시계열
시계열
시계열 데이터는 금융, 경제, 생태학, 신경과학, 물리학 등 여러 다양한 분야에서 사용되는 매우 중요한 구조화된 데이터다. 시간상의 여러 지점을 관측하거나 측정할 수 있는 모든 것이 시계열이다. 대부분의 시계열은 고정 빈도fixed frequency로 표현되는데 데이터가 존재하는 지점이 15초마다, 5분마다, 한 달에 한 번 같은 특정 규칙에 따라 고정 간격을 가지게 된다. 시계열은 또한 고정된 단위나 시간 혹은 단위들 간의 간격으로 존재하지 않고 불규칙적인 모습으로 표현될 수도 있다. 어떻게 시계열 데이터를 표시하고 참조할지는 애플리케이션에 의존적이며 다음 중 한 유형일 수 있다.
-
시간 내에서 특정 순간의 타임스탬프
-
2007년 1월이나 2010년 전체 같은 고정된 기간
-
시작과 끝 타임스탬프로 표시되는 시간 간격. 기간은 시간 간격의 특수한 경우로 생각할 수 있다.
-
실험 혹은 경과 시간. 각 타임스탬프는 특정 시작 시간에 상대적인 시간의 측정값이다(예: 쿠키를 오븐에 넣은 시점부터 매 초가 지날 때마다의 쿠키 반죽의 지름).
실험의 시작 시점부터의 경과 시간이 정수나 부동소수점으로 표현되는 경우 실험 시계열에도 해당 기술들을 적용할 수 있지만 이 장에서는 위에서 소개한 시계열 데이터의 처음 3가지 종류에 대해 주로 알아볼 것이다. 가장 단순하고 널리 사용되는 시계열의 종류는 타임스탬프로 색인된 데이터다.
TIP 판다스는 시간차에 기반한 색인을 지원하며, 이는 경과 시간을 나타낼 때 유용하다. 자세한 내용은 판다스 공식 문서를 참고하자.
판다스는 표준 시계열 도구와 데이터 알고리즘을 제공한다. 이를 통해 대량의 시계열 데이터를 효과적으로 다룰 수 있으며 쉽게 나누고, 집계하고, 불규칙적이며 고정된 빈도를 갖는 시계열을 리샘플링할 수 있다. 눈치 챘겠지만 대부분의 도구는 금융이나 경제 관련 애플리케이션에서 특히 유용하다. 하지만 서버 로그 데이터를 분석하는 데도 사용할 수 있다.
날짜, 시간 자료형, 도구
파이썬 표준 라이브러리는 날짜와 시간을 위한 자료형과 달력 관련 기능을 제공하는 자료형이 존재한다. datetime, time 그리고 calendar 모듈은 처음 공부하기에 좋은 주제다. datetime.datetime형이나 단순한 datetime이 널리 사용되고 있다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# matplotlib 한글 폰트 오류 문제 해결
from matplotlib import font_manager, rc
font_path = "./malgun.ttf" # 폰트 파일 위치
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
from datetime import datetime
now = datetime.now()
print(now)
print(now.year, now.month, now.day)
2022-09-22 19:21:36.159384 2022 9 22
datetime은 날짜와 시간을 모두 저장하며 마이크로초까지 지원한다. datetime.timedelta는 두 datetime 객체 간의 시간적인 차이를 표현할 수 있다.
delta = datetime(2011, 1, 7) - datetime(2008, 6, 24, 8, 15)
print(type(delta))
print(delta)
print(delta.days)
print(delta.seconds)
<class 'datetime.timedelta'> 926 days, 15:45:00 926 56700
timedelta를 더하거나 빼면 그만큼의 시간이 datetime 객체에 적용되어 새로운 객체를 만들 수 있다.
from datetime import timedelta
start = datetime(2011, 1, 7)
print(start + timedelta(12))
print(start - 2 * timedelta(12))
2011-01-19 00:00:00 2010-12-14 00:00:00
[표 11-1]에 datetime 모듈의 자료형을 정리해두었다. 이 장에서 주로 다루는 내용은 판다스의 자료형과 고수준의 시계열을 다루는 방법이며, 실제 파이썬을 사용하면서 다양한 곳에서 datetime 기반의 자료형을 마주치게 되리라는 점은 의심할 여지가 없다.
표 11-1 datetime 모듈의 자료형
| 자료형 | 설명 |
|---|---|
| date | 그레고리안 달력을 사용해서 날짜(연, 월, 일)를 저장한다. |
| time | 하루의 시간을 시, 분, 초, 마이크로초 단위로 저장한다. |
| datetime | 날짜와 시간을 저장한다. |
| timedelta | 두 datetime 값 간의 차이(일, 초, 마이크로초)를 표현한다. |
| tzinfo | 지역시간대를 저장하기 위한 기본 자료형 |
문자열을 datetime으로 변환하기
datetime 객체와 나중에 소개할 판다스의 Timestamp 객체는 str() 메서드나 strftime() 메서드에 포맷 규칙을 넘겨서 문자열로 나타낼 수 있다.
stamp = datetime(2011, 1, 3)
print(str(stamp))
print(stamp.strftime('%Y-%m-%d'))
2011-01-03 00:00:00 2011-01-03
[표 11-2]에 포맷 코드를 모두 정리해두었다.
표 11-2 Datetime 포맷 규칙(ISO C89 호환)
| 포맷 | 설명 |
|---|---|
| %Y | 4자리 연도 |
| %y | 2자리 연도 |
| %m | 2자리 월[01, 12] |
| %d | 2자리 일[01, 31] |
| %H | 시간(24시간 형식) [00, 23] |
| %I | 시간(12시간 형식) [01, 12] |
| %M | 2자리 분 [00, 59] |
| %S | 초 [00, 61] (60, 61은 윤초) |
| %w | 정수로 나타낸 요일 [0(일요일), 6] |
| %U | 연중 주차 [00, 53]. 일요일을 그 주의 첫 번째 날로 간주하며, 그 해에서 첫 번째 일요일 앞에 있는 날은 0주차가 된다. |
| %W | 연중 주차[00, 53]. 월요일을 그 주의 첫 번째 날로 간주하며, 그 해에서 첫 번째 월요일 앞에 있는 날은 0주차가 된다. |
| %z | UTC 시간대 오프셋을 +HHMM 또는 -HHMM으로 표현한다. 만약 시간대를 신경 쓰지 않는다면 비워둔다. |
| %F | %Y-%m-%d 형식에 대한 축약(예: 2012-4-18) |
| %D | %m/%d/%y 형식에 대한 축약(예: 04/18/12) |
이 포맷 코드는 datetime.strptime()을 사용해서 문자열을 날짜로 변환할 때 사용할 수 있다.
value = '2011-11-03'
print(datetime.strptime(value, '%Y-%m-%d'))
datestrs = ['7/6/2011', '8/6/2011']
print([datetime.strptime(x, '%m/%d/%Y') for x in datestrs])
2011-11-03 00:00:00 [datetime.datetime(2011, 7, 6, 0, 0), datetime.datetime(2011, 8, 6, 0, 0)]
datetime.strptime()은 알려진 형식의 날짜를 파싱하는 최적의 방법이다. 하지만 매번 포맷 규칙을 써야 하는 건 귀찮은 일이다. 특히 흔히 쓰는 날짜 형식에 대해서는 더 그렇다. 이 경우에는 서드파티 패키지인 dateutil에 포함된 parser.parse() 메서드를 사용하면 된다(판다스를 설치할 때 자동으로 함께 설치된다).
from dateutil.parser import parse
parse('2011-01-03')
datetime.datetime(2011, 1, 3, 0, 0)
dateutil은 거의 대부분의 사람이 인지하는 날짜 표현 방식을 파싱할 수 있다.
parse('Jan 31, 1997 10:45 PM')
datetime.datetime(1997, 1, 31, 22, 45)
국제 로케일의 경우 날짜가 월 앞에 오는 경우가 매우 흔하다. 이런 경우에는 dayfirst=True를 넘겨주면 된다.
parse('6/12/2011', dayfirst=True)
datetime.datetime(2011, 12, 6, 0, 0)
판다스는 일반적으로 데이터프레임의 칼럼이나 축 색인으로 날짜가 담긴 배열을 사용한다. to_datetime() 메서드는 많은 종류의 날짜 표현을 처리한다. ISO 8601 같은 표준 날짜 형식1은 매우 빠르게 처리할 수 있다.
datestrs = ['2011-07-06 12:00:00', '2011-08-06 00:00:00']
pd.to_datetime(datestrs)
DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='datetime64[ns]', freq=None)
또는 누락된 값(None, 빈 문자열 등)으로 간주되어야 할 값도 처리해준다.
idx = pd.to_datetime(datestrs + [None])
print(idx)
print(idx[2])
display(pd.isnull(idx))
DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dtype='datetime64[ns]', freq=None) NaT
array([False, False, True])
NaTNot a Time는 판다스에서 누락된 타임스탬프 데이터를 나타낸다.
CAUTION_ dateutil.parser()는 매우 유용하지만 완벽한 도구는 아니다. 날짜로 인식하지 않길 바라는 문자열을 날짜로 인식하기도 하는데, ‘42’를 2042년으로 해석하기도 한다.
datetime 객체는 여러 나라 혹은 언어에서 사용하는 로케일에 맞는 다양한 포맷 옵션을 제공한다. 예를 들어 독일과 프랑스에서는 각 월의 단축명이 영문 시스템과 다르다. [표 11-3]에서 로케일별 날짜 포맷을 확인하자.
표 11-3 로케일별 날짜 포맷
| 포맷 | 설명 |
|---|---|
| %a | 축약된 요일 이름 |
| %A | 요일 이름 |
| %b | 축약된 월 이름 |
| %B | 월 이름 |
| %c | 전체 날짜와 시간(예: 'Tue 01 May 2012 04:20:57 PM') |
| %p | 해당 로케일에서 AM, PM에 대응되는 이름(AM은 오전, OM은 오후) |
| %x | 로케일에 맞는 날짜 형식(예: 미국이라면 2012년 5월 1일은 '05/01/2012') |
| %X | 로케일에 맞는 시간 형식(예: '04:24:12 PM') |
시계열 기초
판다스에서 찾아볼 수 있는 가장 기본적인 시계열 객체의 종류는 파이썬 문자열이나 datetime 객체로 표현되는 타임스탬프로 색인된 시리즈다.
from datetime import datetime
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
datetime(2011, 1, 7), datetime(2011, 1, 8),
datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts = pd.Series(np.random.randn(6), index=dates)
ts
2011-01-02 1.837357 2011-01-05 -0.570545 2011-01-07 0.143702 2011-01-08 1.521649 2011-01-10 -0.757844 2011-01-12 -1.050700 dtype: float64
내부적으로 보면 이들 datetime 객체는 DatetimeIndex에 들어 있으며 ts 변수의 타입은 TimeSeries다.
ts.index
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)
다른 시리즈와 마찬가지로 서로 다르게 색인된 시계열 객체 간의 산술 연산은 자동으로 날짜에 맞춰진다.
ts + ts[::2]
2011-01-02 3.674714 2011-01-05 NaN 2011-01-07 0.287404 2011-01-08 NaN 2011-01-10 -1.515688 2011-01-12 NaN dtype: float64
ts[::2]는 ts에서 매 두번째 항목을 선택한다.
