다양한 데이터 분석의 방법
텍스트 마이닝
대통령 연설문 텍스트 마이닝
문자로 된 데이터에서 가치 있는 정보를 얻어 내는 분석 기법을 텍스트 마이닝text mining이라고 한다. 텍스트 마이닝을 할 때 가장 먼저 하는 작업은 문장을 구성하는 어절들이 어떤 품사인지 파악하는 형태소 분석morphology analysis이다. 형태소 분석으로 어절의 품사를 파악한 다음 명사, 동사, 형용사 등 의미를 지닌 품사를 추출해 어떤 단어가 얼마나 많이 사용됐는지 확인한다. 텍스트 마이닝을 이용해 SNS나 웹 사이트에 올라온 글을 분석하면 사람들이 어떤 이야기를 나누고 있는지 파악할 수 있다.
윤석열 대통령의 출마 선언문을 이용해 텍스트 마이닝을 하는 방법을 알아보겠다. 대통령 연설문은 문법 오류가 없는 정제된 문장으로 되어 있어서 전처리 작업을 많이 하지 않아도 되므로 텍스트 마이닝을 익히는 데 매우 적합한 자료이다.
KoNLPy 패키지 설치하기
KoNLPy 패키지를 이용하면 한글 텍스트로 형태소 분석을 할 수 있다. KoNLPy 패키지를 설치하겠다.
1. 자바 설치하기
KoNLPy 패키지는 ‘자바’가 설치되어 있어야 사용할 수 있다. 사용하는 운영 체제에 맞는 서치 파일을 다운로드해 설치한다.
- [윈도우 설정 → 시스템 → 정보 → ‘장치 사양’의 ‘시스템 종류’]에서 운영 체제 버전을 확인한다.
확인 결과, 나는 “64비트 운영 체제, x64 기반 프로세서”로 확인됐다.
- 다음 사이트에 접속해 사용하는 운영 체제 버전에 맞는 설치 파일을 다운로드해 설치한다.
‘플랫폼’항목에 운영 체제 버전이 표시되어 있다. 64비트는 ‘Windows x64’, 32비트는 ‘Windows x86’의 msi 파일을 다운로드하면 된다.
2. KoNLPy 의존성 패키지 설치하기
어떤 패키지는 다른 패키지의 기능을 이용하기 때문에 다른 패키지를 먼저 설치해야 작동한다. 이처럼 패키지가 의존하고 있는 패키지를 ‘의존성 패키지’라고 한다. 아나콘다 프롬프트에서 KoNLPy의 의존성 패키지인 jpype1을 설치한다.
pip install jpype1
3. KoNLPy 설치하기
아나콘다 프롬프트에서 KoNLPy 패키지를 설치한다.
pip install konlpy
가장 많이 사용된 단어 알아보기
텍스트 마이닝을 할 준비를 모두 마쳤다. 이제 윤석열 대통령의 대선 출마 선언문을 이용해 텍스트 마이닝을 해보겠다.
1. 연설문 불러오기
윤석열 대통령 대선 출마 선언문이 담겨 있는 speech_moon.txt 파일을 워킹 디렉터리에 삽입한다. 그런 다음 open()으로 파일을 열고 read()를 이용해 불러온다. open()에 입력한 encoding=’UTF-8’은 불러올 텍스트 파일의 인코딩1을 ‘UTF-8’로 지정하는 기능을 한다.
yoon = open('speech_yoon.txt', encoding='UTF-8').read()
yoon
'존경하고 사랑하는 국민 여러분,\n750만 재외동포 여러분,\n그리고 자유를 사랑하는 세계 시민 여러분,\n\n저는 이 나라를 자유민주주의와 시장경제 체제를 기반으로 국민이 진정한 주인인 나라로 재건하고, 국제사회에서 책임과 역할을 다하는 나라로 만들어야 하는 시대적 소명을 갖고 오늘 이 자리에 섰습니다.\n\n역사적인 자리에 함께해 주신 국민 여러분께 감사드립니다.\n\n문재인, 박근혜 전 대통령, 그리고 할리마 야콥 싱가포르 대통령, 포스탱 아르샹쥬 투아데라 중앙아프리카공화국 대통령, 왕치산 중국 국가부주석, 메가와티 수카르노푸트리 인도네시아 전 대통령, 더글러스 엠호프 해리스 미국 부통령 부군, 조지 퓨리 캐나다 상원의장, 하야시 요시마사 일본 외무상을 비롯한 세계 각국의 경축 사절과 내외 귀빈 여러분께도 깊이 감사드립니다.\n\n이 자리를 빌려 지난 2년간 코로나 팬데믹을 극복하는 과정에서 큰 고통을 감내해주신 국민 여러분께 경의를 표합니다.\n그리고 헌신해주신 의료진 여러분께도 감사드립니다.\n\n존경하는 국민 여러분,\n세계 시민 여러분,\n\n지금 전 세계는 팬데믹 위기, 교역 질서의 변화와 공급망의 재편, 기후 변화, 식량과 에너지 위기, 분쟁의 평화적 해결의 후퇴 등 어느 한 나라가 독자적으로,\xa0 또는 몇몇 나라만 참여해서 해결하기 어려운 난제들에 직면해 있습니다.\n\n다양한 위기가 복합적으로 인류 사회에 어두운 그림자를 드리우고 있는 것입니다.\n\n또한 우리나라를 비롯한 많은 나라들이 국내적으로 초저성장과 대규모 실업, 양극화의 심화와 다양한 사회적 갈등으로 인해 공동체의 결속력이 흔들리고 와해되고 있습니다.\n\n한편, 이러한 문제들을 해결해야 하는 정치는 이른바 민주주의의 위기로 인해 제 기능을 하지 못하고 있습니다.\n\n가장 큰 원인으로 지목되는 것이 바로 반지성주의입니다.\n\n견해가 다른 사람들이 서로의 입장을 조정하고 타협하기 위해서는 과학과 진실이 전제되어야 합니다.\n그것이 민주주의를 지탱하는 합리주의와 지성주의입니다.\n\n국가 간, 국가 내부의 지나친 집단적 갈등에 의해 진실이 왜곡되고, 각자가 보고 듣고 싶은 사실만을 선택하거나 다수의 힘으로 상대의 의견을 억압하는 반지성주의가 민주주의를 위기에 빠뜨리고 민주주의에 대한 믿음을 해치고 있습니다.