650 | 0.000791 | 18.420000 | 25.596333 |
| Yes | 0.174783 | 0.002631 | 16.813333 | 82.562438 | |
| Sat | No | 0.158048 | 0.001581 | 19.661778 | 79.908965 |
| Yes | 0.147906 | 0.003767 | 21.276667 | 101.387535 | |
| Sun | No | 0.160113 | 0.001793 | 20.506667 | 66.099980 |
| Yes | 0.187250 | 0.023757 | 24.120000 | 109.046044 | |
| Thur | No | 0.160298 | 0.001503 | 17.113111 | 59.625081 |
| Yes | 0.163863 | 0.001551 | 19.190588 | 69.808518 | |
칼럼마다 다른 함수를 적용하고 싶다면 agg() 메서드에 칼럼 이름에 대응하는 함수가 들어 있는 사전을 넘기면 된다.
grouped.agg({'tip': np.max, 'size': 'sum'})
| tip | size | ||
|---|---|---|---|
| day | smoker | ||
| Fri | No | 3.50 | 9 |
| Yes | 4.73 | 31 | |
| Sat | No | 9.00 | 115 |
| Yes | 10.00 | 104 | |
| Sun | No | 6.00 | 167 |
| Yes | 6.50 | 49 | |
| Thur | No | 6.70 | 112 |
| Yes | 5.00 | 40 |
grouped.agg({'tip_pct': ['min', 'max', 'mean', 'std'],
'size': 'sum'})
| tip_pct | size | |||||
|---|---|---|---|---|---|---|
| min | max | mean | std | sum | ||
| day | smoker | |||||
| Fri | No | 0.120385 | 0.187735 | 0.151650 | 0.028123 | 9 |
| Yes | 0.103555 | 0.263480 | 0.174783 | 0.051293 | 31 | |
| Sat | No | 0.056797 | 0.291990 | 0.158048 | 0.039767 | 115 |
| Yes | 0.035638 | 0.325733 | 0.147906 | 0.061375 | 104 | |
| Sun | No | 0.059447 | 0.252672 | 0.160113 | 0.042347 | 167 |
| Yes | 0.065660 | 0.710345 | 0.187250 | 0.154134 | 49 | |
| Thur | No | 0.072961 | 0.266312 | 0.160298 | 0.038774 | 112 |
| Yes | 0.090014 | 0.241255 | 0.163863 | 0.039389 | 40 | |
단 하나의 칼럼에라도 여러 개의 함수가 적용되었다면 데이터프레임은 계층적인 칼럼을 가지게 된다.
색인되지 않은 형태로 집계된 데이터 반환하기
지금까지 살펴본 모든 예제에서 집계된 데이터는 유일한 그룹키 조합으로 색인(어떤 경우에는 계층적 색인)되어 반환되었다. 하지만 항상 이런 동작을 기대하는 것은 아니므로 groupby() 메서드에 as_index=False를 넘겨서 색인되지 않도록 할 수 있다.
tips.groupby(['day', 'smoker'], as_index=False).mean()
| day | smoker | total_bill | tip | size | tip_pct | |
|---|---|---|---|---|---|---|
| 0 | Fri | No | 18.420000 | 2.812500 | 2.250000 | 0.151650 |
| 1 | Fri | Yes | 16.813333 | 2.714000 | 2.066667 | 0.174783 |
| 2 | Sat | No | 19.661778 | 3.102889 | 2.555556 | 0.158048 |
| 3 | Sat | Yes | 21.276667 | 2.875476 | 2.476190 | 0.147906 |
| 4 | Sun | No | 20.506667 | 3.167895 | 2.929825 | 0.160113 |
| 5 | Sun | Yes | 24.120000 | 3.516842 | 2.578947 | 0.187250 |
| 6 | Thur | No | 17.113111 | 2.673778 | 2.488889 | 0.160298 |
| 7 | Thur | Yes | 19.190588 | 3.030000 | 2.352941 | 0.163863 |
물론 이렇게 하지 않고 색인된 결과에 대해 reset_index() 메서드를 호출해서 같은 결과를 얻을 수 있다. as_index=False 옵션을 사용하면 불필요한 계산을 피할 수 있다.
Transform: 그룹 연산 데이터 변환
앞에서 살펴본 agg() 메서드는 각 그룹별 데이터에 연산을 위한 함수를 구분 적용하고, 그룹별로 연산 결과를 집계하여 반환한다. 반면 transform() 메서드는 그룹별로 구분하여 각 원소에 함수를 적용하지만 그룹별 집계 대신 각 원소의 본래 행 인덱스와 열 이름을 기준으로 연산 결과를 반환한다. 즉, 그룹 연산의 결과를 원본 데이터프레임과 같은 형태로 변형하여 정리하는 것이다.
다음의 예제에서 ‘age’ 열에 포함된 개별 데이터의 z-score를 구하는 과정을 살펴보자. 먼저 앞에서 배운 집계 연산 메서드를 사용하여 개별 그룹의 평균과 표준편차를 계산한다. 그리고 각 그룹에 대해 반복문을 사용하여 z-score를 계산하고, 각 그룹별로 첫 3행의 결과를 출력한다.
# 라이브러리 불러오기
import pandas as pd
import seaborn as sns
# titanic 데이터셋에서 age, sex 등 5개 열을 선택하여 데이터프레임 만들기
titanic = sns.load_dataset('titanic')
df = titanic.loc[:, ['age', 'sex', 'class', 'fare', 'survived']]
# class 열을 기준으로 분할
grouped = df.groupby(['class'])
# 그룹별 age 열의 평균 집계 연산
age_mean = grouped.age.mean()
print(age_mean)
print('\n')
# 그룹별 age 열의 표준편차 집계 연산
age_std = grouped.age.std()
print(age_std)
print('\n')
# 그룹 객체의 age 열을 iteration으로 z-score를 계산하여 출력
for key, group in grouped.age:
group_zscore = (group - age_mean.loc[key]) / age_std.loc[key]
print('* origin :', key)
print(group_zscore.head(3)) # 각 그룹의 첫 3개의 행 출력
print('\n')
class First 38.233441 Second 29.877630 Third 25.140620 Name: age, dtype: float64 class First 14.802856 Second 14.001077 Third 12.495398 Name: age, dtype: float64 * origin : First 1 -0.015770 3 -0.218434 6 1.065103 Name: age, dtype: float64 * origin : Second 9 -1.134029 15 1.794317 17 NaN Name: age, dtype: float64 * origin : Third 0 -0.251342 2 0.068776 4 0.789041 Name: age, dtype: float64
이번에는 transform() 메서드를 사용하여 ‘age’ 열의 데이터를 z-score로 직접 변환한다. z-score를 계산하는 사용자 함수를 정의하고, transform() 메서드의 인자로 전달한다. 각 그룹별 평균과 표준편차를 이용하여 각 원소의 z-score를 계산하지만, 반환되는 객체는 그룹별로 나누지 않고 원래 행 인덱스 순서로 정렬된다. 이 경우 891명 승객의 데이터가 본래 행 인덱스 순서대로 정렬된다. 위의 계산 결과와 비교하기 위해 각 그룹의 첫 행에 해당하는 1, 9, 0 행을 출력한다.