판다스는 NumPy의 datetime64 자료형을 사용해서 나노초의 정밀도를 가지는 타임스탬프를 저장한다.
ts.index.dtype
dtype('< M8[ns]')
DatetimeIndex의 스칼라값은 판다스의 Timestamp 객체다.
stamp = ts.index[0]
stamp
Timestamp('2011-01-02 00:00:00')
Timestamp는 datetime 객체를 사용하는 어떤 곳에도 대체 사용이 가능하다. 게다가 가능하다면 빈도에 관한 정보도 저장하며 시간대 변환을 하는 방법과 다른 종류의 조작을 하는 방법도 포함하고 있다. 자세한 내용은 차후에 다루도록 하겠다.
색인, 선택, 부분 선택
시계열은 라벨에 기반해서 데이터를 선택하고 인덱싱할 때 pandas.Series와 동일하게 동작한다.
stamp = ts.index[2]
ts[stamp]
0.14370208834611145
해석할 수 있는 날짜를 문자열로 넘겨서 편리하게 사용할 수 있다.
ts['1/10/2011']
-0.7578439635625243
ts['20110110']
-0.7578439635625243
긴 시계열에서는 연을 넘기거나 연, 월만 넘겨서 데이터의 일부 구간만 선택할 수도 있다.
longer_ts = pd.Series(np.random.randn(1000),
index=pd.date_range('1/1/2000', periods=1000))
longer_ts
2000-01-01 -1.672034
2000-01-02 -0.796216
2000-01-03 -1.936459
2000-01-04 0.380234
2000-01-05 -0.884594
...
2002-09-22 0.475738
2002-09-23 2.454114
2002-09-24 -0.075823
2002-09-25 2.177314
2002-09-26 2.736044
Freq: D, Length: 1000, dtype: float64
longer_ts['2001'] # 2001년도만 선택
2001-01-01 -0.261605
2001-01-02 -0.142300
2001-01-03 0.543364
2001-01-04 -0.078307
2001-01-05 0.001707
...
2001-12-27 0.033595
2001-12-28 0.250418
2001-12-29 -1.086145
2001-12-30 0.017903
2001-12-31 -0.055328
Freq: D, Length: 365, dtype: float64
여기서 문자열 ‘2001’은 연도로 해석되어 해당 기간의 데이터를 선택한다. 월에 대해서도 마찬가지로 선택할 수 있다.
longer_ts['2001-05']
2001-05-01 0.903758 2001-05-02 -1.774520 2001-05-03 -1.359049 2001-05-04 0.493027 2001-05-05 0.205103 2001-05-06 -1.974378 2001-05-07 -0.912620 2001-05-08 -1.280546 2001-05-09 0.177828 2001-05-10 1.245789 2001-05-11 -0.185303 2001-05-12 0.063704 2001-05-13 -1.091346 2001-05-14 -0.810181 2001-05-15 -0.023683 2001-05-16 0.649732 2001-05-17 1.955403 2001-05-18 -0.953458 2001-05-19 -1.759877 2001-05-20 0.090215 2001-05-21 -0.544426 2001-05-22 1.296436 2001-05-23 -0.160151 2001-05-24 -0.832809 2001-05-25 0.298448 2001-05-26 -0.662255 2001-05-27 -0.386180 2001-05-28 0.991174 2001-05-29 1.547604 2001-05-30 0.180879 2001-05-31 0.687581 Freq: D, dtype: float64
datetime 객체로 데이터를 잘라내는 작업은 일반적인 시리즈와 동일한 방식으로 할 수 있다.
ts[datetime(2011, 1, 7):]
2011-01-07 0.143702 2011-01-08 1.521649 2011-01-10 -0.757844 2011-01-12 -1.050700 dtype: float64
대부분의 시계열 데이터는 연대순으로 정렬되기 때문에 범위를 지정하기 위해 시계열에 포함하지 않고 타임스탬프를 이용해서 시리즈를 나눌 수 있다.
ts
2011-01-02 1.837357 2011-01-05 -0.570545 2011-01-07 0.143702 2011-01-08 1.521649 2011-01-10 -0.757844 2011-01-12 -1.050700 dtype: float64
ts['1/6/2011':'1/11/2011']
2011-01-07 0.143702 2011-01-08 1.521649 2011-01-10 -0.757844 dtype: float64
앞서와 같이 날짜 문자열이나 datetime 혹은 타임스탬프를 넘길 수 있다. 이런 방식으로 데이터를 나누면 NumPy 배열을 나누는 것처럼 원본 시계열에 대한 뷰를 생성한다는 사실을 기억하자. 즉, 데이터 복사가 발생하지 않고 슬라이스에 대한 변경이 원본 데이터에도 반영된다.
이와 동일한 인스턴스 메서드로 truncate()가 있는데, 이 메서드는 TimeSeries를 두 개의 날짜로 나눈다.
ts.truncate(after='1/9/2011')
2011-01-02 1.837357 2011-01-05 -0.570545 2011-01-07 0.143702 2011-01-08 1.521649 dtype: float64
ts.truncate(before='1/9/2011')
2011-01-10 -0.757844 2011-01-12 -1.050700 dtype: float64
위 방식은 데이터프레임에도 동일하게 적용되며 로우에 인덱싱된다.
dates = pd.date_range('1/1/2000', periods=100, freq='W-WED')
long_df = pd.DataFrame(np.random.randn(100, 4),
index=dates,
columns=['Colorado', 'Texas',
'New York', 'Ohio'])
long_df.loc['5-2001']
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2001-05-02 | -0.300120 | -0.583777 | -1.249877 | -1.806940 |
| 2001-05-09 | 0.458267 | 1.679471 | 1.606405 | 0.140018 |
| 2001-05-16 | 0.308655 | 1.853800 | -1.121390 | -0.845802 |
| 2001-05-23 | 1.014582 | 0.533721 | -1.243878 | -1.277454 |
| 2001-05-30 | -2.583704 | 1.408446 | -0.537218 | -1.434287 |
중복된 색인을 갖는 시계열
어떤 애플리케이션에서는 여러 데이터가 특정 타임스탬프에 몰려 있는 것을 발견할 수 있다.
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000',
'1/2/2000', '1/3/2000'])
dup_ts = pd.Series(np.arange(5), index=dates)
dup_ts
2000-01-01 0 2000-01-02 1 2000-01-02 2 2000-01-02 3 2000-01-03 4 dtype: int32
is_unique 속성을 통해 확인해보면 색인이 유일하지 않음을 알 수 있다.
dup_ts.index.is_unique
False
이 시계열 데이터를 인덱싱하면 타임스탬프의 중복 여부에 따라 스칼라값이나 슬라이스가 생성된다.
dup_ts['1/3/2000'] # 중복 없음
4
dup_ts['1/2/2000'] # 중복 있음
2000-01-02 1 2000-01-02 2 2000-01-02 3 dtype: int32
유일하지 않은 타임스탬프를 가지는 데이터를 집계한다고 해보자. 한 가지 방법은 groupby()에 level=0(단일 단계 인덱싱)을 넘기는 것이다.
grouped = dup_ts.groupby(level=0)
grouped.mean()
2000-01-01 0.0 2000-01-02 2.0 2000-01-03 4.0 dtype: float64
grouped.count()
2000-01-01 1 2000-01-02 3 2000-01-03 1 dtype: int64
날짜 범위, 빈도, 이동
판다스에서 일반적인 시계열은 불규칙적인 것으로 간주된다. 즉, 고정된 빈도를 갖지 않는다. 대부분의 애플리케이션에서 이는 충분하다. 하지만 시계열 안에서 누락된 값이 발생할지라도 일별, 월별 혹은 매 15분 같은 상대적인 고정 빈도에서의 작업이 요구되는 경우가 종종 있다. 다행스럽게도 판다스에는 리샘플링, 표준 시계열 빈도 모음, 빈도 추론 그리고 고정된 빈도의 날짜 범위를 위한 도구가 있다. 예를 들어 아래 예제 시계열을 고정된 일 빈도로 변환하려면 resample() 메서드를 사용하면 된다.
ts
2011-01-02 1.837357 2011-01-05 -0.570545 2011-01-07 0.143702 2011-01-08 1.521649 2011-01-10 -0.757844 2011-01-12 -1.050700 dtype: float64
resampler = ts.resample('D')
resampler
< pandas.core.resample.DatetimeIndexResampler object at 0x000001267188F9D0 >
문자열 ‘D’는 일 빈도로 해석된다.
빈도 간 변환이나 리샘플링은 큰 주제이므로 다음에 따로 다루도록 하겠다(1.6절 ‘리샘플링과 빈도 변환’). 여기에서는 기본 빈도와 다중 빈도를 어떻게 사용하는지 살펴보도록 하자.
날짜 범위 생성하기
앞에서는 설명 없이 그냥 사용했지만 pandas.date_range()를 사용하면 특정 빈도에 따라 지정한 길이만큼의 DatetimeIndex를 생성한다는 사실을 눈치 챘을 것이다.
index = pd.date_range('2012-04-01', '2012-06-01')
index
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20',
'2012-04-21', '2012-04-22', '2012-04-23', '2012-04-24',
'2012-04-25', '2012-04-26', '2012-04-27', '2012-04-28',
'2012-04-29', '2012-04-30', '2012-05-01', '2012-05-02',
'2012-05-03', '2012-05-04', '2012-05-05', '2012-05-06',
'2012-05-07', '2012-05-08', '2012-05-09', '2012-05-10',
'2012-05-11', '2012-05-12', '2012-05-13', '2012-05-14',
'2012-05-15', '2012-05-16', '2012-05-17', '2012-05-18',
'2012-05-19', '2012-05-20', '2012-05-21', '2012-05-22',
'2012-05-23', '2012-05-24', '2012-05-25', '2012-05-26',
'2012-05-27', '2012-05-28', '2012-05-29', '2012-05-30',
'2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
기본적으로 date_range()는 일별 타임스탬프를 생성한다. 만약 시작 날짜나 종료 날짜만 넘긴다면 생성할 기간의 숫자를 함께 전달해야 한다.
pd.date_range(start='2012-04-01', periods=20)
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20'],
dtype='datetime64[ns]', freq='D')
pd.date_range(end='2012-06-01', periods=20)
DatetimeIndex(['2012-05-13', '2012-05-14', '2012-05-15', '2012-05-16',
'2012-05-17', '2012-05-18', '2012-05-19', '2012-05-20',
'2012-05-21', '2012-05-22', '2012-05-23', '2012-05-24',
'2012-05-25', '2012-05-26', '2012-05-27', '2012-05-28',
'2012-05-29', '2012-05-30', '2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
시작과 종료 날짜는 생성된 날짜 색인에 대해 엄격한 경계를 정의한다. 예를 들어 날짜 색인이 각 월의 마지막 영업일을 포함하도록 하고 싶다면 빈도값으로 ‘BM’(월 영업마감일. [표 11-4]를 참조하자)을 전달할 것이다. 그러면 이 기간 안에 들어오는 날짜만 포함된다.