\n이러한 상황이 우리가 처해있는 문제의 해결을 더 어렵게 만들고 있습니다.\n\n그러나 우리는 할 수 있습니다.\n역사를 돌이켜 보면 우리 국민은 많은 위기에 처했지만 그럴 때마다 국민 모두 힘을 합쳐 지혜롭게, 또 용기있게 극복해 왔습니다.\n\n저는 이 순간 이러한 위기를 극복하는 책임을 부여받게 된 것을 감사한 마음으로 받아들이고, 우리 위대한 국민과 함께 당당하게 헤쳐 나갈 수 있다고 확신합니다.\n\n또 세계 시민과 힘을 합쳐 국내외적인 위기와 난제들을 해결해 나갈 수 있다고 믿습니다.\n\n존경하는 국민 여러분,\n세계 시민 여러분,\n\n저는 이 어려움을 해결해 나가기 위해서 우리가 보편적 가치를 공유하는 것이 매우 중요하다고 생각합니다.\n\n그것은 바로 ‘자유’입니다.\n우리는 자유의 가치를 제대로, 그리고 정확하게 인식해야 합니다.\n자유의 가치를 재발견해야 합니다.\n\n인류 역사를 돌이켜보면 자유로운 정치적 권리, 자유로운 시장이 숨 쉬고 있던 곳은 언제나 번영과 풍요가 꽃 피었습니다.\n\n번영과 풍요, 경제적 성장은 바로 자유의 확대입니다.\n\n자유는 보편적 가치입니다.\n우리 사회 모든 구성원이 자유 시민이 되어야 하는 것입니다.\n어떤 개인의 자유가 침해되는 것이 방치된다면 우리 공동체 구성원 모두의 자유마저 위협받게 됩니다.\n\n자유는 결코 승자독식이 아닙니다.\n자유 시민이 되기 위해서는 일정한 수준의 경제적 기초, 그리고 공정한 교육과 문화의 접근 기회가 보장되어야 합니다.\n이런 것 없이 자유 시민이라고 할 수 없습니다.\n\n어떤 사람의 자유가 유린되거나 자유 시민이 되는데 필요한 조건을 충족하지 못한다면 모든 자유 시민은 연대해서 도와야 합니다.\n\n그리고 개별 국가뿐 아니라 국제적으로도 기아와 빈곤, 공권력과 군사력에 의한 불법 행위로 개인의 자유가 침해되고 자유 시민으로서의 존엄한 삶이 유지되지 않는다면 모든 세계 시민이 자유 시민으로서 연대하여 도와야 하는 것입니다.\n\n모두가 자유 시민이 되기 위해서는 공정한 규칙을 지켜야 하고, 연대와 박애의 정신을 가져야 합니다.\n\n존경하는 국민 여러분,\n\n국내 문제로 눈을 돌려 제가 중요하게 생각하는 방향에 대해 말씀드리겠습니다.\n\n우리나라는 지나친 양극화와 사회 갈등이 자유와 민주주의를 위협할 뿐 아니라 사회 발전의 발목을 잡고 있습니다.\n\n저는 이 문제를 도약과 빠른 성장을 이룩하지 않고는 해결하기 어렵다고 생각합니다.\n\n빠른 성장 과정에서 많은 국민이 새로운 기회를 찾을 수 있고, 사회 이동성을 제고함으로써 양극화와 갈등의 근원을 제거할 수 있습니다.\n\n도약과 빠른 성장은 오로지 과학과 기술, 그리고 혁신에 의해서만 이뤄낼 수 있는 것입니다.\n\n과학과 기술, 그리고 혁신은 우리의 자유민주주의를 지키고 우리의 자유를 확대하며 우리의 존엄한 삶을 지속 가능하게 할 것입니다.\n\n과학과 기술, 그리고 혁신은 우리나라 혼자만의 노력으로는 달성하기 어렵습니다.\n\n자유와 창의를 존중함으로써 과학 기술의 진보와 혁신을 이뤄낸 많은 나라들과 협력하고 연대해야만 합니다.\n\n존경하는 국민 여러분,\n세계 시민 여러분,\n\n자유민주주의는 평화를 만들어내고, 평화는 자유를 지켜줍니다.\n그리고 평화는 자유와 인권의 가치를 존중하는 국제사회와의 연대에 의해 보장이 됩니다.\n\n일시적으로 전쟁을 회피하는 취약한 평화가 아니라 자유와 번영을 꽃피우는 지속 가능한 평화를 추구해야 합니다.\n\n전 세계 어떤 곳도 자유와 평화에 대한 위협에서 자유롭지 못합니다.\n지금 한반도와 동북아의 평화도 마찬가지입니다.\n\n저는 한반도뿐 아니라 아시아와 세계의 평화를 위협하는 북한의 핵 개발에 대해서도 그 평화적 해결을 위해 대화의 문을 열어놓겠습니다.\n\n그리고 북한이 핵 개발을 중단하고 실질적인 비핵화로 전환한다면 국제사회와 협력하여 북한 경제와 북한 주민의 삶의 질을 획기적으로 개선할 수 있는 담대한 계획을 준비하겠습니다.\n\n북한의 비핵화는 한반도에 지속 가능한 평화를 가져올 뿐 아니라 아시아와 전 세계의 평화와 번영에도 크게 기여할 것입니다.\n\n사랑하고 존경하는 국민 여러분,\n\n지금 우리는 세계 10위권의 경제 대국 그룹에 들어가 있습니다.\n그러므로 우리는 자유와 인권의 가치에 기반한 보편적 국제 규범을 적극 지지하고 수호하는데 글로벌 리더 국가로서의 자세를 가져야 합니다.\n\n우리나라뿐 아니라 세계 시민 모두의 자유와 인권을 지키고 확대하는데 더욱 주도적인 역할을 해야 합니다.\n국제사회도 대한민국에 더욱 큰 역할을 기대하고 있음이 분명합니다.\n\n지금 우리나라는 국내 문제와 국제 문제를 분리할 수 없습니다.\n국제사회가 우리에게 기대하는 역할을 주도적으로 수행할 때 국내 문제도 올바른 해결 방향을\n찾을 수 있는 것입니다.\n\n저는 자유, 인권, 공정, 연대의 가치를 기반으로 국민이 진정한 주인인 나라, 국제사회에서 책임을 다하고 존경받는 나라를 위대한 국민 여러분과 함께 반드시 만들어 나가겠습니다.\n\n감사합니다.'