# z-score를 계산하는 사용자 함수 정의
def z_score(x):
return (x - x.mean()) / x.std()
# transform() 메서드를 이용하여 age 열의 데이터를 z-score로 변환
age_zscore = grouped.age.transform(z_score)
print(age_zscore.loc[[1, 9, 0]]) # 1, 2, 3 그룹의 각 첫 데이터 확인(변환 결과)
print('\n')
print(len(age_zscore)) # transform 메서드 반환 값의 길이
print('\n')
print(age_zscore.loc[0:9]) # transform 메서드 반환 값 출력(첫 10개)
print('\n')
print(type(age_zscore)) # transform 메서드 반환 객체의 자료형
1 -0.015770 9 -1.134029 0 -0.251342 Name: age, dtype: float64 891 0 -0.251342 1 -0.015770 2 0.068776 3 -0.218434 4 0.789041 5 NaN 6 1.065103 7 -1.851931 8 0.148805 9 -1.134029 Name: age, dtype: float64 <class 'pandas.core.series.Series'>
Filter: 그룹 객체 필터링
그룹 객체에 filter() 메서드를 적용할 때 조건식을 가진 함수를 전달하면 조건이 참인 그룹만을 남긴다.
데이터 개수가 200개 이상인 그룹만을 따로 필터링한다. ‘class’ 열을 기준으로 구분된 3개의 그룹 중에서 조건을 충족하는 ‘First’와 ‘Third’인 그룹의 데이터만 추출된다.
# 데이터 개수가 200개 이상인 그룹만을 필터링하여 데이터프레임으로 반환
grouped_filter = grouped.filter(lambda x: len(x) >= 200)
print(grouped_filter.head())
print('\n')
print(grouped_filter['class'].unique())
print('\n')
print(type(grouped_filter))
age sex class fare survived
0 22.0 male Third 7.2500 0
1 38.0 female First 71.2833 1
2 26.0 female Third 7.9250 1
3 35.0 female First 53.1000 1
4 35.0 male Third 8.0500 0
['Third', 'First']
Categories (3, object): ['First', 'Second', 'Third']
<class 'pandas.core.frame.DataFrame'>
이번에는 ‘age’ 열의 평균값이 30보다 작은 그룹만을 따로 선택한다. 평균 나이가 30세가 안되는 그룹은 ‘class’ 값이 ‘Second’와 ‘Third’인 2등석과 3등석 승객들이다.
# age 열의 평균이 30보다 작은 그룹만을 필터링하여 데이터프레임으로 반환
age_filter = grouped.filter(lambda x: x.age.mean() < 30)
print(age_filter.tail())
print('\n')
print(age_filter['class'].unique())
print('\n')
print(type(age_filter))
age sex class fare survived
884 25.0 male Third 7.050 0
885 39.0 female Third 29.125 0
886 27.0 male Second 13.000 0
888 NaN female Third 23.450 0
890 32.0 male Third 7.750 0
['Third', 'Second']
Categories (3, object): ['First', 'Second', 'Third']
<class 'pandas.core.frame.DataFrame'>
Apply: 그룹 객체에 함수 매핑
apply() 메서드는 판다스 객체의 개별 원소를 특정 함수에 일대일로 매핑한다. 사용자가 원하는 대부분의 연산을 그룹 객체에도 적용할 수 있다.
‘class’ 열을 기준으로 구분한 3개의 그룹에 요약 통계 정보를 나타내는 describe() 메서드를 적용한다. 각 그룹별 데이터의 개수, 평균, 표준편차, 최소값, 최대값 등을 확인할 수 있다.
# 집계: 각 그룹별 요약 통계 정보 집계
agg_grouped = grouped.apply(lambda x: x.describe())
agg_grouped
| age | fare | survived | ||
|---|---|---|---|---|
| class | ||||
| First | count | 186.000000 | 216.000000 | 216.000000 |
| mean | 38.233441 | 84.154687 | 0.629630 | |
| std | 14.802856 | 78.380373 | 0.484026 | |
| min | 0.920000 | 0.000000 | 0.000000 | |
| 25% | 27.000000 | 30.923950 | 0.000000 | |
| 50% | 37.000000 | 60.287500 | 1.000000 | |
| 75% | 49.000000 | 93.500000 | 1.000000 | |
| max | 80.000000 | 512.329200 | 1.000000 | |
| Second | count | 173.000000 | 184.000000 | 184.000000 |
| mean | 29.877630 | 20.662183 | 0.472826 | |
| std | 14.001077 | 13.417399 | 0.500623 | |
| min | 0.670000 | 0.000000 | 0.000000 | |
| 25% | 23.000000 | 13.000000 | 0.000000 | |
| 50% | 29.000000 | 14.250000 | 0.000000 | |
| 75% | 36.000000 | 26.000000 | 1.000000 | |
| max | 70.000000 | 73.500000 | 1.000000 | |
| Third | count | 355.000000 | 491.000000 | 491.000000 |
| mean | 25.140620 | 13.675550 | 0.242363 | |
| std | 12.495398 | 11.778142 | 0.428949 | |
| min | 0.420000 | 0.000000 | 0.000000 | |
| 25% | 18.000000 | 7.750000 | 0.000000 | |
| 50% | 24.000000 | 8.050000 | 0.000000 | |
| 75% | 32.000000 | 15.500000 | 0.000000 | |
| max | 74.000000 | 69.550000 | 1.000000 |
z-score를 계산하는 사용자 함수를 사용하여 ‘age’ 열의 데이터를 z-score로 변환한다.