pd.date_range('2000-01-01', '2000-12-01', freq='BM')
DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-28',
'2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
'2000-09-29', '2000-10-31', '2000-11-30'],
dtype='datetime64[ns]', freq='BM')
표 11-4 기본 시계열 빈도
| 축약 | 오프셋 종류 | 설명 |
|---|---|---|
| D | Day | 달력상의 일 |
| B | BusinessDay | 매 영업일 |
| H | Hour | 매시 |
| T 또는 min | Minute | 매분 |
| S | Second | 매초 |
| L 또는 ms | Milli | 밀리초(1/1000초) |
| U | Micro | 마이크로초(1/1,000,000초) |
| M | MonthEnd | 월 마지막 일 |
| BM | BusinessMonthEnd | 월 영업마감일 |
| MS | MonthBegin | 월 시작일 |
| BMS | BusinessMonthBegin | 월 영업시작일 |
| W-MON, W-TUE, ... | Week | 요일. MON, TUE, WED, THU, FRI, SAT, SUN |
| WOM-1MON, WOM-2MON, ... | WeekOfMonth | 월별 주차와 요일. 예를 들어 WOM-3FRI는 매월 3째주 금요일이다. |
| Q-JAN, Q-FEB, ... | QuarterEnd | 지정된 월을 해당년도의 마감으로 하며 지정된 월의 마지막 날짜를 가리키는 분기 주기(JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC) |
| BQ-JAN, BQ-FEB, ... | BusinessQuarterEnd | 지정된 월을 해당년도의 마감으로 하며 지정된 월의 마지막 영업일을 가리키는 분기 주기 |
| QS-JAN, QS-FEB, ... | QuarterBegin | 지정된 월을 해당년도의 마감으로 하며 지정된 월의 첫째 날을 가리키는 분기 주기 |
| BQS-JAN, BQS-FEB, ... | BusinessQuarterBegin | 지정된 월을 해당년도의 마감으로 하며 지정된 월의 첫 번째 영업일을 가리키는 분기 주기 |
| A-JAN, A-FEB, ... | YearEnd | 주어진 월의 마지막 일을 가리키는 연간 주기(JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC) |
| BA-JAN, BA-FEB, ... | BusinessYearend | 주어진 월의 영업 마감일을 가리키는 연간 주기 |
| AS-JAN, AS-FEB, ... | YearBegin | 주어진 월의 시작일을 가리키는 연간 주기 |
| BAS-JAN, BAS-FEB, ... | BusinessYearBegin | 주어진 월의 영업 시작일을 가리키는 연간 주기 |
date_range()는 기본적으로 시작 시간이나 종료 시간의 타임스탬프(존재한다면)를 보존한다.
pd.date_range('2012-05-02 12:56:31', periods=5)
DatetimeIndex(['2012-05-02 12:56:31', '2012-05-03 12:56:31',
'2012-05-04 12:56:31', '2012-05-05 12:56:31',
'2012-05-06 12:56:31'],
dtype='datetime64[ns]', freq='D')
가끔은 시간 정보를 포함하여 시작 날짜와 종료 날짜를 갖고 있으나 관례에 따라 자정에 맞추어 타임스탬프를 정규화하고 싶을 때가 있다. 이렇게 하려면 normalize 옵션을 사용한다.
pd.date_range('20120502 12:56:31', periods=5, normalize=True)
DatetimeIndex(['2012-05-02', '2012-05-03', '2012-05-04', '2012-05-05',
'2012-05-06'],
dtype='datetime64[ns]', freq='D')
빈도와 날짜 오프셋
판다스에서 빈도는 기본 빈도base frequency와 배수의 조합으로 이루어진다. 기본 빈도는 보통 ‘M’(월별), ‘H’(시간별)처럼 짧은 문자열로 참조된다. 각 기본 빈도에는 일반적으로 날짜 오프셋data offset이라고 불리는 객체를 사용할 수 있다. 예를 들어 시간별 빈도는 Hour 클래스를 사용해서 표현할 수 있다.
from pandas.tseries.offsets import Hour, Minute
hour = Hour()
hour
< Hour >
이 오프셋의 곱은 정수를 넘겨서 구할 수 있다.
four_hours = Hour(4)
four_hours
< 4 * Hours >
대부분의 애플리케이션에서는 이런 객체들을 직접 만들어야 할 경우는 절대 없겠지만 대신 ‘H’ 또는 ‘4H’처럼 문자열로 표현하게 될 것이다. 기본 빈도 앞에 정수를 두면 해당 빈도의 곱을 생성한다.
pd.date_range('2000-01-01', '2000-01-03 23:59', freq='4h')
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 04:00:00',
'2000-01-01 08:00:00', '2000-01-01 12:00:00',
'2000-01-01 16:00:00', '2000-01-01 20:00:00',
'2000-01-02 00:00:00', '2000-01-02 04:00:00',
'2000-01-02 08:00:00', '2000-01-02 12:00:00',
'2000-01-02 16:00:00', '2000-01-02 20:00:00',
'2000-01-03 00:00:00', '2000-01-03 04:00:00',
'2000-01-03 08:00:00', '2000-01-03 12:00:00',
'2000-01-03 16:00:00', '2000-01-03 20:00:00'],
dtype='datetime64[ns]', freq='4H')
여러 오프셋을 덧셈으로 합칠 수 있다.
Hour(2) + Minute(30)
< 150 * Minutes >
유사하게 빈도 문자열로 ‘1h30min’을 넘겨도 같은 표현으로 잘 해석된다.
pd.date_range('2000-01-01', periods=10, freq='1h30min')
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 01:30:00',
'2000-01-01 03:00:00', '2000-01-01 04:30:00',
'2000-01-01 06:00:00', '2000-01-01 07:30:00',
'2000-01-01 09:00:00', '2000-01-01 10:30:00',
'2000-01-01 12:00:00', '2000-01-01 13:30:00'],
dtype='datetime64[ns]', freq='90T')
어떤 빈도는 시간상에서 균일하게 자리 잡고 있지 않은 경우도 있다. 예를 들어 ‘M’(월 마지막일)은 월중 일수에 의존적이며 ‘BM’(월 영업마감일)은 월말이 주말인지 아닌지에 따라 다르다. 이를 표현할 수 있는 적당한 용어가 없어서 이를 앵커드anchored 오프셋이라고 부른다.
[표 11-4]에 판다스에서 사용 가능한 빈도 코드와 날짜 오프셋 클래스를 정리해두었다.
NOTE_ 판다스에 없는 날짜 연산을 제공하기 위해 사용자가 직접 사용자 빈도 클래스를 정의할 수 있지만, 그 내용은 다루지 않는다.
월별 주차
한 가지 유용한 빈도 클래스는 WOM으로 시작하는 ‘월별 주차’다. 월별 주차를 사용하면 매월 3째주 금요일 같은 날짜를 얻을 수 있다.
rng = pd.date_range('2012-01-01', '2012-09-01', freq='WOM-3FRI')
list(rng)
[Timestamp('2012-01-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-02-17 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-03-16 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-04-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-05-18 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-06-15 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-07-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-08-17 00:00:00', freq='WOM-3FRI')]
데이터 시프트
시프트는 데이터를 시간 축에서 앞이나 뒤로 이동하는 것을 의미한다. 시리즈와 데이터프레임은 색인은 변경하지 않고 데이터를 앞이나 뒤로 느슨한 시프트를 수행하는 shift() 메서드를 가지고 있다.
ts = pd.Series(np.random.randn(4),
index=pd.date_range('1/1/2000', periods=4, freq='M'))
ts
2000-01-31 -0.119220 2000-02-29 -0.964139 2000-03-31 -0.841217 2000-04-30 -1.228765 Freq: M, dtype: float64
ts.shift(2)
2000-01-31 NaN 2000-02-29 NaN 2000-03-31 -0.119220 2000-04-30 -0.964139 Freq: M, dtype: float64
ts.shift(-2)
2000-01-31 -0.841217 2000-02-29 -1.228765 2000-03-31 NaN 2000-04-30 NaN Freq: M, dtype: float64
이렇게 시프트를 하게 되면 시계열의 시작이나 끝에 결측치가 발생하게 된다.
shift()는 일반적으로 한 시계열 내에서, 혹은 데이터프레임의 칼럼으로 표현할 수 있는 여러 시계열에서의 퍼센트 변화를 계산할 때 흔히 사용하며, 코드로는 다음과 같이 표현한다.
ts / ts.shift(1) - 1
2000-01-31 NaN 2000-02-29 7.087060 2000-03-31 -0.127494 2000-04-30 0.460700 Freq: M, dtype: float64
느슨한 시프트는 색인을 바꾸지 않기 때문에 어떤 데이터는 버려지기도 한다. 그래서 만약 빈도를 알고 있다면 shift()에 빈도를 넘겨서 타임스탬프가 확장되도록 할 수 있다.
ts.shift(2, freq='M')
2000-03-31 -0.119220 2000-04-30 -0.964139 2000-05-31 -0.841217 2000-06-30 -1.228765 Freq: M, dtype: float64
다른 빈도를 넘겨도 되는데, 이를 통해 아주 유연하게 데이터를 밀거나 당기는 작업을 할 수 있다.
ts.shift(3, freq='D')
2000-02-03 -0.119220 2000-03-03 -0.964139 2000-04-03 -0.841217 2000-05-03 -1.228765 dtype: float64
ts.shift(1, freq='90T')
2000-01-31 01:30:00 -0.119220 2000-02-29 01:30:00 -0.964139 2000-03-31 01:30:00 -0.841217 2000-04-30 01:30:00 -1.228765 dtype: float64
여기서 T는 분을 나타낸다.