윤석열 대통령의 대선 출마 선언문 출처: https://www.korea.kr/archive/speechView.do?newsId=132034362
2. 불필요한 문자 제거하기
yoon을 출력한 결과를 보면 특수 문자, 한자, 공백 등이 포함되어 있다. 이런 요소는 분석 대상이 아니므로 제거해야 한다. 문자 처리 패키지인 re의 sub()을 이용해 한글이 아닌 모든 문자를 공백으로 바꾸자.
# 불필요한 문자 제거하기
import re
yoon = re.sub('[^가-힣]', ' ', yoon)
yoon
'존경하고 사랑하는 국민 여러분 만 재외동포 여러분 그리고 자유를 사랑하는 세계 시민 여러분 저는 이 나라를 자유민주주의와 시장경제 체제를 기반으로 국민이 진정한 주인인 나라로 재건하고 국제사회에서 책임과 역할을 다하는 나라로 만들어야 하는 시대적 소명을 갖고 오늘 이 자리에 섰습니다 역사적인 자리에 함께해 주신 국민 여러분께 감사드립니다 문재인 박근혜 전 대통령 그리고 할리마 야콥 싱가포르 대통령 포스탱 아르샹쥬 투아데라 중앙아프리카공화국 대통령 왕치산 중국 국가부주석 메가와티 수카르노푸트리 인도네시아 전 대통령 더글러스 엠호프 해리스 미국 부통령 부군 조지 퓨리 캐나다 상원의장 하야시 요시마사 일본 외무상을 비롯한 세계 각국의 경축 사절과 내외 귀빈 여러분께도 깊이 감사드립니다 이 자리를 빌려 지난 년간 코로나 팬데믹을 극복하는 과정에서 큰 고통을 감내해주신 국민 여러분께 경의를 표합니다 그리고 헌신해주신 의료진 여러분께도 감사드립니다 존경하는 국민 여러분 세계 시민 여러분 지금 전 세계는 팬데믹 위기 교역 질서의 변화와 공급망의 재편 기후 변화 식량과 에너지 위기 분쟁의 평화적 해결의 후퇴 등 어느 한 나라가 독자적으로 또는 몇몇 나라만 참여해서 해결하기 어려운 난제들에 직면해 있습니다 다양한 위기가 복합적으로 인류 사회에 어두운 그림자를 드리우고 있는 것입니다 또한 우리나라를 비롯한 많은 나라들이 국내적으로 초저성장과 대규모 실업 양극화의 심화와 다양한 사회적 갈등으로 인해 공동체의 결속력이 흔들리고 와해되고 있습니다 한편 이러한 문제들을 해결해야 하는 정치는 이른바 민주주의의 위기로 인해 제 기능을 하지 못하고 있습니다 가장 큰 원인으로 지목되는 것이 바로 반지성주의입니다 견해가 다른 사람들이 서로의 입장을 조정하고 타협하기 위해서는 과학과 진실이 전제되어야 합니다 그것이 민주주의를 지탱하는 합리주의와 지성주의입니다 국가 간 국가 내부의 지나친 집단적 갈등에 의해 진실이 왜곡되고 각자가 보고 듣고 싶은 사실만을 선택하거나 다수의 힘으로 상대의 의견을 억압하는 반지성주의가 민주주의를 위기에 빠뜨리고 민주주의에 대한 믿음을 해치고 있습니다 이러한 상황이 우리가 처해있는 문제의 해결을 더 어렵게 만들고 있습니다 그러나 우리는 할 수 있습니다 역사를 돌이켜 보면 우리 국민은 많은 위기에 처했지만 그럴 때마다 국민 모두 힘을 합쳐 지혜롭게 또 용기있게 극복해 왔습니다 저는 이 순간 이러한 위기를 극복하는 책임을 부여받게 된 것을 감사한 마음으로 받아들이고 우리 위대한 국민과 함께 당당하게 헤쳐 나갈 수 있다고 확신합니다 또 세계 시민과 힘을 합쳐 국내외적인 위기와 난제들을 해결해 나갈 수 있다고 믿습니다 존경하는 국민 여러분 세계 시민 여러분 저는 이 어려움을 해결해 나가기 위해서 우리가 보편적 가치를 공유하는 것이 매우 중요하다고 생각합니다 그것은 바로 자유 입니다 우리는 자유의 가치를 제대로 그리고 정확하게 인식해야 합니다 자유의 가치를 재발견해야 합니다 인류 역사를 돌이켜보면 자유로운 정치적 권리 자유로운 시장이 숨 쉬고 있던 곳은 언제나 번영과 풍요가 꽃 피었습니다 번영과 풍요 경제적 성장은 바로 자유의 확대입니다 자유는 보편적 가치입니다 우리 사회 모든 구성원이 자유 시민이 되어야 하는 것입니다 어떤 개인의 자유가 침해되는 것이 방치된다면 우리 공동체 구성원 모두의 자유마저 위협받게 됩니다 자유는 결코 승자독식이 아닙니다 자유 시민이 되기 위해서는 일정한 수준의 경제적 기초 그리고 공정한 교육과 문화의 접근 기회가 보장되어야 합니다 이런 것 없이 자유 시민이라고 할 수 없습니다 어떤 사람의 자유가 유린되거나 자유 시민이 되는데 필요한 조건을 충족하지 못한다면 모든 자유 시민은 연대해서 도와야 합니다 그리고 개별 국가뿐 아니라 국제적으로도 기아와 빈곤 공권력과 군사력에 의한 불법 행위로 개인의 자유가 침해되고 자유 시민으로서의 존엄한 삶이 유지되지 않는다면 모든 세계 시민이 자유 시민으로서 연대하여 도와야 하는 것입니다 모두가 자유 시민이 되기 위해서는 공정한 규칙을 지켜야 하고 연대와 박애의 정신을 가져야 합니다 존경하는 국민 여러분 국내 문제로 눈을 돌려 제가 중요하게 생각하는 방향에 