# z-score를 계산하는 사용자 함수 정의
def z_score(x):
return (x - x.mean()) / x.std()
age_zscore = grouped.age.apply(z_score) # 기본값 axis=0
age_zscore.head()
0 -0.251342 1 -0.015770 2 0.068776 3 -0.218434 4 0.789041 Name: age, dtype: float64
‘age’ 열의 평균값이 30보다 작은 즉, 평균나이가 30세 미만인 그룹을 판별한다. 조건이 참인 그룹은 ‘class’ 값이 ‘Second’와 ‘Third’인 그룹이다. 반복문을 사용하여 데이터를 출력한다.
# 필터링: age 열의 데이터 평균이 30보다 작은 그룹만을 필터링하여 출력
age_filter = grouped.apply(lambda x: x.age.mean() < 30)
print(age_filter)
print('\n')
for x in age_filter.index:
if age_filter[x]==True:
age_filter_df = grouped.get_group(x)
print(age_filter_df.head())
print('\n')
class
First False
Second True
Third True
dtype: bool
age sex class fare survived
9 14.0 female Second 30.0708 1
15 55.0 female Second 16.0000 1
17 NaN male Second 13.0000 1
20 35.0 male Second 26.0000 0
21 34.0 male Second 13.0000 1
age sex class fare survived
0 22.0 male Third 7.2500 0
2 26.0 female Third 7.9250 1
4 35.0 male Third 8.0500 0
5 NaN male Third 8.4583 0
7 2.0 male Third 21.0750 0
위 예제에서 쓰인 get_group() 메서드는 그룹 객체에서 특정 그룹만을 선택할 수 있다. 위에서는 x에 필터링 조건에 해당하는 ‘class’값인 ‘Second’와 ‘Third’가 들어가게 된다.
그룹별 상위 5개의 age 값을 골라보자. 우선 특정 칼럼에서 가장 큰 값을 가지는 로우를 선택하는 함수를 바로 작성해보자.
def top(df, n=5, column='age'):
return df.sort_values(by=column, ascending=False)[:n]
top(df)
| age | sex | class | fare | survived | |
|---|---|---|---|---|---|
| 630 | 80.0 | male | First | 30.0000 | 1 |
| 851 | 74.0 | male | Third | 7.7750 | 0 |
| 493 | 71.0 | male | First | 49.5042 | 0 |
| 96 | 71.0 | male | First | 34.6542 | 0 |
| 116 | 70.5 | male | Third | 7.7500 | 0 |
이제 ‘class’ 열 그룹에 대해 이 함수(top)를 apply하면 다음과 같은 결과를 얻을 수 있다.
df.groupby('class').apply(top)
| age | sex | class | fare | survived | ||
|---|---|---|---|---|---|---|
| class | ||||||
| First | 630 | 80.0 | male | First | 30.0000 | 1 |
| 493 | 71.0 | male | First | 49.5042 | 0 | |
| 96 | 71.0 | male | First | 34.6542 | 0 | |
| 745 | 70.0 | male | First | 71.0000 | 0 | |
| 456 | 65.0 | male | First | 26.5500 | 0 | |
| Second | 672 | 70.0 | male | Second | 10.5000 | 0 |
| 33 | 66.0 | male | Second | 10.5000 | 0 | |
| 570 | 62.0 | male | Second | 10.5000 | 1 | |
| 684 | 60.0 | male | Second | 39.0000 | 0 | |
| 232 | 59.0 | male | Second | 13.5000 | 0 | |
| Third | 851 | 74.0 | male | Third | 7.7750 | 0 |
| 116 | 70.5 | male | Third | 7.7500 | 0 | |
| 280 | 65.0 | male | Third | 7.7500 | 0 | |
| 483 | 63.0 | female | Third | 9.5875 | 1 | |
| 326 | 61.0 | male | Third | 6.2375 | 0 |
위 결과를 보면 top 함수가 나뉘어진 데이터프레임의 각 부분에 모두 적용이 되었고, pandas.concat()을 이용해서 하나로 합쳐진 다음 그룹 이름표(class)가 붙었다. 그리하여 결과는 계층적 색인을 가지게 되고 내부 색인은 원본 데이터프레임의 인덱스값을 가지게 된다.
만일 apply() 메서드로 넘길 함수가 추가적인 인자를 받는다면 함수 이름 뒤에 붙여서 넘겨주면 된다.
df.groupby(['class', 'sex']).apply(top, n=1, column='age')
| age | sex | class | fare | survived | |||
|---|---|---|---|---|---|---|---|
| class | sex | ||||||
| First | female | 275 | 63.0 | female | First | 77.9583 | 1 |
| male | 630 | 80.0 | male | First | 30.0000 | 1 | |
| Second | female | 772 | 57.0 | female | Second | 10.5000 | 0 |
| male | 672 | 70.0 | male | Second | 10.5000 | 0 | |
| Third | female | 483 | 63.0 | female | Third | 9.5875 | 1 |
| male | 851 | 74.0 | male | Third | 7.7750 | 0 |
NOTE_여기서 소개하는 기본적인 사용 방법 외에도 apply() 메서드를 창의적인 방법으로 다양하게 사용할 수 있다. 넘기는 함수 안에서 하는 일은 전적으로 사용자에게 달려 있다. 단치 판다스 객체나 스칼라값을 반환하는 함수면 된다. 이 페이지의 남은 부분에서는 주로 groupby()를 사용해서 다양한 문제를 해결하는 방법을 보여주는 에제를 다룰 것이다.