오프셋만큼 날짜 시프트하기
판다스의 날짜 오프셋은 datetime이나 Timestamp 객체에서도 사용할 수 있다.
from pandas.tseries.offsets import Day, MonthEnd
now = datetime(2011, 11, 17)
now + 3 * Day()
Timestamp('2011-11-20 00:00:00')
만일 MonthEnd 같은 앵커드 오프셋을 추가한다면 빈도 규칙의 다음 날짜로 롤 포워드roll forward된다.
now + MonthEnd() # 2011년 11월 30일의 마지막 일인 30일로 계산
Timestamp('2011-11-30 00:00:00')
now + MonthEnd(2) # 2011년 12월 31일의 마지막 일인 31일로 계산
Timestamp('2011-12-31 00:00:00')
앵커드 오프셋은 rollforward()와 rollback() 메서드를 사용해서 명시적으로 각각 날짜를 앞으로 밀거나 뒤로 당길 수 있다.
offset = MonthEnd()
display(offset.rollforward(now))
display(offset.rollback(now))
Timestamp('2011-11-30 00:00:00')
Timestamp('2011-10-31 00:00:00')
이 메서드를 groupby()와 함께 사용하면 날짜 오프셋을 영리하게 사용할 수 있다.
ts = pd.Series(np.random.randn(20),
index=pd.date_range('1/15/2000', periods=20, freq='4d'))
ts
2000-01-15 1.094205 2000-01-19 -1.202014 2000-01-23 -0.559123 2000-01-27 0.027047 2000-01-31 -1.338278 2000-02-04 0.346270 2000-02-08 -0.809914 2000-02-12 -0.918544 2000-02-16 0.092567 2000-02-20 -1.446279 2000-02-24 0.948425 2000-02-28 0.356178 2000-03-03 0.742059 2000-03-07 -0.258679 2000-03-11 -0.050388 2000-03-15 -1.602979 2000-03-19 -0.033493 2000-03-23 0.131544 2000-03-27 0.103924 2000-03-31 0.404923 Freq: 4D, dtype: float64
ts.groupby(offset.rollforward).mean()
2000-01-31 -0.395633 2000-02-29 -0.204471 2000-03-31 -0.070386 dtype: float64
물론 가장 쉽고 빠른 방법은 resample()을 사용하는 것이다(자세한 내용은 1.6절 ‘리샘플링과 빈도 변환’에서 다루도록 하겠다).
ts.resample('M').mean()
2000-01-31 -0.395633 2000-02-29 -0.204471 2000-03-31 -0.070386 Freq: M, dtype: float64
시간대 다루기
시간대를 처리하는 일은 시계열을 다루는 작업 중에서 가장 유쾌하지 않은 부분 중 하나다. 특히 일광절약시간(DST, 서머타임)은 문제를 일으키는 흔한 요인 중 하나다. 시계열을 다루는 많은 사용자는 현재 국제표준이며 그리니치 표준시를 계승하는 국제표준시coordinated universal time, UTC를 선택한다. 시간대는 UTC로부터 떨어진 오프셋으로 표현되는데 예를 들면 뉴욕은 일광절약시간daylight saving time, DST일 때 UTC보다 4시간 늦으며 아닐 때는 5시간 늦다.
파이썬에서 시간대 정보는 전 세계의 시간대 정보를 모아둔 올슨 데이터베이스를 담고 있는 서드파티 라이브러리인 pytz에서 얻어온다. 이는 특히 역사적인 데이터를 다룰 때 중요한데 DST 날짜(그리고 심지어는 UTC 오프셋마저)는 지역 정부의 변덕에 따라 여러 차례 변경되었기 때문이다. 미국에서는 1900년부터 DST 시간이 수차례 변경되었다!
pytz 라이브러리에 대한 자세한 내용은 라이브러리의 문서를 살펴보기 바란다. 판다스는 pytz의 기능을 사용하고 있으므로 시간대 이름 외에 API의 다른 부분은 무시해도 상관없다. 시간대 이름은 문서와 파이썬 셸에서 직접 확인할 수 있다.
import pytz
pytz.common_timezones[-5:]
['US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
pytz에서 시간대 객체를 얻으려면 pytz.timezone()을 사용하면 된다.
tz = pytz.timezone('America/New_York')
tz
< DstTzInfo 'America/New_York' LMT-1 day, 19:04:00 STD >
판다스의 메서드에서는 시간대 이름이나 객체를 모두 사용할 수 있지만 시간대 이름을 사용하기 권장한다.
시간대 지역화와 변환
기본적으로 판다스에서 시계열은 시간대를 엄격히 다루지 않는다. 다음 시계열을 살펴보자.
rng = pd.date_range('3/9/2012', periods=6, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2012-03-09 -0.930082 2012-03-10 1.021578 2012-03-11 0.217027 2012-03-12 2.874362 2012-03-13 -0.456855 2012-03-14 -0.208952 Freq: D, dtype: float64
색인의 tz 필드는 None이다.
print(ts.index.tz)
None
시간대를 지정해서 날짜 범위를 생성할 수 있다.
pd.date_range('3/9/2012 9:30', periods=10, freq='D', tz='UTC')
DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
'2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00', '2012-03-16 09:30:00+00:00',
'2012-03-17 09:30:00+00:00', '2012-03-18 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
지역화 시간으로의 변환은 tz_localize() 메서드로 처리할 수 있다.
ts
2012-03-09 -0.930082 2012-03-10 1.021578 2012-03-11 0.217027 2012-03-12 2.874362 2012-03-13 -0.456855 2012-03-14 -0.208952 Freq: D, dtype: float64
ts_utc = ts.tz_localize('UTC')
ts_utc
2012-03-09 00:00:00+00:00 -0.930082 2012-03-10 00:00:00+00:00 1.021578 2012-03-11 00:00:00+00:00 0.217027 2012-03-12 00:00:00+00:00 2.874362 2012-03-13 00:00:00+00:00 -0.456855 2012-03-14 00:00:00+00:00 -0.208952 Freq: D, dtype: float64
ts_utc.index
DatetimeIndex(['2012-03-09 00:00:00+00:00', '2012-03-10 00:00:00+00:00',
'2012-03-11 00:00:00+00:00', '2012-03-12 00:00:00+00:00',
'2012-03-13 00:00:00+00:00', '2012-03-14 00:00:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
시계열이 특정 시간대로 지역화되고 나면 tz_convert()를 이용해서 다른 시간대로 변환 가능하다.
ts_utc.tz_convert('America/New_York')
2012-03-08 19:00:00-05:00 -0.930082 2012-03-09 19:00:00-05:00 1.021578 2012-03-10 19:00:00-05:00 0.217027 2012-03-11 20:00:00-04:00 2.874362 2012-03-12 20:00:00-04:00 -0.456855 2012-03-13 20:00:00-04:00 -0.208952 Freq: D, dtype: float64
위 시계열의 경우에는 America/New_York 시간대에서 일광절약시간을 사용하고 있는데, 동부 표준시(EST)로 맞춘 다음 UTC 혹은 베를린 시간으로 변환할 수 있다.
ts_eastern = ts.tz_localize('America/New_York')
ts_eastern.tz_convert('UTC')
2012-03-09 05:00:00+00:00 -0.930082 2012-03-10 05:00:00+00:00 1.021578 2012-03-11 05:00:00+00:00 0.217027 2012-03-12 04:00:00+00:00 2.874362 2012-03-13 04:00:00+00:00 -0.456855 2012-03-14 04:00:00+00:00 -0.208952 dtype: float64
ts_eastern.tz_convert('Europe/Berlin')
2012-03-09 06:00:00+01:00 -0.930082 2012-03-10 06:00:00+01:00 1.021578 2012-03-11 06:00:00+01:00 0.217027 2012-03-12 05:00:00+01:00 2.874362 2012-03-13 05:00:00+01:00 -0.456855 2012-03-14 05:00:00+01:00 -0.208952 dtype: float64
tz_localize()와 tz_convert()는 모두 DatetimeIndex의 인스턴스 메서드다.
ts.index.tz_localize('Asia/Shanghai')
DatetimeIndex(['2012-03-09 00:00:00+08:00', '2012-03-10 00:00:00+08:00',
'2012-03-11 00:00:00+08:00', '2012-03-12 00:00:00+08:00',
'2012-03-13 00:00:00+08:00', '2012-03-14 00:00:00+08:00'],
dtype='datetime64[ns, Asia/Shanghai]', freq=None)
CAUTION_ 타임스탬프를 특정 시간대로 지역화하면 일광절약시간에 의한 모호하거나 존재하지 않는 시간을 체크한다.
시간대를 고려해서 Timestamp 객체 다루기
시계열이나 날짜 범위와 비슷하게 개별 Timestamp 객체도 시간대를 고려한 형태로 변환이 가능하다.
stamp = pd.Timestamp('2011-03-12 04:00')
stamp_utc = stamp.tz_localize('utc')
stamp_utc.tz_convert('America/New_York')
Timestamp('2011-03-11 23:00:00-0500', tz='America/New_York')
Timestamp 객체를 생성할 때 시간대를 직접 넘겨주는 것도 가능하다.
stamp_moscow = pd.Timestamp('2011-03-12 04:00', tz='Europe/Moscow')
stamp_moscow
Timestamp('2011-03-12 04:00:00+0300', tz='Europe/Moscow')
시간대를 고려한 Timestamp 객체는 내부적으로 UTC 타임스탬프 값을 유닉스 에포크Unix epoch(1970년 1월 1일)부터 현재까지의 나노초로 저장하고 있다. 이 UTC 값은 시간대 변환 과정에서 변하지 않고 유지된다.
stamp_utc.value
1299902400000000000
stamp_utc.tz_convert('America/New_York').value
1299902400000000000
판다스의 DateOffset 객체를 이용해서 시간 연산을 수행할 때는 가능하다면 일광절약시간을 고려한다. DST로 전환되기 직전의 타임스탬프에 대한 예제를 살펴보자. 먼저 DST 시행 30분 전의 Timestamp를 생성하자.
from pandas.tseries.offsets import Hour
stamp = pd.Timestamp('2012-03-12 01:30', tz='US/Eastern')
display(stamp)
display(stamp + Hour())
Timestamp('2012-03-12 01:30:00-0400', tz='US/Eastern')
Timestamp('2012-03-12 02:30:00-0400', tz='US/Eastern')
그리고 DST 시행 90분 전의 Timestamp를 생성하자.
stamp = pd.Timestamp('2012-11-04 00:30', tz='US/Eastern')
display(stamp)
display(stamp + 2 * Hour())
Timestamp('2012-11-04 00:30:00-0400', tz='US/Eastern')
Timestamp('2012-11-04 01:30:00-0500', tz='US/Eastern')
다른 시간대 간의 연산
서로 다른 시간대를 갖는 두 시계열이 하나로 합쳐지면 결과는 UTC가 된다. 타임스탬프는 내부적으로 UTC로 저장되므로 추가적인 변환이 불필요한 명료한 연산이다.
rng = pd.date_range('3/7/2012 9:30', periods=10, freq='B')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2012-03-07 09:30:00 -1.308538 2012-03-08 09:30:00 1.197042 2012-03-09 09:30:00 1.458178 2012-03-12 09:30:00 0.803862 2012-03-13 09:30:00 0.211448 2012-03-14 09:30:00 -1.515341 2012-03-15 09:30:00 0.283447 2012-03-16 09:30:00 -0.347251 2012-03-19 09:30:00 1.073246 2012-03-20 09:30:00 1.637415 Freq: B, dtype: float64
ts1 = ts[:7].tz_localize('Europe/London')
ts2 = ts1[2:].tz_convert('Europe/Moscow')
result = ts1 + ts2
result.index
DatetimeIndex(['2012-03-07 09:30:00+00:00', '2012-03-08 09:30:00+00:00',
'2012-03-09 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq=None)
기간과 기간 연산
며칠, 몇 개월, 몇 분기, 몇 해 같은 기간은 Period 클래스로 표현할 수 있으며 문자열이나 정수 그리고 [표 11-4]에서 봤던 빈도를 가지고 생성한다.
p = pd.Period(2007, freq='A-DEC')
p
Period('2007', 'A-DEC')
여기서 Period 객체는 2007년 1월 1일부터 같은 해 12월 31일까지의 기간을 표현한다. 이 기간에 정수를 더하거나 빼서 편리하게 정해진 빈도에 따라 기간을 이동시킬 수 있다.