대해 말씀드리겠습니다 우리나라는 지나친 양극화와 사회 갈등이 자유와 민주주의를 위협할 뿐 아니라 사회 발전의 발목을 잡고 있습니다 저는 이 문제를 도약과 빠른 성장을 이룩하지 않고는 해결하기 어렵다고 생각합니다 빠른 성장 과정에서 많은 국민이 새로운 기회를 찾을 수 있고 사회 이동성을 제고함으로써 양극화와 갈등의 근원을 제거할 수 있습니다 도약과 빠른 성장은 오로지 과학과 기술 그리고 혁신에 의해서만 이뤄낼 수 있는 것입니다 과학과 기술 그리고 혁신은 우리의 자유민주주의를 지키고 우리의 자유를 확대하며 우리의 존엄한 삶을 지속 가능하게 할 것입니다 과학과 기술 그리고 혁신은 우리나라 혼자만의 노력으로는 달성하기 어렵습니다 자유와 창의를 존중함으로써 과학 기술의 진보와 혁신을 이뤄낸 많은 나라들과 협력하고 연대해야만 합니다 존경하는 국민 여러분 세계 시민 여러분 자유민주주의는 평화를 만들어내고 평화는 자유를 지켜줍니다 그리고 평화는 자유와 인권의 가치를 존중하는 국제사회와의 연대에 의해 보장이 됩니다 일시적으로 전쟁을 회피하는 취약한 평화가 아니라 자유와 번영을 꽃피우는 지속 가능한 평화를 추구해야 합니다 전 세계 어떤 곳도 자유와 평화에 대한 위협에서 자유롭지 못합니다 지금 한반도와 동북아의 평화도 마찬가지입니다 저는 한반도뿐 아니라 아시아와 세계의 평화를 위협하는 북한의 핵 개발에 대해서도 그 평화적 해결을 위해 대화의 문을 열어놓겠습니다 그리고 북한이 핵 개발을 중단하고 실질적인 비핵화로 전환한다면 국제사회와 협력하여 북한 경제와 북한 주민의 삶의 질을 획기적으로 개선할 수 있는 담대한 계획을 준비하겠습니다 북한의 비핵화는 한반도에 지속 가능한 평화를 가져올 뿐 아니라 아시아와 전 세계의 평화와 번영에도 크게 기여할 것입니다 사랑하고 존경하는 국민 여러분 지금 우리는 세계 위권의 경제 대국 그룹에 들어가 있습니다 그러므로 우리는 자유와 인권의 가치에 기반한 보편적 국제 규범을 적극 지지하고 수호하는데 글로벌 리더 국가로서의 자세를 가져야 합니다 우리나라뿐 아니라 세계 시민 모두의 자유와 인권을 지키고 확대하는데 더욱 주도적인 역할을 해야 합니다 국제사회도 대한민국에 더욱 큰 역할을 기대하고 있음이 분명합니다 지금 우리나라는 국내 문제와 국제 문제를 분리할 수 없습니다 국제사회가 우리에게 기대하는 역할을 주도적으로 수행할 때 국내 문제도 올바른 해결 방향을 찾을 수 있는 것입니다 저는 자유 인권 공정 연대의 가치를 기반으로 국민이 진정한 주인인 나라 국제사회에서 책임을 다하고 존경받는 나라를 위대한 국민 여러분과 함께 반드시 만들어 나가겠습니다 감사합니다 '
re.sub()에 입력한 [^가-힣]은 ‘한글이 나닌 모든 문자’를 의미하는 정규 표현식(regular expression)이다. 정규 표현식은 특정한 규칙을 가진 문자열을 표현하는 언어이다. 이메일 주소, 전화번호처럼 특정한 규칙으로 되어 있는 문자를 찾거나 수정할 때 정규 표현식을 활용한다.
3. 명사 추출하기
형태소 중에도 명사를 보면 텍스트가 무엇에 관한 내용인지 파악할 수 있기 때문에 텍스트에서 명사만 추출해 분석할 때가 많다. konlpy.tag.Hannanum()의 nouns()를 이용하면 문장에서 명사를 추출할 수 있다.
# hannanum(한나눔) 만들기
import konlpy
hannanum = konlpy.tag.Hannanum()
# 명사 추출하기
hannanum.nouns("대한민국의 영토는 한반도와 그 부속도서로 한다")
['대한민국', '영토', '한반도', '부속도서']
연설문에서 명사를 추출하겠다. hannanum.nouns()의 출력 결과는 리스트 자료 구조이므로 다루기 쉽도록 데이터 프레임으로 변환하겠다.
# 연설문에서 명사 추출하기
nouns = hannanum.nouns(yoon)
nouns[:5]
['존경', '사랑', '국민', '여러분', '재외동포']
# 데이터 프레임으로 변환
import pandas as pd
df_word = pd.DataFrame({'word': nouns})
df_word
| word | |
|---|---|
| 0 | 존경 |
| 1 | 사랑 |
| 2 | 국민 |
| 3 | 여러분 |
| 4 | 재외동포 |
| ... | ... |
| 591 | 나라 |
| 592 | 위대한 |
| 593 | 국민 |
| 594 | 여러분 |
| 595 | 감사 |
596 rows × 1 columns
4. 단어 빈도표 만들기
단어 빈도표를 만들어 연설문에 어떤 단어를 많이 사용했는지 알아보겠다. 먼저 한 글자로 된 단어는 의미가 없는 경우가 많으므로 제거한다. pd.str.len()을 이용해 단어의 글자 수를 나타낸 변수를 추가한 다음 두 글자 이상인 단어만 추출하면 된다.