그룹 색인 생략하기
앞서 살펴본 예제들에서 반환된 객체는 원본 객체의 각 조각에 대한 인덱스와 그룹 키가 계층적 색인으로 사용됨을 볼 수 있었다. 이런 결과는 groupby() 메서드에 group_keys=False를 넘겨서 막을 수 있다.
df.groupby('sex', group_keys=False).apply(top)
| age | sex | class | fare | survived | |
|---|---|---|---|---|---|
| 483 | 63.0 | female | Third | 9.5875 | 1 |
| 275 | 63.0 | female | First | 77.9583 | 1 |
| 829 | 62.0 | female | First | 80.0000 | 1 |
| 366 | 60.0 | female | First | 75.2500 | 1 |
| 268 | 58.0 | female | First | 153.4625 | 1 |
| 630 | 80.0 | male | First | 30.0000 | 1 |
| 851 | 74.0 | male | Third | 7.7750 | 0 |
| 96 | 71.0 | male | First | 34.6542 | 0 |
| 493 | 71.0 | male | First | 49.5042 | 0 |
| 116 | 70.5 | male | Third | 7.7500 | 0 |
변위치 분석과 버킷 분석
판다스의 cut()과 qcut() 메서드를 사용해서 선택한 크기만큼 혹은 표본 변위치에 따라 데이터를 나눌 수 있었다. 즉, 동일한 길이로 나누거나 동일한 개수로 나눌 수 있었다. 이 함수들을 groupby()와 조합하면 데이터 묶음에 대해 변위치 분석이나 버킷 분석을 매우 쉽게 수행할 수 있다. 임의의 데이터 묶음을 cut()을 이용해서 등간격 구간으로 나누어보자.
frame = pd.DataFrame({'data1': np.random.randn(1000),
'data2': np.random.randn(1000)})
quartiles = pd.cut(frame.data1, 4)
quartiles[:10]
0 (-0.104, 1.396] 1 (1.396, 2.895] 2 (-1.603, -0.104] 3 (-0.104, 1.396] 4 (-3.109, -1.603] 5 (-0.104, 1.396] 6 (-0.104, 1.396] 7 (-0.104, 1.396] 8 (-1.603, -0.104] 9 (-0.104, 1.396] Name: data1, dtype: category Categories (4, interval[float64, right]): [(-3.109, -1.603] < (-1.603, -0.104] < (-0.104, 1.396] < (1.396, 2.895]]
cut()에서 반환된 Categorical 객체는 바로 groupby()로 넘길 수 있다. 그러므로 data2 칼럼에 대한 몇 가지 통계를 다음과 같이 계산할 수 있다.
def get_stats(group):
return {'min': group.min(), 'max': group.max(),
'count': group.count(), 'mean': group.mean()}
grouped = frame.data2.groupby(quartiles)
grouped.apply(get_stats).unstack()
| min | max | count | mean | |
|---|---|---|---|---|
| data1 | ||||
| (-3.109, -1.603] | -2.394062 | 2.082127 | 58.0 | -0.007639 |
| (-1.603, -0.104] | -3.030777 | 2.478698 | 378.0 | -0.006070 |
| (-0.104, 1.396] | -3.171915 | 3.101419 | 476.0 | -0.062328 |
| (1.396, 2.895] | -1.829379 | 2.569917 | 88.0 | 0.015193 |
이는 등간격 버킷이었고, 표본 변위치에 기반하여 크키가 같은 버킷을 계산하려면 qcut()을 사용한다. 다음 예제에서는 labels=False를 넘겨서 변위치 숫자를 구했다.
# 변위치 숫자를 반환
grouping = pd.qcut(frame.data1, 10, labels=False)
grouped = frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()
| min | max | count | mean | |
|---|---|---|---|---|
| data1 | ||||
| 0 | -2.908298 | 2.359413 | 100.0 | -0.024017 |
| 1 | -3.030777 | 2.478698 | 100.0 | -0.108802 |
| 2 | -2.446722 | 2.361564 | 100.0 | 0.130300 |
| 3 | -2.235216 | 2.091979 | 100.0 | -0.096549 |
| 4 | -2.536442 | 2.272229 | 100.0 | 0.015848 |
| 5 | -2.557897 | 2.120211 | 100.0 | -0.030039 |
| 6 | -3.171915 | 2.274249 | 100.0 | -0.155419 |
| 7 | -2.588174 | 2.690629 | 100.0 | -0.155062 |
| 8 | -2.831150 | 3.101419 | 100.0 | 0.075913 |
| 9 | -2.565913 | 2.569917 | 100.0 | 0.037139 |
예제: 그룹에 따른 값으로 결측치 채우기
누락된 데이터를 정리할 때면 어떤 경우에는 dropna()를 사용해서 데이터를 살펴보고 걸러내기도 한다. 하지만 어떤 경우에는 누락된 값을 고정된 값이나 혹은 데이터로부터 도출된 어떤 값으로 채우고 싶을 때도 있다. 이런 경우 fillna() 메서드를 사용하는데, 누락된 값을 평균값으로 대체하는 예제를 살펴보자.
s = pd.Series(np.random.randn(6))
s[::2] = np.nan
s
0 NaN 1 0.321992 2 NaN 3 0.409872 4 NaN 5 -0.225796 dtype: float64
s.fillna(s.mean())
0 0.168689 1 0.321992 2 0.168689 3 0.409872 4 0.168689 5 -0.225796 dtype: float64
그룹별로 채워 넣고 싶은 값이 다르다고 가정해보자. 아마도 추측했듯이 데이터를 그룹으로 나누고 apply 함수를 사용해서 각 그룹에 대해 fillna를 적용하면 된다. 여기서 사용된 데이터는 동부와 서부로 나눈 미국의 지역에 대한 데이터다.
states = ['Ohio', 'New York', 'Vermont', 'Florida',
'Oregon', 'Nevada', 'California', 'Idaho']
group_key = ['East'] * 4 + ['West'] * 4
data = pd.Series(np.random.randn(8), index=states)
data
Ohio 0.744933 New York 0.831884 Vermont 0.724275 Florida 0.455120 Oregon 0.846945 Nevada -0.660623 California 0.319344 Idaho 0.030500 dtype: float64
데이터에서 몇몇 값을 결측치로 만들어보자.
data[['Vermont', 'Nevada', 'Idaho']] = np.nan
data
Ohio 0.744933 New York 0.831884 Vermont NaN Florida 0.455120 Oregon 0.846945 Nevada NaN California 0.319344 Idaho NaN dtype: float64
data.groupby(group_key).mean()
East 0.677312 West 0.583144 dtype: float64
다음과 같이 누락된 값을 그룹의 평균값으로 채울 수 있다.
fill_mean = lambda g: g.fillna(g.mean())
data.groupby(group_key).apply(fill_mean)
Ohio 0.744933 New York 0.831884 Vermont 0.677312 Florida 0.455120 Oregon 0.846945 Nevada 0.583144 California 0.319344 Idaho 0.583144 dtype: float64
아니면 그룹에 따라 미리 정의된 다른 값을 채워 넣어야 할 경우도 있다. 각 그룹은 내부적으로 name이라는 속성을 가지고 있으므로 이를 이용하자.
fill_values = {'East': 0.5, 'West': -1}
fill_func = lambda g: g.fillna(fill_values[g.name])
data.groupby(group_key).apply(fill_func)
Ohio 0.744933 New York 0.831884 Vermont 0.500000 Florida 0.455120 Oregon 0.846945 Nevada -1.000000 California 0.319344 Idaho -1.000000 dtype: float64
예제: 랜덤 표본과 순열
대용량의 데이터를 몬테카를로 시뮬레이션이나 다른 애플리케이션에서 사용하기 위해 랜덤 표본을 뽑아낸다고 해보자. 뽑아내는 방법은 여러 가지가 있는데, 여기서는 Series의 sample() 메서드를 사용하자.