p + 5
Period('2012', 'A-DEC')
p - 2
Period('2005', 'A-DEC')
만약 두 기간이 같은 빈도를 가진다면 두 기간의 차는 둘 사이의 간격이 된다.
pd.Period('2014', freq='A-DEC') - p
< 7 * YearEnds: month=12 >
일반적인 기간 범위는 period_range() 함수로 생성할 수 있다.
rng = pd.period_range('2000-01-01', '2000-06-30', freq='M')
rng
PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '2000-06'], dtype='period[M]')
PeriodIndex 클래스는 순차적인 기간을 저장하며 다른 판다스 자료구조에서 축 색인과 마찬가지로 사용된다.
pd.Series(np.random.randn(6), index=rng)
2000-01 -0.354458 2000-02 -0.806875 2000-03 -0.224806 2000-04 -1.545974 2000-05 -0.367937 2000-06 -0.483932 Freq: M, dtype: float64
다음과 같은 문자열 배열을 이용해서 PeriodIndex 클래스를 생성하는 것도 가능하다.
values = ['2001Q3', '2002Q2', '2003Q1']
index = pd.PeriodIndex(values, freq='Q-DEC')
index
PeriodIndex(['2001Q3', '2002Q2', '2003Q1'], dtype='period[Q-DEC]')
Period의 빈도 변환
기간과 PeriodIndex 객체는 asfreq() 메서드를 통해 다른 빈도로 변환할 수 있다. 예를 들어 새해 첫날부터 시작하는 연간 빈도를 월간 빈도로 변환해보자. 꽤 간단하게 변환할 수 있다.
p = pd.Period('2007', freq='A-DEC')
p
Period('2007', 'A-DEC')
p.asfreq('M', how='start')
Period('2007-01', 'M')
p.asfreq('M', how='end')
Period('2007-12', 'M')
Period(‘2007’, ‘A-DEC’)는 전체 기간에 대한 커서로 생각할 수 있고 월간으로 다시 나눌 수 있다. 이 내용은 [그림 11-1]을 참조하자. 회계연도 마감이 12월이 아닌 경우에는 월간 빈도가 달라진다.
p = pd.Period('2007', freq='A-JUN')
p
Period('2007', 'A-JUN')
p.asfreq('M', 'start')
Period('2006-07', 'M')
p.asfreq('M', 'end')
Period('2007-06', 'M')
그림 11-1 Period의 빈도 변환
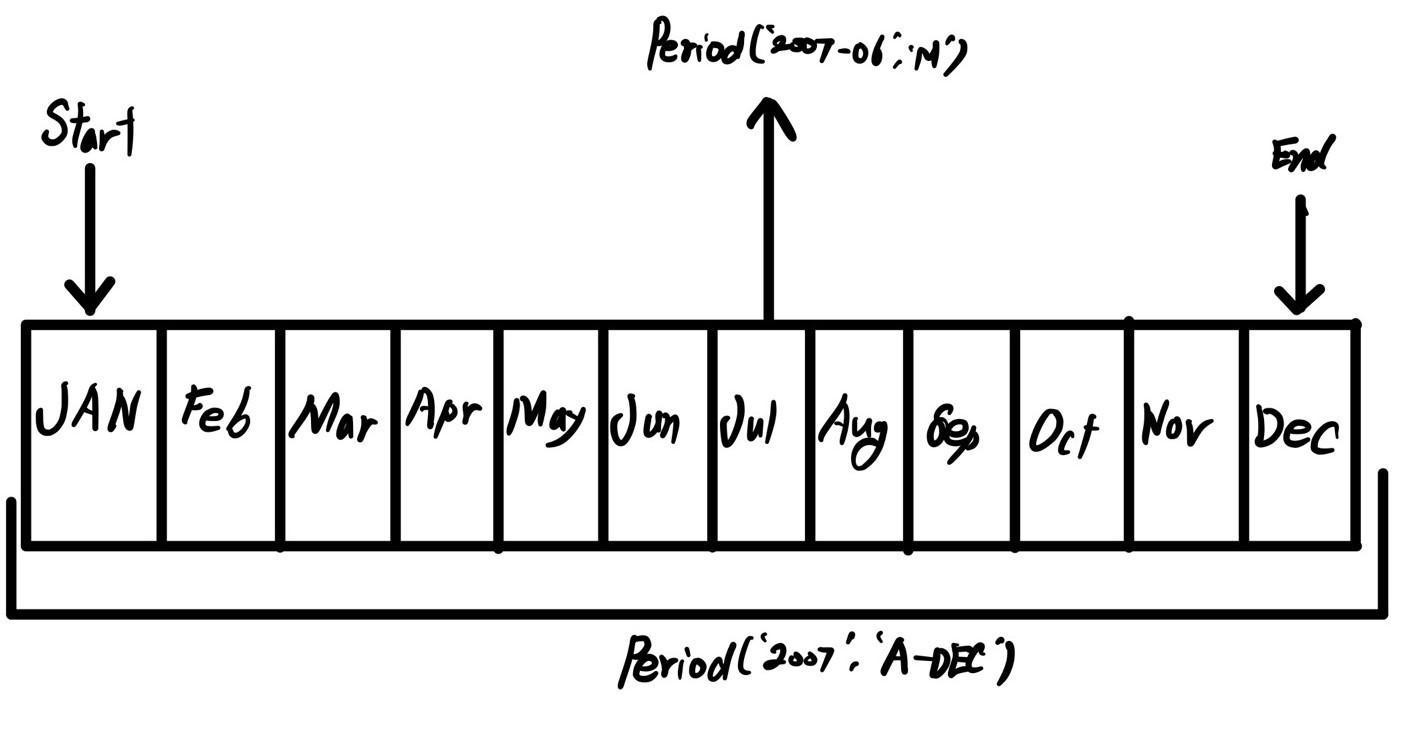
빈도가 상위 단계에서 하위 단계로 변환되는 경우 상위 기간은 하위 기간이 어디에 속했는지에 따라 결정된다. 예를 들어 A-JUN 빈도일 경우 2007년 8월은 실제로 2008년 기간에 속하게 된다.
p = pd.Period('Aug-2007', 'M')
p.asfreq('A-JUN')
Period('2008', 'A-JUN')
모든 PeriodIndex 객체나 시계열은 지금까지 살펴본 내용과 같은 방식으로 변환할 수 있다.
rng = pd.period_range('2006', '2009', freq='A-DEC')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2006 0.450451 2007 -0.158898 2008 -0.601238 2009 1.016451 Freq: A-DEC, dtype: float64
ts.asfreq('M', how='start')
2006-01 0.450451 2007-01 -0.158898 2008-01 -0.601238 2009-01 1.016451 Freq: M, dtype: float64
위 예제에서 연 빈도는 해당 빈도의 시작 월부터 시작하는 월 빈도로 치환된다. 만일 매 해의 마지막 영업일을 대신 사용하고 싶다면 ‘B’ 빈도를 사용하고 해당 기간의 종료 지점을 지정해서 변환할 수 있다.
ts.asfreq('B', how='end')
2006-12-29 0.450451 2007-12-31 -0.158898 2008-12-31 -0.601238 2009-12-31 1.016451 Freq: B, dtype: float64
분기 빈도
분기 데이터는 재정, 금융 및 다른 분야에서 표준으로 사용된다. 많은 분기 데이터는 일반적으로 회계연도의 끝인 12월의 마지막 날이나 마지막 업무일을 기준으로 보고하는데, 2012Q4는 회계연도의 끝이 어딘가에 따라 의미가 달라진다. 판다스는 12가지 모든 경우의 수를 지원하며 분기 빈도는 Q-JAN부터 Q-DEC까지다.
p = pd.Period('2012Q4', freq='Q-JAN')
p
Period('2012Q4', 'Q-JAN')
회계연도 마감이 1월인 경우라면 2012Q4는 11월부터 1월까지가 되고 일간 빈도로 검사할 수 있다. [그림 11-2]를 살펴보자.
그림 11-2 다양한 분기 빈도 변환

p.asfreq('D', 'start')
Period('2011-11-01', 'D')
p.asfreq('D', 'end')
Period('2012-01-31', 'D')
이렇게 하여 기간 연산을 매우 쉽게 할 수 있는데, 그 예로 분기 영업마감일의 오후 4시를 가리키는 타임스탬프는 다음과 같이 구할 수 있다.
p4pm = (p.asfreq('B', 'end') - 1).asfreq('T', 'start') + 16 * 60
p4pm
Period('2012-01-30 16:00', 'T')
p4pm.to_timestamp()
Timestamp('2012-01-30 16:00:00')
period_range()를 사용해서 분기 범위를 생성할 수 있다. 연산 역시 동일한 방법으로 수행할 수 있다.
rng = pd.period_range('2011Q3', '2012Q4', freq='Q-JAN')
ts = pd.Series(np.arange(len(rng)), index=rng)
ts
2011Q3 0 2011Q4 1 2012Q1 2 2012Q2 3 2012Q3 4 2012Q4 5 Freq: Q-JAN, dtype: int32
new_rng = (rng.asfreq('B', 'end') - 1).asfreq('T', 'start') + 16 * 60
ts.index = new_rng.to_timestamp()
ts
2010-10-28 16:00:00 0 2011-01-28 16:00:00 1 2011-04-28 16:00:00 2 2011-07-28 16:00:00 3 2011-10-28 16:00:00 4 2012-01-30 16:00:00 5 dtype: int32
타임스탬프와 기간 서로 변환하기
타임스탬프로 색인된 시리즈와 데이터프레임 객체는 to_period() 메서드를 사용해서 기간period으로 변환 가능하다.
rng = pd.date_range('2000-01-01', periods=3, freq='M')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
print(ts.index)
display(ts)
DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31'], dtype='datetime64[ns]', freq='M')
2000-01-31 -0.313735 2000-02-29 -0.559284 2000-03-31 -0.721773 Freq: M, dtype: float64
pts = ts.to_period()
print(pts.index)
display(pts)
PeriodIndex(['2000-01', '2000-02', '2000-03'], dtype='period[M]')
2000-01 -0.313735 2000-02 -0.559284 2000-03 -0.721773 Freq: M, dtype: float64
여기서 말하는 기간은 겹치지 않는 시간상의 간격을 뜻하므로 주어진 빈도에서 타임스탬프는 하나의 기간에만 속한다. 새로운 PeriodIndex의 빈도는 기본적으로 타임스탬프 값을 통해 추론되지만 원하는 빈도를 직접 지정할 수 있다. 결과에 중복되는 기간이 나오더라도 문제가 되지 않는다.
rng = pd.date_range('1/29/2000', periods=6, freq='D')
ts2 = pd.Series(np.random.randn(6), index=rng)
ts2
2000-01-29 1.394735 2000-01-30 -1.461393 2000-01-31 0.467966 2000-02-01 -0.153626 2000-02-02 0.689731 2000-02-03 -0.241881 Freq: D, dtype: float64
ts2.to_period('M')
2000-01 1.394735 2000-01 -1.461393 2000-01 0.467966 2000-02 -0.153626 2000-02 0.689731 2000-02 -0.241881 Freq: M, dtype: float64
기간을 타임스탬프로 변환하려면 to_timestamp() 메서드를 이용하면 된다.