# 글자 수 추가
df_word['count'] = df_word['word'].str.len()
df_word
| word | count | |
|---|---|---|
| 0 | 존경 | 2 |
| 1 | 사랑 | 2 |
| 2 | 국민 | 2 |
| 3 | 여러분 | 3 |
| 4 | 재외동포 | 4 |
| ... | ... | ... |
| 591 | 나라 | 2 |
| 592 | 위대한 | 3 |
| 593 | 국민 | 2 |
| 594 | 여러분 | 3 |
| 595 | 감사 | 2 |
596 rows × 2 columns
# 두 글자 이상 단어만 남기기
df_word = df_word.query('count >= 2')
df_word.sort_values('count')
| word | count | |
|---|---|---|
| 0 | 존경 | 2 |
| 385 | 국민 | 2 |
| 384 | 과정 | 2 |
| 383 | 성장 | 2 |
| 382 | 생각 | 2 |
| ... | ... | ... |
| 440 | 자유민주주의 | 6 |
| 13 | 자유민주주의 | 6 |
| 407 | 자유민주주의 | 6 |
| 51 | 수카르노푸트리 | 7 |
| 45 | 중앙아프리카공화국 | 9 |
509 rows × 2 columns
단어의 사용 빈도를 구하고 빈도순으로 정렬하겠다. 출력 결과를 보면 연설문에 ‘자유’, ‘여러분’, ‘국민’, ‘시민’ 등의 단어를 많이 사용했다는 것을 알 수 있다.
# 단어 빈도 구하기
df_word = df_word.groupby('word', as_index=False) \
.agg(n=('word', 'count')) \
.sort_values('n', ascending=False)
df_word
| word | n | |
|---|---|---|
| 180 | 자유 | 30 |
| 148 | 여러분 | 16 |
| 34 | 국민 | 15 |
| 132 | 시민 | 15 |
| 160 | 우리 | 14 |
| ... | ... | ... |
| 106 | 불법 | 1 |
| 109 | 빈곤 | 1 |
| 112 | 사실만 | 1 |
| 113 | 사절 | 1 |
| 253 | 후퇴 | 1 |
254 rows × 2 columns
5. 단어 빈도 막대 그래프 만들기
연설문에 어떤 단어를 많이 사용했는지 알아보기 쉽도록 자주 사용된 상위 20개 단어를 추출해 막대 그래프를 만들겠다.
# 단어 빈도 상위20개 추출
top20 = df_word.head(20)
top20
| word | n | |
|---|---|---|
| 180 | 자유 | 30 |
| 148 | 여러분 | 16 |
| 34 | 국민 | 15 |
| 132 | 시민 | 15 |
| 160 | 우리 | 14 |
| 123 | 세계 | 13 |
| 231 | 평화 | 10 |
| 242 | 해결 | 9 |
| 199 | 존경 | 7 |
| 1 | 가치 | 7 |
| 83 | 문제 | 6 |
| 36 | 국제사회 | 6 |
| 57 | 나라 | 5 |
| 25 | 과학 | 5 |
| 87 | 민주주의 | 5 |
| 102 | 북한 | 5 |
| 114 | 사회 | 5 |
| 161 | 우리나라 | 5 |
| 164 | 위협 | 4 |
| 246 | 혁신 | 4 |
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams.update({'font.family': 'Malgun Gothic', # 한글 폰트
'figure.dpi': '120', # 해상도
'figure.figsize': [6.5, 6]}) # 가로 세로 크기
# 막대 그래프 만들기
sns.barplot(data=top20, y='word', x='n');
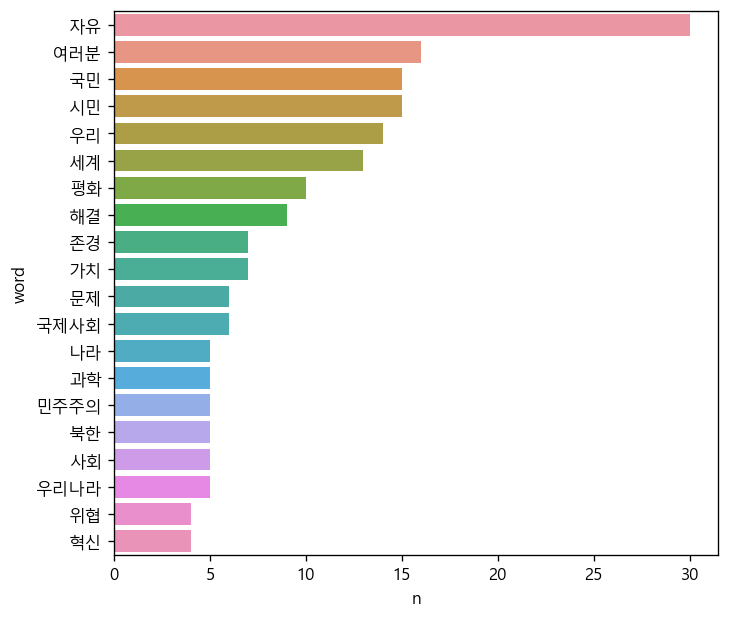
출력된 그래프를 보면 단어별 빈도가 잘 드러난다. ‘자유’, ‘국민’ 그리고’세계’ 등의 단어를 보면 윤석열 대통령이 연설에서 세계의 다양한 위협으로부터 국민의 자유를 위해 국가 안보에 힘을 쓰겠다는 의사를 표현했다는 것을 알 수 있다.
워드 클라우드 만들기
워드 클라우드word cloud는 단어의 빈도를 구름 모양으로 표현한 그래프이다. 워드 클라우드를 만들면 단어의 빈도에 따라 글자의 크기와 색깔이 다르게 표현되므로 어떤 단어가 얼마나 많이 사용됐는지 한눈에 파악할 수 있다. 연설문에 자주 사용된 단어로 워드 클라우드를 만들어 보자.
1. wordcloud 패키지 설치하기
아나콘다 프롬프트에서 wordcloud 패키지를 설치한다.
pip install wordcloud
2. 한글 폰트 설정하기
워드 클라우드에 한글을 표현하려면 워드 클라우드를 만들 때 한글 폰트를 사용하도록 설정해야 한다. 배달의민족 도현체 폰트 파일 DoHyeon-Regular.ttf를 워킹 디렉터리에 삽입한 다음 폰트 경로를 지정한다.
font = 'DoHyeon-Regular.ttf'
참고로, 윈도우에 설치된 다른 폰트를 이용해 워드 클라우드를 만들 수 있다. [윈도우 설정 → 개인 설정 → 글꼴]에서 글꼴을 선택하고, ‘메타데이터’의 ‘글꼴 파일’을 보면 .ttf 확장자의 폰트 파일 경로를 알 수 있다.