예시를 위해 트럼프 카드 덱을 한번 만들어보자.
# 하트, 스페이드, 클러버, 다이아몬드
suits = ['H', 'S', 'C', 'D']
card_val = (list(range(1, 11)) + [10] * 3) * 4
base_names = ['A'] + list(range(2, 11)) + ['J', 'K', 'Q']
cards = []
for suit in suits:
cards.extend(str(num) + suit for num in base_names)
deck = pd.Series(card_val, index=cards)
이렇게 해서 블랙잭 같은 게임에서 사용하는 카드 이름과 값을 색인으로 하는 52장의 카드가 시리즈 객체로 준비되었다(단순히 하기 위해 에이스 ‘A’를 1로 취급했다).
deck[:13]
AH 1 2H 2 3H 3 4H 4 5H 5 6H 6 7H 7 8H 8 9H 9 10H 10 JH 10 KH 10 QH 10 dtype: int64
이제 앞에서 얘기한 것처럼 5장의 카드를 뽑기 위해 다음 코드를 작성한다.
def draw(deck, n=5):
return deck.sample(n)
draw(deck)
7D 7 4D 4 6H 6 JS 10 7S 7 dtype: int64
각 세트(하트, 스페이드, 클러버, 다이아몬드)별로 2장의 카드를 무작위로 뽑고 싶다고 가정하자. 세트는 각 카드 이름의 마지막 글자이므로 이를 이용해서 그룹을 나누고 apply()를 사용하자.
get_suit = lambda card: card[-1] # 마지막 글자가 세트
deck.groupby(get_suit).apply(draw, n=2)
C 8C 8 6C 6 D 9D 9 JD 10 H 9H 9 3H 3 S 9S 9 7S 7 dtype: int64
아래와 같은 방법으로 각 세트별 2장의 카드를 무작위로 뽑을 수도 있다.
deck.groupby(get_suit, group_keys=False).apply(draw, n=2)
5C 5 KC 10 KD 10 2D 2 QH 10 7H 7 5S 5 7S 7 dtype: int64
예제: 그룹 가중 평균과 상관관계
groupby()의 나누고 적용하고 합치는 패러다임에서 (그룹 가중 평균과 같은) 데이터프레임의 칼럼 간 연산이나 두 시리즈 간의 연산은 일상적인 일이다. 예를 들어 그룹 키와 값 그리고 어떤 가중치를 갖는 다음 데이터 묶음을 살펴보자.
df = pd.DataFrame({'category': ['a', 'a', 'a', 'a',
'b', 'b', 'b', 'b'],
'data': np.random.randn(8),
'weights': np.random.rand(8)})
df
| category | data | weights | |
|---|---|---|---|
| 0 | a | 1.209936 | 0.377531 |
| 1 | a | 0.824663 | 0.328378 |
| 2 | a | 0.663372 | 0.331725 |
| 3 | a | 0.671434 | 0.517987 |
| 4 | b | 1.256572 | 0.116242 |
| 5 | b | -2.311121 | 0.768394 |
| 6 | b | -0.122240 | 0.234716 |
| 7 | b | 1.163265 | 0.753302 |
category 별 그룹 가중 평균을 보면 다음과 같다.
grouped = df.groupby('category')
get_wavg = lambda g: np.average(g['data'], weights=g['weights'])
grouped.apply(get_wavg)
category a 0.832748 b -0.417689 dtype: float64
좀 더 복잡한 예제로 야후! 파이낸스에서 가져온 몇몇 주식과 S&P 500 지수(종목 코드 SPX)의 종가 데이터를 살펴보자.
close_px = pd.read_csv('examples/stock_px_2.csv', parse_dates=True,
index_col=0)
close_px.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 2214 entries, 2003-01-02 to 2011-10-14 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 AAPL 2214 non-null float64 1 MSFT 2214 non-null float64 2 XOM 2214 non-null float64 3 SPX 2214 non-null float64 dtypes: float64(4) memory usage: 86.5 KB
close_px[-4:]
| AAPL | MSFT | XOM | SPX | |
|---|---|---|---|---|
| 2011-10-11 | 400.29 | 27.00 | 76.27 | 1195.54 |
| 2011-10-12 | 402.19 | 26.96 | 77.16 | 1207.25 |
| 2011-10-13 | 408.43 | 27.18 | 76.37 | 1203.66 |
| 2011-10-14 | 422.00 | 27.27 | 78.11 | 1224.58 |
퍼센트 변화율로 일일 수익률을 계산하여 연간 SPX 지수와의 상관관계를 살펴보는 일은 흥미로울 수 있는데, 다음과 같이 구할 수 있다. 우선 ‘SPX’ 칼럼과 다른 칼럼의 상관관계를 계산하는 함수를 만든다.
spx_corr = lambda x: x.corrwith(x['SPX'])
그리고 pct_change() 함수를 이용해서 close_px의 퍼센트 변화율을 계산한다.
rets = close_px.pct_change().dropna()
rets
| AAPL | MSFT | XOM | SPX | |
|---|---|---|---|---|
| 2003-01-03 | 0.006757 | 0.001421 | 0.000684 | -0.000484 |
| 2003-01-06 | 0.000000 | 0.017975 | 0.024624 | 0.022474 |
| 2003-01-07 | -0.002685 | 0.019052 | -0.033712 | -0.006545 |
| 2003-01-08 | -0.020188 | -0.028272 | -0.004145 | -0.014086 |
| 2003-01-09 | 0.008242 | 0.029094 | 0.021159 | 0.019386 |
| ... | ... | ... | ... | ... |
| 2011-10-10 | 0.051406 | 0.026286 | 0.036977 | 0.034125 |
| 2011-10-11 | 0.029526 | 0.002227 | -0.000131 | 0.000544 |
| 2011-10-12 | 0.004747 | -0.001481 | 0.011669 | 0.009795 |
| 2011-10-13 | 0.015515 | 0.008160 | -0.010238 | -0.002974 |
| 2011-10-14 | 0.033225 | 0.003311 | 0.022784 | 0.017380 |
2213 rows × 4 columns
마지막으로 각 datetims에서 연도 속성만 반환하는 한줄 짜리 함수를 이용해서 연도별 퍼센트 변화율을 구한다.