pts = ts2.to_period()
pts
2000-01-29 1.394735 2000-01-30 -1.461393 2000-01-31 0.467966 2000-02-01 -0.153626 2000-02-02 0.689731 2000-02-03 -0.241881 Freq: D, dtype: float64
pts.to_timestamp(how='end')
2000-01-29 23:59:59.999999999 1.394735 2000-01-30 23:59:59.999999999 -1.461393 2000-01-31 23:59:59.999999999 0.467966 2000-02-01 23:59:59.999999999 -0.153626 2000-02-02 23:59:59.999999999 0.689731 2000-02-03 23:59:59.999999999 -0.241881 Freq: D, dtype: float64
배열로 PeriodIndex 생성하기
고정된 빈도를 갖는 데이터는 종종 여러 칼럼에 걸쳐 기간에 대한 정보를 함께 저장하기도 한다. 예를 들어 다음 거시경제학(매크로경제학macroeconomic) 데이터셋에는 연도와 분기가 구분된 칼럼에 존재한다.
data = pd.read_csv('examples/macrodata.csv')
data.head(5)
| year | quarter | realgdp | realcons | realinv | realgovt | realdpi | cpi | m1 | tbilrate | unemp | pop | infl | realint | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1959.0 | 1.0 | 2710.349 | 1707.4 | 286.898 | 470.045 | 1886.9 | 28.98 | 139.7 | 2.82 | 5.8 | 177.146 | 0.00 | 0.00 |
| 1 | 1959.0 | 2.0 | 2778.801 | 1733.7 | 310.859 | 481.301 | 1919.7 | 29.15 | 141.7 | 3.08 | 5.1 | 177.830 | 2.34 | 0.74 |
| 2 | 1959.0 | 3.0 | 2775.488 | 1751.8 | 289.226 | 491.260 | 1916.4 | 29.35 | 140.5 | 3.82 | 5.3 | 178.657 | 2.74 | 1.09 |
| 3 | 1959.0 | 4.0 | 2785.204 | 1753.7 | 299.356 | 484.052 | 1931.3 | 29.37 | 140.0 | 4.33 | 5.6 | 179.386 | 0.27 | 4.06 |
| 4 | 1960.0 | 1.0 | 2847.699 | 1770.5 | 331.722 | 462.199 | 1955.5 | 29.54 | 139.6 | 3.50 | 5.2 | 180.007 | 2.31 | 1.19 |
data.year
0 1959.0
1 1959.0
2 1959.0
3 1959.0
4 1960.0
...
198 2008.0
199 2008.0
200 2009.0
201 2009.0
202 2009.0
Name: year, Length: 203, dtype: float64
data.quarter
0 1.0
1 2.0
2 3.0
3 4.0
4 1.0
...
198 3.0
199 4.0
200 1.0
201 2.0
202 3.0
Name: quarter, Length: 203, dtype: float64
이 배열을 PeriodIndex()에 빈도값과 함께 전달하면 이를 조합해서 데이터프레임에서 사용할 수 있는 색인을 만들어낸다.
index = pd.PeriodIndex(year=data.year, quarter=data.quarter,
freq='Q-DEC')
index
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203)
data.index = index
data.infl
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
...
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, Length: 203, dtype: float64
리샘플링과 빈도 변환
리샘플링은 시계열의 빈도를 변환하는 과정을 일컫는다. 상위 빈도의 데이터를 하위 빈도로 집계하는 것을 다운샘플링이라고 하며 반대 과정을 업샘플링이라고 한다. 모든 리샘플링이 두 가지 범주에 들어가지는 않는다. 예를 들어 W-WED(수요일을 기준으로 한 주간)를 W-FRI(금요일을 기준으로 한 주간)로 변경하는 것은 업샘플링도 다운샘플링도 아니다.
판다스 객체는 resample() 메서드를 가지고 있는데, 빈도 변환과 관련된 모든 작업에서 유용하게 사용되는 메서드다. resample()은 groupby()와 비슷한 API를 가지고 있는데 resample()을 호출해서 데이터를 그룹 짓고 요약함수를 적용하는 식이다.
rng = pd.date_range('2000-01-01', periods=100, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2000-01-01 -0.819040
2000-01-02 0.263496
2000-01-03 1.149621
2000-01-04 -0.106353
2000-01-05 0.012251
...
2000-04-05 -2.041302
2000-04-06 0.987651
2000-04-07 -1.799061
2000-04-08 0.041890
2000-04-09 -0.256195
Freq: D, Length: 100, dtype: float64
ts.resample('M').mean()
2000-01-31 -0.129325 2000-02-29 0.201535 2000-03-31 0.151715 2000-04-30 -0.447242 Freq: M, dtype: float64
ts.resample('M', kind='period').mean()
2000-01 -0.129325 2000-02 0.201535 2000-03 0.151715 2000-04 -0.447242 Freq: M, dtype: float64
resample()은 유연한 고수준의 메서드로, 매우 큰 시계열 데이터를 처리할 수 있다. 다음 절부터 몇 가지 예제를 통해 자세한 내용을 살펴보자. [표 11-5]에 resample() 메서드의 인자 일부를 설명했다.
표 11-5 resample 메서드 인자
| 인자 | 설명 |
|---|---|
| freq | 원하는 리샘플링 빈도를 가리키는 문자열이나 DateOffset(예: 'M', '5min', Second(15)) |
| axis | 리샘플링을 수행할 축. 기본값은 axis=0이다. |
| fill_method | 업샘플링 시 사용할 보간 방법. 'ffill'과 'bfill'이 있다. 기본값은 None이다(보간을 수행하지 않음). |
| closed | 다운샘플링 시 각 간격의 어느 쪽을 포함할지 가리킨다. 'right'와 'left'가 있고 기본값은 'left'다. |
| label | 다운샘플링 시 집계된 결과의 라벨을 결정한다. 'right'와 'left'가 있다. 예를 들어 9:30에서 9:35까지 5분 간격이 있을 때 라벨은 9:30 혹은 9:35가 될 수 있다. 기본값은 'left'다(이 경우에는 9:30가 된다). |
| loffset | 나뉜 그룹의 라벨에 맞추기 위한 오프셋. '-1s' /Second(-1)은 집계된 라벨을 1초 앞당긴다. |
| limit | 보간법을 사용할 때 보간을 적용할 최대 기간 |
| kind | 기간('period')별 혹은 타임스탬프('timestamp')별로 집계할 것인지 구분. 기본값은 시계열 색인의 종류와 같다. |
| convention | 기간을 리샘플링할 때 하위 빈도 기간에서 상위 빈도로 변환 시의 방식('start' 혹은 'end'). 기본값은 'end'다. |
다운샘플링
시계열 데이터를 규칙적인 하위 빈도로 집계하는 일은 특별한 일이 아니다. 집계할 데이터는 고정 빈도를 가질 필요가 없으며 잘라낸 시계열 조각의 크기를 원하는 빈도로 정의한다. 예를 들어 ‘M’이나 ‘BM’ 같은 월간 빈도로 변환하려면 데이터를 월 간격으로 나눠야 한다. 각 간격은 한쪽이 열려 있게 되는데, 이 말은 하나의 간격에서 양끝 중 한쪽만 포함된다는 뜻이다. 그러면 각 간격의 모음이 전체 시계열이 된다. resampel()을 사용해서 데이터를 다운샘플링할 때 고려해야 할 사항이 몇 가지 있다.
-
각 간격의 양끝 중에서 어느 쪽을 닫아둘 것인가
-
집계하려는 구간의 라벨을 간격의 시작으로 할지 끝으로 할지 여부
분 단위 데이터를 통해 좀 더 알아보자.
rng = pd.date_range('2000-01-01', periods=12, freq='T')
ts = pd.Series(np.arange(12), index=rng)
ts
2000-01-01 00:00:00 0 2000-01-01 00:01:00 1 2000-01-01 00:02:00 2 2000-01-01 00:03:00 3 2000-01-01 00:04:00 4 2000-01-01 00:05:00 5 2000-01-01 00:06:00 6 2000-01-01 00:07:00 7 2000-01-01 00:08:00 8 2000-01-01 00:09:00 9 2000-01-01 00:10:00 10 2000-01-01 00:11:00 11 Freq: T, dtype: int32
이 데이터를 5분 단위로 묶어서 각 그룹의 합을 집계해보자.
for t, v in ts.resample('5min', closed='left'):
display(t, v)
Timestamp('2000-01-01 00:00:00', freq='5T')
2000-01-01 00:00:00 0 2000-01-01 00:01:00 1 2000-01-01 00:02:00 2 2000-01-01 00:03:00 3 2000-01-01 00:04:00 4 Freq: T, dtype: int32
Timestamp('2000-01-01 00:05:00', freq='5T')
2000-01-01 00:05:00 5 2000-01-01 00:06:00 6 2000-01-01 00:07:00 7 2000-01-01 00:08:00 8 2000-01-01 00:09:00 9 Freq: T, dtype: int32
Timestamp('2000-01-01 00:10:00', freq='5T')
2000-01-01 00:10:00 10 2000-01-01 00:11:00 11 Freq: T, dtype: int32
ts.resample('5min', closed='left').sum()
2000-01-01 00:00:00 10 2000-01-01 00:05:00 35 2000-01-01 00:10:00 21 Freq: 5T, dtype: int32
인자로 넘긴 빈도는 5분 단위로 증가하는 그룹의 경계를 정의한다. 기본적으로 시작값을 그룹의 왼쪽에 포함시키므로 00:00의 값은 첫 번째 그룹의 00:00부터 00:05까지의 값을 집계한다.2 closed=’right’를 넘기면 시작값을 그룹의 오른쪽에 포함시킨다.
for t, v in ts.resample('5min', closed='right'):
display(t, v)
Timestamp('1999-12-31 23:55:00', freq='5T')
2000-01-01 0 Freq: T, dtype: int32
Timestamp('2000-01-01 00:00:00', freq='5T')
2000-01-01 00:01:00 1 2000-01-01 00:02:00 2 2000-01-01 00:03:00 3 2000-01-01 00:04:00 4 2000-01-01 00:05:00 5 Freq: T, dtype: int32
Timestamp('2000-01-01 00:05:00', freq='5T')
2000-01-01 00:06:00 6 2000-01-01 00:07:00 7 2000-01-01 00:08:00 8 2000-01-01 00:09:00 9 2000-01-01 00:10:00 10 Freq: T, dtype: int32
Timestamp('2000-01-01 00:10:00', freq='5T')
2000-01-01 00:11:00 11 Freq: T, dtype: int32
ts.resample('5min', closed='right').sum()
1999-12-31 23:55:00 0 2000-01-01 00:00:00 15 2000-01-01 00:05:00 40 2000-01-01 00:10:00 11 Freq: 5T, dtype: int32
결과로 반환된 시계열은 각 그룹의 왼쪽 타임스탬프가 라벨로 지정되었다. label=’right’를 넘겨서 각 그룹의 오른쪽 값을 라벨로 사용할 수 있다.
ts.resample('5min', closed='right', label='right').sum()
2000-01-01 00:00:00 0 2000-01-01 00:05:00 15 2000-01-01 00:10:00 40 2000-01-01 00:15:00 11 Freq: 5T, dtype: int32
[그림 11-3]에 5분 단위 리샘플링에서의 closed와 label을 나타냈다.