3. 단어와 빈도를 담은 딕셔너리 만들기
워드 클라우드는 단어는 키key, 빈도는 값values으로 구성된 딕셔너리 자료 구조를 이용해 만든다. 단어 빈도를 담은 df_word는 데이터 프레임이므로 다음 코드를 이용해 딕셔너리로 변환하자.
df_word
| word | n | |
|---|---|---|
| 180 | 자유 | 30 |
| 148 | 여러분 | 16 |
| 34 | 국민 | 15 |
| 132 | 시민 | 15 |
| 160 | 우리 | 14 |
| ... | ... | ... |
| 106 | 불법 | 1 |
| 109 | 빈곤 | 1 |
| 112 | 사실만 | 1 |
| 113 | 사절 | 1 |
| 253 | 후퇴 | 1 |
254 rows × 2 columns
# 데이터 프레임을 딕셔너리로 변환
dic_word = df_word.set_index('word').to_dict()['n']
dic_word
{'자유': 30,
'여러분': 16,
'국민': 15,
'시민': 15,
'우리': 14,
(...생략...)
4. 워드 클라우드 만들기
wordcloud 패키지의 WordCloud()를 이용해 워드 클라우드를 만들 때 사용할 wc를 만든다.
# wc 만들기
from wordcloud import WordCloud
wc = WordCloud(random_state=1234, # 난수 고정
font_path=font, # 폰트 설정
width=400, # 가로 크기
height=400, # 세로 크기
background_color='white') # 배경색
wc.generate_from_frequencies()를 이용해 워드 클라우드를 만든 다음 plt.show()를 이용해 출력한다. 워드 클라우드 이미지를 출력하는 코드는 한 셀에 넣어 함께 실행해야 하니 주의하자.
# 워드 클라우드 만들기
img_wordcloud = wc.generate_from_frequencies(dic_word)
# 워드 클라우드 출력하기
plt.figure(figsize=(10, 10)) # 가로, 세로 크기 설정
plt.axis('off') # 테두리 선 없애기
plt.imshow(img_wordcloud); # 워드 클라우드 출력

WordCloud()는 함수를 실행할 때마다 난수(무작위로 생성한 수)를 이용해 워드 클라우드를 매번 다른 모양으로 만든다. 워드 클라우드를 항상 같은 모양으로 만들려면 random_state를 이용해 난수를 고정해야 하고, wc를 만드는 코드를 먼저 실행한 다음 wc.generate_from_frequencies()를 실행해야 한다.
워드 클라우드는 자주 사용된 단어일수록 글자가 크게, 적게 사용된 단어일수록 글자가 작게 표현된다. 출력한 워드 클라우드를 보면 윤석열 대통령이 연설에서 무엇을 강조했는지 직관적으로 알 수 있다.
워드 클라우드 모양 바꾸기
WordCloud()의 mask를 이용하면 이미지 파일을 이용해 원하는 모양의 워드 클라우드를 만들 수 있다.
1. mask 만들기
cloud.png는 구름 모양 그림을 담고 있는 이미지 파일이다. 이 파일을 이용해 구름 모양으로 워드 클라우드를 만들어 보자.

mask에 사용할 이미지는 테두리가 뚜렷하고 어두운 색일수록 좋다.
cloud.png를 워킹 디렉터리에 삽입한 다음 PIL 패키지의 Image.open()를 이용해 불러온다.
import PIL
icon = PIL.Image.open('cloud.png')
다음 코드를 실행해 불러온 이미지 파일로 mask를 만든다.
import numpy as np
img = PIL.Image.new('RGB', icon.size, (255, 255, 255))
img.paste(icon, icon)
img = np.array(img)
2. 워드 클라우드 만들기
WordCloud()에 mask=img를 입력해 mask를 활용하도록 설정한다.
# wc 만들기
wc = WordCloud(random_state=1234, # 난수 고정
font_path=font, # 폰트 설정
width=400, # 가로 크기
height=400, # 세로 크기
background_color='white', # 배경색
mask=img) # mask 설정
이제 워드 클라우드를 만들면 구름 모양이 된다.
# 워드 클라우드 만들기
img_wordcloud = wc.generate_from_frequencies(dic_word)
# 워드 클라우드 출력하기
plt.figure(figsize=(10, 10)) # 가로, 세로 크기 설정
plt.axis('off') # 테두리 선 없애기
plt.imshow(img_wordcloud); # 워드 클라우드 출력

워드 클라우드 색깔 바꾸기
컬러맵(colormaps, 색깔 목록)을 이용하면 워드 클라우드의 색깔을 다양하게 바꿀 수 있다. WordCloud()에 colormap=’inferno’를 입력해 inferno 컬러맵을 적용하도록 설정하겠다.
# wc 만들기
wc = WordCloud(random_state=1234, # 난수 고정
font_path=font, # 폰트 설정
width=400, # 가로 크기
height=400, # 세로 크기
background_color='white', # 배경색
mask=img, # mask 설정
colormap='inferno') # 컬러맵 설정
이제 워드 클라우드를 만들면 색깔이 달라진다.
# 워드 클라우드 만들기
img_wordcloud = wc.generate_from_frequencies(dic_word)
# 워드 클라우드 출력하기
plt.figure(figsize=(10, 10)) # 가로, 세로 크기 설정
plt.axis('off') # 테두리 선 없애기
plt.imshow(img_wordcloud); # 워드 클라우드 출력

다양한 컬러맵 이용하기
그래프를 만들 때 다양한 컬러맵을 이용할 수 있다. 다음 사이트에서 어떤 컬러맵이 있는지 살펴보자.
- Choosing Colormaps in Matplotlib: bit.ly/easypy_104
워드 클라우드는 좋은 그래프인가?