get_year = lambda x: x.year
by_year = rets.groupby(get_year)
by_year.apply(spx_corr)
| AAPL | MSFT | XOM | SPX | |
|---|---|---|---|---|
| 2003 | 0.541124 | 0.745174 | 0.661265 | 1.0 |
| 2004 | 0.374283 | 0.588531 | 0.557742 | 1.0 |
| 2005 | 0.467540 | 0.562374 | 0.631010 | 1.0 |
| 2006 | 0.428267 | 0.406126 | 0.518514 | 1.0 |
| 2007 | 0.508118 | 0.658770 | 0.786264 | 1.0 |
| 2008 | 0.681434 | 0.804626 | 0.828303 | 1.0 |
| 2009 | 0.707103 | 0.654902 | 0.797921 | 1.0 |
| 2010 | 0.710105 | 0.730118 | 0.839057 | 1.0 |
| 2011 | 0.691931 | 0.800996 | 0.859975 | 1.0 |
물론 두 칼럼 간의 상관관계를 계산하는 것도 가능하다. 다음은 애플(‘AAPL’)과 마이크로소프트(‘MSFT’) 주가의 연간 상관관계다.
by_year.apply(lambda g: g['AAPL'].corr(g['MSFT']))
2003 0.480868 2004 0.259024 2005 0.300093 2006 0.161735 2007 0.417738 2008 0.611901 2009 0.432738 2010 0.571946 2011 0.581987 dtype: float64
예제: 그룹상의 선형회귀
이전 예제와 같은 맥락으로, 판다스 객체나 스칼라값을 반환하기만 한다면 groupby()를 좀 더 복잡한 그룹상의 통계 분석을 위해 사용할 수 있다. 예를 들어 계량경제 라이브러리econometrics library인 statsmodels를 사용해서 regress라는 함수를 작성하고 각 데이터 묶음마다 최소제곱Ordinary Least Squares, OLS으로 회귀를 수행할 수 있다.
import statsmodels.api as sm
def regress(data, yvar, xvars):
Y = data[yvar]
X = data[xvars]
X['intercept'] = 1.
result = sm.OLS(Y, X).fit()
return result.params
이제 SPX 수익률에 대한 애플(‘AAPL’) 주식의 연간 선형회귀는 다음과 같이 수행할 수 있다.
by_year.apply(regress, 'AAPL', ['SPX'])
| SPX | intercept | |
|---|---|---|
| 2003 | 1.195406 | 0.000710 |
| 2004 | 1.363463 | 0.004201 |
| 2005 | 1.766415 | 0.003246 |
| 2006 | 1.645496 | 0.000080 |
| 2007 | 1.198761 | 0.003438 |
| 2008 | 0.968016 | -0.001110 |
| 2009 | 0.879103 | 0.002954 |
| 2010 | 1.052608 | 0.001261 |
| 2011 | 0.806605 | 0.001514 |
피벗테이블과 교차일람표
피벗테이블은 스프레드시트 프로그램과 그 외 다른 데이터 분석 소프트웨어에서 흔히 볼 수 있는 데이터 요약화 도구다. 피벗테이블은 데이터를 하나 이상의 키로 수집해서 어떤 키는 로우에, 어떤 키는 칼럼에 나열해서 데이터를 정렬한다. 판다스에서 피벗테이블은 이 장에서 설명했던 groupby() 기능을 사용해서 계층적 색인을 활용한 재형성 연산을 가능하게 해준다. 데이터프레임에는 pivot_table() 메서드가 있는데 이는 판다스 모듈의 최상위 함수로도 존재한다(pandas.pivot_table()). groupby()를 위한 편리한 인터페이스를 제공하기 위해 pivot_table()은 마진이라고 하는 부분합을 추가할 수 있는 기능을 제공한다.
팁 데이터로 돌아가서 요일(day)과 흡연자(smoker) 집단에서 평균(pivot_table()의 기본 연산)을 구해보자.
tips.pivot_table(index=['day', 'smoker'])
| size | tip | tip_pct | total_bill | ||
|---|---|---|---|---|---|
| day | smoker | ||||
| Fri | No | 2.250000 | 2.812500 | 0.151650 | 18.420000 |
| Yes | 2.066667 | 2.714000 | 0.174783 | 16.813333 | |
| Sat | No | 2.555556 | 3.102889 | 0.158048 | 19.661778 |
| Yes | 2.476190 | 2.875476 | 0.147906 | 21.276667 | |
| Sun | No | 2.929825 | 3.167895 | 0.160113 | 20.506667 |
| Yes | 2.578947 | 3.516842 | 0.187250 | 24.120000 | |
| Thur | No | 2.488889 | 2.673778 | 0.160298 | 17.113111 |
| Yes | 2.352941 | 3.030000 | 0.163863 | 19.190588 |
이는 groupby()를 사용해서 쉽게 구할 수 있는데, 이제 tip_pct와 size에 대해서만 집계를 하고 날짜(time)별로 그룹지어보자. 이를 위해 day 로우와 smoker 칼럼을 추가했다.
tips.pivot_table(values=['tip_pct', 'size'], index=['time', 'day'],
columns='smoker')
| size | tip_pct | ||||
|---|---|---|---|---|---|
| smoker | No | Yes | No | Yes | |
| time | day | ||||
| Dinner | Fri | 2.000000 | 2.222222 | 0.139622 | 0.165347 |
| Sat | 2.555556 | 2.476190 | 0.158048 | 0.147906 | |
| Sun | 2.929825 | 2.578947 | 0.160113 | 0.187250 | |
| Thur | 2.000000 | NaN | 0.159744 | NaN | |
| Lunch | Fri | 3.000000 | 1.833333 | 0.187735 | 0.188937 |
| Thur | 2.500000 | 2.352941 | 0.160311 | 0.163863 | |
이 테이블은 margins=True를 넘겨서 부분합을 포함하도록 확장할 수 있는데, 그렇게 하면 All 칼럼과 All 로우가 추가되어 단일 줄 안에서 그룹 통계를 얻을 수 있다.