그림 11-3 5분 단위 리샘플링에서의 closed와 label
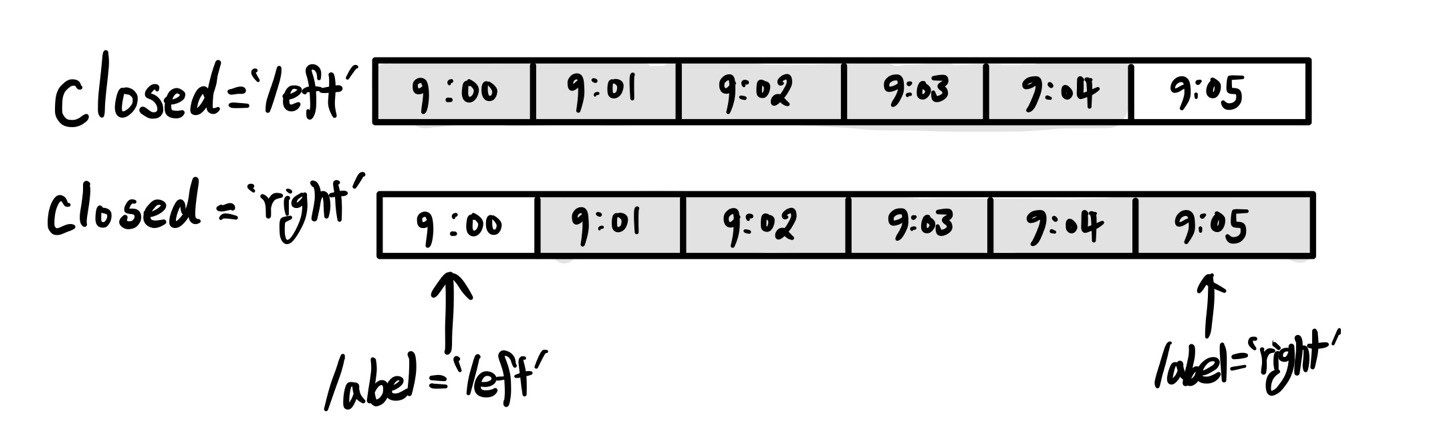
반환된 결과의 색인을 특정 크기만큼 이동시키고 싶은 경우, 즉 그룹의 오른쪽 끝에서 1초를 빼서 타임스탬프가 참조하는 간격을 좀 더 명확히 보여주고 싶은 경우에는 loffset 인자에 문자열이나 날짜 오프셋을 넘기면 된다.
ts.resample('5min', closed='right',
label='right', loffset='-1s').sum()
1999-12-31 23:59:59 0 2000-01-01 00:04:59 15 2000-01-01 00:09:59 40 2000-01-01 00:14:59 11 Freq: 5T, dtype: int32
FutureWarning: ‘loffset’ in .resample() and in Grouper() is deprecated. 라는 문구가 뜨며 다음과 같은 사용을 권장한다.
from pandas.tseries.frequencies import to_offset
ts = ts.resample('5min', closed='right', label='right').sum()
ts.index = ts.index - to_offset('1s')
ts
1999-12-31 23:59:59 0 2000-01-01 00:04:59 15 2000-01-01 00:09:59 40 2000-01-01 00:14:59 11 Freq: 5T, dtype: int32
위와 같은 방법 대신 반환된 결과에 shift() 메서드를 사용해도 같은 결과를 얻을 수 있다.
OHLC 리샘플링
금융 분야에서 시계열 데이터를 집계하는 아주 흔한 방식은 각 버킷에 대해 4가지 값을 계산하는 것이다. 이 4가지 값은 시가open, 고가high, 저가low, 종가close이며, 이를 OHLCOpen-High-Low-Close라고 한다. ohlc() 메서드를 연결시켜 한 번에 이 값을 담고 있는 칼럼을 데이터프레임을 얻을 수 있다.
ts.resample('5min', closed='left').ohlc()
| open | high | low | close | |
|---|---|---|---|---|
| 2000-01-01 00:00:00 | 0 | 4 | 0 | 4 |
| 2000-01-01 00:05:00 | 5 | 9 | 5 | 9 |
| 2000-01-01 00:10:00 | 10 | 11 | 10 | 11 |
업샘플링과 보간
하위 빈도에서 상위 빈도로 변환할 때는 집계가 필요하지 않다. 주간 데이터를 담고 있는 데이터프레임을 살펴보자.
frame = pd.DataFrame(np.random.randn(2, 4),
index=pd.date_range('1/1/2000', periods=2,
freq='W-WED'),
columns=['Colorado', 'Texas', 'New York', 'Ohio'])
frame
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-12 | 0.739624 | 0.447530 | -1.750723 | -1.453846 |
이 데이터에 요약함수를 사용하면 그룹당 하나의 값이 들어가고 그 사이에 결측치가 들어간다. asfreq() 메서드를 이용해서 어떤 요약함수도 사용하지 않고 상위 빈도로 리샘플링해보자.
df_daily = frame.resample('D').asfreq()
df_daily
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-06 | NaN | NaN | NaN | NaN |
| 2000-01-07 | NaN | NaN | NaN | NaN |
| 2000-01-08 | NaN | NaN | NaN | NaN |
| 2000-01-09 | NaN | NaN | NaN | NaN |
| 2000-01-10 | NaN | NaN | NaN | NaN |
| 2000-01-11 | NaN | NaN | NaN | NaN |
| 2000-01-12 | 0.739624 | 0.447530 | -1.750723 | -1.453846 |
수요일이 아닌 요일에는 이전 값을 채워서 보간을 수행한다고 가정하자. fillna()와 reindex() 메서드에서 사용했던 보간 메서드를 리샘플링에서도 사용할 수 있다.
frame.resample('D').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-06 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-07 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-08 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-09 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-10 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-11 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-12 | 0.739624 | 0.447530 | -1.750723 | -1.453846 |
limit 옵션을 사용해서 보간법을 적용할 범위를 지정하는 것도 가능하다.
frame.resample('D').ffill(limit=2)
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-06 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-07 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-08 | NaN | NaN | NaN | NaN |
| 2000-01-09 | NaN | NaN | NaN | NaN |
| 2000-01-10 | NaN | NaN | NaN | NaN |
| 2000-01-11 | NaN | NaN | NaN | NaN |
| 2000-01-12 | 0.739624 | 0.447530 | -1.750723 | -1.453846 |
특히 새로운 날짜 색인은 이전 색인과 겹쳐질 필요가 전혀 없다.
frame.resample('W-THU').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-06 | 0.442902 | 1.142569 | 1.106849 | -0.281654 |
| 2000-01-13 | 0.739624 | 0.447530 | -1.750723 | -1.453846 |
기간 리샘플링
기간으로 색인된 데이터를 리샘플링하는 것은 타임스탬프와 유사하다.
frame = pd.DataFrame(np.random.randn(24, 4),
index=pd.period_range('1-2000', '12-2001',
freq='M'),
columns=['Colorado', 'Texas', 'New York', 'Ohio'])
frame
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01 | 1.560593 | 1.350195 | 0.793259 | -0.037263 |
| 2000-02 | 0.756454 | 0.464837 | 0.324312 | 0.222193 |
| 2000-03 | 0.335737 | 1.474699 | 0.693999 | -1.598208 |
| 2000-04 | -0.757250 | -1.184031 | 1.097518 | 0.832201 |
| 2000-05 | 1.530382 | 0.913647 | -1.509024 | 1.194440 |
| 2000-06 | 0.645456 | 1.034514 | -1.108553 | 0.664971 |
| 2000-07 | 0.718452 | -0.494703 | 2.220494 | 0.779032 |
| 2000-08 | 0.725474 | 2.139603 | -2.120084 | 0.588880 |
| 2000-09 | 1.243350 | -0.908859 | -0.475647 | -1.902324 |
| 2000-10 | -0.023815 | -0.221807 | 0.112725 | -0.876975 |
| 2000-11 | 1.132961 | 0.461963 | 0.136545 | 1.049559 |
| 2000-12 | -0.205938 | 0.231215 | -1.214510 | -0.121774 |
| 2001-01 | 0.667848 | -0.009900 | 0.842360 | -1.759359 |
| 2001-02 | 1.082752 | 0.397899 | 0.762081 | -1.437118 |
| 2001-03 | -0.523072 | 0.525803 | 0.354609 | 1.776713 |
| 2001-04 | 0.216251 | 0.444622 | -1.147170 | 1.563442 |
| 2001-05 | -0.096016 | -1.929245 | 0.587491 | 0.812730 |
| 2001-06 | -0.074357 | 1.492241 | -0.376138 | -0.318051 |
| 2001-07 | 0.409191 | 1.111250 | 0.698586 | -0.232634 |
| 2001-08 | 0.933632 | 0.062927 | 0.883835 | -1.769893 |
| 2001-09 | -1.111891 | -0.304465 | 0.529908 | -0.808139 |
| 2001-10 | -0.215561 | 0.770460 | 1.188385 | 0.697848 |
| 2001-11 | -1.435318 | 0.107059 | 0.823174 | 1.078366 |
| 2001-12 | 0.740717 | 0.611684 | -0.862015 | -1.411144 |
for t, v in frame.resample('A-DEC'):
display(t, v)
Period('2000', 'A-DEC')
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01 | 1.560593 | 1.350195 | 0.793259 | -0.037263 |
| 2000-02 | 0.756454 | 0.464837 | 0.324312 | 0.222193 |
| 2000-03 | 0.335737 | 1.474699 | 0.693999 | -1.598208 |
| 2000-04 | -0.757250 | -1.184031 | 1.097518 | 0.832201 |
| 2000-05 | 1.530382 | 0.913647 | -1.509024 | 1.194440 |
| 2000-06 | 0.645456 | 1.034514 | -1.108553 | 0.664971 |
| 2000-07 | 0.718452 | -0.494703 | 2.220494 | 0.779032 |
| 2000-08 | 0.725474 | 2.139603 | -2.120084 | 0.588880 |
| 2000-09 | 1.243350 | -0.908859 | -0.475647 | -1.902324 |
| 2000-10 | -0.023815 | -0.221807 | 0.112725 | -0.876975 |
| 2000-11 | 1.132961 | 0.461963 | 0.136545 | 1.049559 |
| 2000-12 | -0.205938 | 0.231215 | -1.214510 | -0.121774 |
Period('2001', 'A-DEC')
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2001-01 | 0.667848 | -0.009900 | 0.842360 | -1.759359 |
| 2001-02 | 1.082752 | 0.397899 | 0.762081 | -1.437118 |
| 2001-03 | -0.523072 | 0.525803 | 0.354609 | 1.776713 |
| 2001-04 | 0.216251 | 0.444622 | -1.147170 | 1.563442 |
| 2001-05 | -0.096016 | -1.929245 | 0.587491 | 0.812730 |
| 2001-06 | -0.074357 | 1.492241 | -0.376138 | -0.318051 |
| 2001-07 | 0.409191 | 1.111250 | 0.698586 | -0.232634 |
| 2001-08 | 0.933632 | 0.062927 | 0.883835 | -1.769893 |
| 2001-09 | -1.111891 | -0.304465 | 0.529908 | -0.808139 |
| 2001-10 | -0.215561 | 0.770460 | 1.188385 | 0.697848 |
| 2001-11 | -1.435318 | 0.107059 | 0.823174 | 1.078366 |
| 2001-12 | 0.740717 | 0.611684 | -0.862015 | -1.411144 |
annual_frame = frame.resample('A-DEC').mean()
annual_frame
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
업샘플링은 resample() 메서드처럼 리샘플링하기 전에 새로운 빈도에서 구간의 끝을 어느 쪽에 두어야 할지 미리 결정해야 한다. convention 인자의 기본값은 ‘start’지만 ‘end’로 지정할 수도 있다.