워드 클라우드는 디자인이 아름다워서 자주 사용되지만 분석 결과를 정확하게 표현하는 그래프는 아니다. 단어 빈도를 크기와 색으로 표현하므로 ‘어떤 단어가 몇 번 사용됐는지’ 정확히 알 수 없고, 단어 배치가 산만해서 ‘어떤 단어가 다른 단어보다 얼마나 더 많이 사용됐는지’ 비교하기도 어렵다. 분석 결과를 아름답게 표현하는 게 아니라 정확하게 표현하려면 워드 클라우드보다 막대 그래프를 이용하는 게 좋다.
기사 댓글 텍스트 마이닝
텍스트 마이닝은 SNS에 올라온 글을 분석해 사람들이 어떤 생각을 하고 있는지 알아보는 목적으로 자주 활용한다. 이번에는 2020년 9월 21일 방탄소년단이 ‘빌보드 핫 100 차트’ 1위에 오른 소식을 다룬 네이버 뉴스 기사 댓글을 이용해 텍스트 마이닝을 해보자.
가장 많이 사용된 단어 알아보기
1. 기사 댓글 불러오기
news_comment_BTS.csv 파일을 워킹 디렉터리에 삽입한 다음 불러 온다.
# 데이터 불러오기
df = pd.read_csv('news_comment_BTS.csv', encoding='UTF-8')
# 데이터 살펴보기
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1200 entries, 0 to 1199
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 reg_time 1200 non-null object
1 reply 1200 non-null object
2 press 1200 non-null object
3 title 1200 non-null object
4 url 1200 non-null object
dtypes: object(5)
memory usage: 47.0+ KB
df.head()
| reg_time | reply | press | title | url | |
|---|---|---|---|---|---|
| 0 | 2020-09-01 22:58:09 | 국보소년단<U+0001F49C> | 한국경제 | [속보]BTS '다이너마이트', 한국 가수 최초로 빌보드 싱글 1위 | https://news.naver.com/main/read.nhn?mode=LSD&... |
| 1 | 2020-09-01 09:56:46 | 아줌마가 들어도 좋더라 | 한국경제 | [속보]BTS '다이너마이트', 한국 가수 최초로 빌보드 싱글 1위 | https://news.naver.com/main/read.nhn?mode=LSD&... |
| 2 | 2020-09-01 09:08:06 | 팩트체크\n\n현재 빌보드 HOT 100\n\n1위 방탄소년단[BTS]\n2위 C... | 한국경제 | [속보]BTS '다이너마이트', 한국 가수 최초로 빌보드 싱글 1위 | https://news.naver.com/main/read.nhn?mode=LSD&... |
| 3 | 2020-09-01 08:52:32 | 방탄소년단이 한국사람이라 너무 자랑스러워요 ㅠㅠ 우리오래오래 함께하자! | 한국경제 | [속보]BTS '다이너마이트', 한국 가수 최초로 빌보드 싱글 1위 | https://news.naver.com/main/read.nhn?mode=LSD&... |
| 4 | 2020-09-01 08:36:33 | 대단한 BTS, 월드 클래스는 다르네^^ 좋은 소식!! 응원해요 | 한국경제 | [속보]BTS '다이너마이트', 한국 가수 최초로 빌보드 싱글 1위 | https://news.naver.com/main/read.nhn?mode=LSD&... |
2. 불필요한 문자 제거하기
댓글이 들어 있는 reply 변수에서 불필요한 문자를 제거하고 한글만 남긴 다음 일부를 출력해 내용을 확인하자.
윗절에서 다룬 yoon은 txt 파일로 만든 str 타입 변수이므로 한글만 남기는 작업을 할 때 re.sub()을 사용했다. 여기서 분석하는 reply는 데이터프레임에 담겨 있는 변수이므로 str.replace()를 사용해야 한다.
# 불필요한 문자 제거하기
df['reply'] = df['reply'].str.replace('[^가-힣]', ' ', regex=True)
df['reply'].head()
0 국보소년단
1 아줌마가 들어도 좋더라
2 팩트체크 현재 빌보드 위 방탄소년단 위 ...
3 방탄소년단이 한국사람이라 너무 자랑스러워요 우리오래오래 함께하자
4 대단한 월드 클래스는 다르네 좋은 소식 응원해요
Name: reply, dtype: object
3. 명사 추출하기
이번에는 꼬꼬마(Kkma) 형태소 분석기를 이용해 댓글에서 명사를 추출해보자. 꼬꼬마 형태소 분석기는 띄어쓰기 오류가 있는 문장에서도 형태소를 잘 추출하는 장점이 있으므로 댓글처럼 정제되지 않은 텍스트를 분석할 때 적합하다.
# kkma 만들기
import konlpy
kkma = konlpy.tag.Kkma()
윗절에서 다룬 yoon은 문자 타입으로 된 하나의 변수였으므로 hannanum.nouns(yoon)처럼 함수에 바로 적용할 수 있었다. 반면 이번에 추출할 reply는 데이터프레임에 들어 있는 변수이므로 kkma.nouns()에 바로 적용할 수 없고, 대신 apply()를 사용해 함수가 각 행의 값을 따로따로 처리하도록 해야 한다.
# 명사 추출 - apply() 활용
nouns = df['reply'].apply(kkma.nouns)
nouns
0 [국보, 국보소년단, 소년단]
1 [아줌마]
2 [팩트, 팩트체크, 체크, 보드, 위, 방탄, 방탄소년단, 소년단]
3 [방탄, 방탄소년단, 소년단, 한국, 한국사람, 사람, 자랑, 우리, 하자]
4 [월드, 클래스, 소식, 응원]
...
1195 []
1196 [우리, 탄, 자랑, 사랑]
1197 [애, 군대]
1198 [군, 군면제급, 면제, 급]
1199 [자랑, 축하, 김, 김남, 남, 김석진, 민, 민윤기, 윤기, 정, 정호석, 호석...
Name: reply, Length: 1200, dtype: object
4. 단어 빈도표 만들기
단어가 몇 번씩 사용됐는지 나타낸 빈도료를 만들어보자. 앞에서 만든 nouns는 행마다 여러 단어가 리스트 자료 구조로 들어 있다. df.explode()를 이용해 한 행에 한 단어만 들어가도록 하자.