tips.pivot_table(values=['tip_pct', 'size'], index=['time', 'day'],
columns='smoker', margins=True)
| size | tip_pct | ||||||
|---|---|---|---|---|---|---|---|
| smoker | No | Yes | All | No | Yes | All | |
| time | day | ||||||
| Dinner | Fri | 2.000000 | 2.222222 | 2.166667 | 0.139622 | 0.165347 | 0.158916 |
| Sat | 2.555556 | 2.476190 | 2.517241 | 0.158048 | 0.147906 | 0.153152 | |
| Sun | 2.929825 | 2.578947 | 2.842105 | 0.160113 | 0.187250 | 0.166897 | |
| Thur | 2.000000 | NaN | 2.000000 | 0.159744 | NaN | 0.159744 | |
| Lunch | Fri | 3.000000 | 1.833333 | 2.000000 | 0.187735 | 0.188937 | 0.188765 |
| Thur | 2.500000 | 2.352941 | 2.459016 | 0.160311 | 0.163863 | 0.161301 | |
| All | 2.668874 | 2.408602 | 2.569672 | 0.159328 | 0.163196 | 0.160803 | |
여기서 All 값은 흡연자와 비흡연자를 구분하지 않은 평균값(All 칼럼)이거나 로우에서 두 단계를 묶은 그룹의 평균값(All 로우)이다.
다른 집계함수를 사용하려면 그냥 aggfunc로 넘기면 되는데, 예를 들어 ‘count’나 len() 함수는 그룹 크기의 교차일람표(총 개수나 빈도)를 반환한다.
tips.pivot_table(values='tip_pct', index=['time', 'smoker'], columns='day',
aggfunc=len, margins=True)
| day | Fri | Sat | Sun | Thur | All | |
|---|---|---|---|---|---|---|
| time | smoker | |||||
| Dinner | No | 3.0 | 45.0 | 57.0 | 1.0 | 106 |
| Yes | 9.0 | 42.0 | 19.0 | NaN | 70 | |
| Lunch | No | 1.0 | NaN | NaN | 44.0 | 45 |
| Yes | 6.0 | NaN | NaN | 17.0 | 23 | |
| All | 19.0 | 87.0 | 76.0 | 62.0 | 244 |
만약 어떤 조합이 비어 있다면(혹은 NA 값) fill_value를 넘길 수도 있다.
tips.pivot_table(values='tip_pct', index=['time', 'size', 'smoker'],
columns='day', aggfunc='mean', fill_value=0)
| day | Fri | Sat | Sun | Thur | ||
|---|---|---|---|---|---|---|
| time | size | smoker | ||||
| Dinner | 1 | No | 0.000000 | 0.137931 | 0.000000 | 0.000000 |
| Yes | 0.000000 | 0.325733 | 0.000000 | 0.000000 | ||
| 2 | No | 0.139622 | 0.162705 | 0.168859 | 0.159744 | |
| Yes | 0.171297 | 0.148668 | 0.207893 | 0.000000 | ||
| 3 | No | 0.000000 | 0.154661 | 0.152663 | 0.000000 | |
| Yes | 0.000000 | 0.144995 | 0.152660 | 0.000000 | ||
| 4 | No | 0.000000 | 0.150096 | 0.148143 | 0.000000 | |
| Yes | 0.117750 | 0.124515 | 0.193370 | 0.000000 | ||
| 5 | No | 0.000000 | 0.000000 | 0.206928 | 0.000000 | |
| Yes | 0.000000 | 0.106572 | 0.065660 | 0.000000 | ||
| 6 | No | 0.000000 | 0.000000 | 0.103799 | 0.000000 | |
| Lunch | 1 | No | 0.000000 | 0.000000 | 0.000000 | 0.181728 |
| Yes | 0.223776 | 0.000000 | 0.000000 | 0.000000 | ||
| 2 | No | 0.000000 | 0.000000 | 0.000000 | 0.166005 | |
| Yes | 0.181969 | 0.000000 | 0.000000 | 0.158843 | ||
| 3 | No | 0.187735 | 0.000000 | 0.000000 | 0.084246 | |
| Yes | 0.000000 | 0.000000 | 0.000000 | 0.204952 | ||
| 4 | No | 0.000000 | 0.000000 | 0.000000 | 0.138919 | |
| Yes | 0.000000 | 0.000000 | 0.000000 | 0.155410 | ||
| 5 | No | 0.000000 | 0.000000 | 0.000000 | 0.121389 | |
| 6 | No | 0.000000 | 0.000000 | 0.000000 | 0.173706 |
데이터프레임 pdf의 행을 선택하기 위해 xs 인덱서를 사용하는 방법을 살펴보자. xs 인덱서는 기본값으로 행 인덱스에 접근하고, 축 값은 axis=0으로 자동 설정된다. 먼저 행 인덱스가 ‘Dinner’인 점심 시간의 데이터를 추출해보자.
pdf = tips.pivot_table(values=['tip_pct', 'size'], index=['time', 'day'],
columns='smoker', margins=True)
pdf
| size | tip_pct | ||||||
|---|---|---|---|---|---|---|---|
| smoker | No | Yes | All | No | Yes | All | |
| time | day | ||||||
| Dinner | Fri | 2.000000 | 2.222222 | 2.166667 | 0.139622 | 0.165347 | 0.158916 |
| Sat | 2.555556 | 2.476190 | 2.517241 | 0.158048 | 0.147906 | 0.153152 | |
| Sun | 2.929825 | 2.578947 | 2.842105 | 0.160113 | 0.187250 | 0.166897 | |
| Thur | 2.000000 | NaN | 2.000000 | 0.159744 | NaN | 0.159744 | |
| Lunch | Fri | 3.000000 | 1.833333 | 2.000000 | 0.187735 | 0.188937 | 0.188765 |
| Thur | 2.500000 | 2.352941 | 2.459016 | 0.160311 | 0.163863 | 0.161301 | |
| All | 2.668874 | 2.408602 | 2.569672 | 0.159328 | 0.163196 | 0.160803 | |
pdf.xs('Dinner') # 행 인덱스가 Dinner인 행을 선택
| size | tip_pct | |||||
|---|---|---|---|---|---|---|
| smoker | No | Yes | All | No | Yes | All |
| day | ||||||
| Fri | 2.000000 | 2.222222 | 2.166667 | 0.139622 | 0.165347 | 0.158916 |
| Sat | 2.555556 | 2.476190 | 2.517241 | 0.158048 | 0.147906 | 0.153152 |
| Sun | 2.929825 | 2.578947 | 2.842105 | 0.160113 | 0.187250 | 0.166897 |
| Thur | 2.000000 | NaN | 2.000000 | 0.159744 | NaN | 0.159744 |
다음으로 행 인덱스 레벨 0에서 ‘Dinner’를 가져오고, 행 인덱스 레벨 1에서 ‘Sun’을 가져온다. 두 개의 인덱스 값을 튜플로 전달하면 일요일 점심 시간의 데이터만을 선택할 수 있다.