# Q-DEC: 12월을 연도마감으로 하는 분기 주기
annual_frame.resample('Q-DEC').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q1 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2000Q2 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2000Q3 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2000Q4 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001Q1 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
| 2001Q2 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
| 2001Q3 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
| 2001Q4 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
# Q-DEC: 12월을 연도마감으로 하는 분기 주기
annual_frame.resample('Q-DEC', convention='end').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q4 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001Q1 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001Q2 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001Q3 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001Q4 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
기간의 업샘플링과 다운샘플링은 좀 더 엄격하다.
-
다운샘플링의 경우 대상 빈도는 반드시 원본 빈도의 하위 기간이어야 한다.
-
업샘플링의 경우 대상 빈도는 반드시 원본 빈도의 상위 기간이어야 한다.
위 조건을 만족하지 않으면 예외가 발생한다. 이 예외는 주로 분기, 연간, 주간 빈도에서 발생하는데, 예를 들어 Q-MAR로 정의된 기간은 A-MAR, A-JUN, A-SEP, A-DEC로만 이루어져 있다.
annual_frame.resample('Q-MAR').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q4 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001Q1 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001Q2 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001Q3 | 0.638488 | 0.438439 | -0.087414 | 0.066228 |
| 2001Q4 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
| 2002Q1 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
| 2002Q2 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
| 2002Q3 | 0.049515 | 0.273361 | 0.357092 | -0.150603 |
이동창 함수
시계열 연산에서 사용되는 배열 변형에서 중요한 요소는 움직이는 창 또는 지수 가중과 함께 수행되는 통계와 여타 함수들이다. 이런 함수를 이용해서 누락된 데이터로 인해 매끄럽지 않은 시계열 데이터를 매끄럽게 다듬을 수 있다. 지수 가중 이동평균처럼 고정 크기의 창을 가지지 않는 함수도 포함해서 이동창 함수moving window function라고 부른다. 다른 통계 함수와 마찬가지로 이동창 함수도 누락된 데이터를 자동으로 배제한다.
우선 시계열 데이터를 불러와서 영업일 빈도로 리샘플링하자.
close_px_all = pd.read_csv('examples/stock_px_2.csv',
parse_dates=True, index_col=0)
close_px = close_px_all[['AAPL', 'MSFT', 'XOM']]
close_px = close_px.resample('B').ffill()
이제 resample()이나 groupby()와 유사하게 작동하는 rolling() 연산을 알아보자. 이는 시리즈나 데이터프레임에 대해 원하는 기간을 나타내는 window 값과 함께 호출할 수 있다. 다음은 이 데이터를 시각화한 것이다.
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(1, 1, 1)
ax.plot(close_px.AAPL)
ax.plot(close_px.AAPL.rolling(250).mean())
plt.title('그림 11-4 애플 주가의 250일 이동평균', size=20, loc='left')
plt.show()

rolling(250) 이라는 표현은 groupby()와 비슷해 보이지만 그룹을 생성하는 대신 250일 크기의 움직이는 창을 통해 그룹핑할 수 있는 객체를 생성한다. [그림 11-5]는 250일 일별 수익 표준편차를 나타낸 그래프다.
rolling() 함수는 기본적으로 해당 윈도우 내에는 결측치가 없기를 기대하지만 시계열의 시작 지점에서는 필연적으로 window보다 적은 기간의 데이터를 가지고 있으므로 이를 처리하기 위해 rolling() 함수의 동작 방식은 변경될 수 있다.
aapl_std250 = close_px.AAPL.rolling(250, min_periods=10).std()
aapl_std250[5:12]
2003-01-09 NaN 2003-01-10 NaN 2003-01-13 NaN 2003-01-14 NaN 2003-01-15 0.077496 2003-01-16 0.074760 2003-01-17 0.112368 Freq: B, Name: AAPL, dtype: float64
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(1, 1, 1)
ax.plot(aapl_std250)
plt.title('그림 11-5 애플의 250일 일별 수익 표준편차', size=20, loc='left')
plt.show()

확장창 평균expanding window mean을 구하기 위해서는 rolling() 대신 expanding()을 사용한다. 확장창 평균은 시계열의 시작 지점에서부터 창의 크기가 시계열의 전체 크기가 될 때까지 점점 창의 크기를 늘린다. aapl_std250 시계열의 확장창 평균은 아래처럼 구할 수 있다.
expanding_mean = aapl_std250.expanding().mean()
데이터프레임에 대해 이동창 함수를 호출하면 각 칼럼에 적용된다(그림 11-6).
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(1, 1, 1)
ax.plot(close_px.rolling(60).mean())
ax.set_yscale('log')
plt.legend(close_px.columns, fontsize=15)
plt.title('그림 11-6 주가의 60일 이동평균(Y축 로그스케일)', size=20, loc='left')
plt.show()

rolling() 함수는 고정 크기의 기간 지정 문자열을 넘겨서 호출할 수도 있다. 빈도가 불규칙한 시계열일 경우 유용하게 사용할 수 있다. resample() 함수에서 사용하던 것과 같은 형식이다. 예를 들어 20일 크기의 이동평균은 아래처럼 구할 수 있다.
close_px.rolling('20D').mean()
| AAPL | MSFT | XOM | |
|---|---|---|---|
| 2003-01-02 | 7.400000 | 21.110000 | 29.220000 |
| 2003-01-03 | 7.425000 | 21.125000 | 29.230000 |
| 2003-01-06 | 7.433333 | 21.256667 | 29.473333 |
| 2003-01-07 | 7.432500 | 21.425000 | 29.342500 |
| 2003-01-08 | 7.402000 | 21.402000 | 29.240000 |
| ... | ... | ... | ... |
| 2011-10-10 | 389.351429 | 25.602143 | 72.527857 |
| 2011-10-11 | 388.505000 | 25.674286 | 72.835000 |
| 2011-10-12 | 388.531429 | 25.810000 | 73.400714 |
| 2011-10-13 | 388.826429 | 25.961429 | 73.905000 |
| 2011-10-14 | 391.038000 | 26.048667 | 74.185333 |
2292 rows × 3 columns
지수 가중 함수
균등한 가중치를 가지는 관찰과 함께 고정 크기 창을 사용하는 다른 방법은 감쇠인자decay factor 상수에 좀 더 많은 가중치를 줘서 더 최근 값을 관찰하는 것이다. 감쇠인자 상수를 지정하는 방법은 몇 가지 있는데 널리 쓰는 방법은 기간을 이용하는 것이다. 이 방법은 결과를 같은 기간의 창을 가지는 단순 이동창 함수와 비교 가능하도록 해준다.
지수 가중 통계는 최근 값에 좀 더 많은 가중치를 두는 방법이므로 균등 가중 방식에 비해 좀 더 빠르게 변화를 수용한다.
판다스는 rolling()이나 expanding()과 함께 사용할 수 있는 ewm 연산을 제공한다. 아래 예제는 애플 주가 60일 이동평균을 span=60으로 구한 지수 가중 이동평균과 비교한 것이다(그림 11-7).
aapl_px = close_px.AAPL['2006':'2007']
ma60 = aapl_px.rolling(60, min_periods=20).mean()
ewma60 = aapl_px.ewm(span=60).mean()
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(1, 1, 1)
ax.plot(ma60, 'k--', label='Simple MA')
ax.plot(ewma60, 'k-', label='EW MA')
plt.legend(fontsize=15)
plt.title('그림 11-7 간단한 이동평균과 지수 가중 이동평균', size=20, loc='left')
plt.show()

이진 이동창 함수
상관관계와 공분산 같은 몇몇 통계 연산은 두 개의 시계열을 필요로 한다. 예를 들어보자. 금융 분석가는 종종 S&P 500 같은 비교 대상이 되는 지수와 주식의 상관관계에 흥미를 가진다.
spx_px = close_px_all['SPX']
spx_rets = spx_px.pct_change()
returns = close_px.pct_change()
rolling() 함수에 이어 호출한 corr() 요약함수는 spx_rets와의 상관관계를 계산한다(그림 11-8).
corr = returns.AAPL.rolling(125, min_periods=100).corr(spx_rets)
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(1, 1, 1)
ax.plot(corr)
plt.title('그림 11-8 6개월간 S&P 500 지수와 APPL 수익 상관관계', size=20, loc='left')
plt.show()

여러 주식과 S&P 500 지수와의 상관관계를 한번에 계산하고 싶다고 가정하자. 반복문을 작성해서 새로운 데이터프레임을 생성하면 쉽겠지만 좋은 방법은 아니다. TimeSeries와 DataFrame 그리고 corr() 같은 함수를 넘겨서 TimeSeries(이 경우에는 spx_rets)와 DataFrame의 각 칼럼 간의 상관관계를 계산하면 된다. 결과는 [그림 11-9]에서 확인할 수 있다.
corr = returns.rolling(125, min_periods=100).corr(spx_rets)
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(1, 1, 1)
ax.plot(corr)
plt.legend(corr.columns, fontsize=15, loc='upper left')
plt.title('그림 11-9 6개월 수익과 S&P 500 지수의 상관관계', size=20, loc='left')
plt.show()

사용자 정의 이동창 함수
rolling()이나 다른 관련 메서드에 apply()를 호출해서 이동창에 대한 사용자 정의 연산을 수행할 수 있다. 유일한 요구 사항은 사용자 정의 함수가 배열의 각 조각으로부터 단일 값(감소)을 반환해야 한다는 것이다. 예를 들어 rolling(…).quantile(q)를 사용해서 표본 변위치를 계산할 수 있는 것처럼 전체 표본에서 특정 값이 차지하는 백분위 점수를 구하는 함수를 작성할 수도 있다. scipy.stats.percentilofscore() 함수가 그런 기능을 한다(그림 11-10).
from scipy.stats import percentileofscore
score_at_2percent = lambda x: percentileofscore(x, 0.02)
result = returns.AAPL.rolling(250).apply(score_at_2percent)
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(1, 1, 1)
ax.plot(result)
plt.title('그림 11-10 2%의 연간 APPL 수익률에 대한 백분위 점수', size=20, loc='left')
plt.show()

SciPy 패키지가 설치되어 있지 않다면 conda나 pip을 이용해서 설치하자.
댓글남기기