pdf.xs(('Dinner', 'Sun')) # 행 인덱스가 ('Dinner', 'Sun')인 행을 선택
smoker
size No 2.929825
Yes 2.578947
All 2.842105
tip_pct No 0.160113
Yes 0.187250
All 0.166897
Name: (Dinner, Sun), dtype: float64
이번에는 행 인덱스 레벨을 직접 지정하는 방법이다. ‘day’ 레벨에서 토요일을 나타내는 ‘Sat’에 해당하는 데이터만을 추출한다.
pdf.xs('Sat', level='day') # 행 인덱스의 day 레벨이 Sat인 행을 선택
| size | tip_pct | |||||
|---|---|---|---|---|---|---|
| smoker | No | Yes | All | No | Yes | All |
| time | ||||||
| Dinner | 2.555556 | 2.47619 | 2.517241 | 0.158048 | 0.147906 | 0.153152 |
마지막으로 행 인덱스 레벨 0에서 ‘Lunch’를 가져오고 행 인덱스 레벨 ‘day’에서 ‘Fri’을 가져온다. 이때 레벨 이름 ‘day’ 대신에 숫자형 레벨 1을 사용해도 결과는 동일하다.
pdf.xs(('Lunch', 'Fri'), level=[0, 'day']) # Lunch, Fri인 행을 선택
| size | tip_pct | ||||||
|---|---|---|---|---|---|---|---|
| smoker | No | Yes | All | No | Yes | All | |
| time | day | ||||||
| Lunch | Fri | 3.0 | 1.833333 | 2.0 | 0.187735 | 0.188937 | 0.188765 |
xs 인덱서를 이용하여 열 인덱스에 접근하기 위해서는 축 값을 axis=1로 설정해야 한다. 먼저 데이터프레임 pdf의 ‘size’ 열을 선택하여 식사를 한 사람 평균 명수 데이터를 추출한다.
pdf.xs('size', axis=1)
| smoker | No | Yes | All | |
|---|---|---|---|---|
| time | day | |||
| Dinner | Fri | 2.000000 | 2.222222 | 2.166667 |
| Sat | 2.555556 | 2.476190 | 2.517241 | |
| Sun | 2.929825 | 2.578947 | 2.842105 | |
| Thur | 2.000000 | NaN | 2.000000 | |
| Lunch | Fri | 3.000000 | 1.833333 | 2.000000 |
| Thur | 2.500000 | 2.352941 | 2.459016 | |
| All | 2.668874 | 2.408602 | 2.569672 |
다음 표에 pivot_table() 메서드를 요약해두었다.
| 함수 | 설명 |
|---|---|
| values | 집계하려는 칼럼 이름 혹은 이름의 리스트. 기본적으로 모든 숫자 칼럼을 집계한다. |
| index | 만들어지는 피벗테이블의 로우를 그룹으로 묶을 칼럼 이름이나 그룹 키 |
| columns | 만들어지는 피벗테이블의 칼럼을 그룹으로 묶을 칼럼 이름이나 그룹 키 |
| aggfunc | 집계함수나 함수 리스트. 기본값으로 'mean'이 사용된다. groupby 컨텍스트 안에서 유효한 어떤 함수라도 가능하다. |
| fill_value | 결과 테이블에서 누락된 값을 대체하기 위한 값 |
| dropna | True인 경우 모든 항목이 NA인 칼럼은 포함하지 않는다. |
| margins | 부분합이나 총계를 담기 위한 로우/칼럼을 추가할지 여부. 기본값은 False |
교차일람표
교차일람표(또는 교차표)는 그룹 빈도를 계산하기 위한 피벗테이블의 특수한 경우다. 다음은 위키피디아의 교차일람표 페이지에서 가져온 기본 예제다.
data
| Sample | Nationality | Handedness | |
|---|---|---|---|
| 0 | 1 | USA | Right-handed |
| 1 | 2 | Japan | Left-handed |
| 2 | 3 | USA | Right-handed |
| 3 | 4 | Japan | Right-handed |
| 4 | 5 | Japan | Left-handed |
| 5 | 6 | Japan | Right-handed |
| 6 | 7 | USA | Right-handed |
| 7 | 8 | USA | Left-handed |
| 8 | 9 | Japan | Right-handed |
| 9 | 10 | USA | Right-handed |
설문 분석의 일부로서 이 데이터를 국적nationality과 잘 쓰는 손handedness에 따라 요약해보자. 이를 위해 pivot_table() 메서드를 사용할 수 있지만 pandas.crosstab() 함수가 훨씬 더 편리하다.
pd.crosstab(data.Nationality, data.Handedness, margins=True)
| Handedness | Left-handed | Right-handed | All |
|---|---|---|---|
| Nationality | |||
| Japan | 2 | 3 | 5 |
| USA | 1 | 4 | 5 |
| All | 3 | 7 | 10 |
crosstab() 함수의 처음 두 인자는 배열이나 시리즈 혹은 배열의 리스트가 될 수 있다. 팁 데이터에 대해 교차표를 구해보자.
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)
| smoker | No | Yes | All | |
|---|---|---|---|---|
| time | day | |||
| Dinner | Fri | 3 | 9 | 12 |
| Sat | 45 | 42 | 87 | |
| Sun | 57 | 19 | 76 | |
| Thur | 1 | 0 | 1 | |
| Lunch | Fri | 1 | 6 | 7 |
| Thur | 44 | 17 | 61 | |
| All | 151 | 93 | 244 |
댓글남기기