# 한 행에 한 단어가 들어가도록 구성
nouns = nouns.explode()
nouns
0 국보
0 국보소년단
0 소년단
1 아줌마
2 팩트
...
1199 박지민
1199 김태형
1199 전
1199 전정국
1199 정국
Name: reply, Length: 9353, dtype: object
nouns로 데이터프레임을 만든 다음 두 글자 이상으로 된 단어만 남기고 단어 빈도표를 만들자.
# 데이터프레임 만들기
df_word = pd.DataFrame({'word': nouns})
# 글자 수 추가
df_word['count'] = df_word['word'].str.len()
# 두 글자 이상 단어만 남기기
df_word = df_word.query('count >= 2')
df_word
| word | count | |
|---|---|---|
| 0 | 국보 | 2.0 |
| 0 | 국보소년단 | 5.0 |
| 0 | 소년단 | 3.0 |
| 1 | 아줌마 | 3.0 |
| 2 | 팩트 | 2.0 |
| ... | ... | ... |
| 1199 | 박지 | 2.0 |
| 1199 | 박지민 | 3.0 |
| 1199 | 김태형 | 3.0 |
| 1199 | 전정국 | 3.0 |
| 1199 | 정국 | 2.0 |
7002 rows × 2 columns
# 빈도표 만들기
df_word = df_word.groupby('word', as_index=False) \
.agg(n=('word', 'count')) \
.sort_values('n', ascending=False)
df_word
| word | n | |
|---|---|---|
| 752 | 방탄 | 280 |
| 1878 | 축하 | 236 |
| 1556 | 자랑 | 205 |
| 1032 | 소년단 | 144 |
| 763 | 방탄소년단 | 136 |
| ... | ... | ... |
| 1136 | 실력있음 | 1 |
| 406 | 다음주면 | 1 |
| 1134 | 신화 | 1 |
| 1133 | 신중 | 1 |
| 1084 | 스을적 | 1 |
2168 rows × 2 columns
5. 단어 빈도 막대 그래프 만들기
댓글에 어떤 단어가 많이 사용됐는지 알아보기 쉽도록 자주 사용된 상위 20개 단어를 추출해 막대 그래프를 만들어보자.
# 단어 빈도 상위 20개 추출
top20 = df_word.head(20)
top20
| word | n | |
|---|---|---|
| 752 | 방탄 | 280 |
| 1878 | 축하 | 236 |
| 1556 | 자랑 | 205 |
| 1032 | 소년단 | 144 |
| 763 | 방탄소년단 | 136 |
| 813 | 보드 | 131 |
| 618 | 면제 | 125 |
| 233 | 군면제 | 78 |
| 225 | 군대 | 77 |
| 1364 | 우리 | 68 |
| 11 | 가수 | 64 |
| 987 | 선양 | 62 |
| 215 | 국위선양 | 59 |
| 214 | 국위 | 58 |
| 328 | 나라 | 53 |
| 2038 | 한국 | 52 |
| 371 | 노래 | 50 |
| 463 | 대한민국 | 46 |
| 708 | 민국 | 46 |
| 462 | 대한 | 46 |
# 가로 세로 크기 설정
plt.rcParams.update({'font.family': 'Malgun Gothic', # 한글 폰트
'figure.dpi': '120', # 해상도
'figure.figsize': [6.5, 6]}) # 가로 세로 크기
# 막대 그래프 만들기
sns.barplot(data=top20, y='word', x='n');
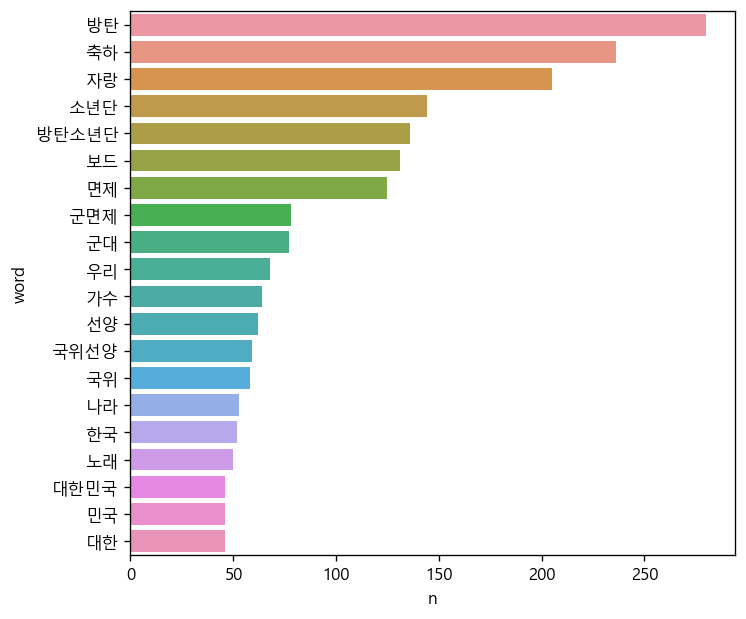
출력된 그래프를 보면 단어별 빈도가 잘 드러난다. ‘방탄’, ‘축하’, ‘자랑’, ‘국위선양’, ‘대한민국’ 등의 단어를 보면 BTS가 빌보드 차트 1위에 오른 일을 축하하고 대한민국을 세계에 알려 국위 선양을 했다고 칭찬하는 댓글이 많다는 것을 알 수 있다. 또한 ‘군대’, ‘면제’, ‘군면제’ 등의 단어를 보면 BTS의 병역 의무를 면제해 줘야 한다는 댓글도 많다는 것을 알 수 있다.
워드 클라우드 만들기
기사 댓글에 사용된 단어를 이용해 워드 클라우드를 만들어보자. 먼저 데이터프레임으로 되어 있는 df_word를 딕셔너리 자료 구조로 변환한다.
# 데이터프레임을 딕셔너리로 변환
dic_word = df_word.set_index('word').to_dict()['n']
dic_word
{'방탄': 280,
'축하': 236,
'자랑': 205,
'소년단': 144,
'방탄소년단': 136,
(...생략...)
wc를 만든 다음 wc.generate_from_frequencies()를 이용해 워드 클라우드를 만든다. 출력된 워드 클라우드를 보면 댓글의 전반적인 경향과 여론 분위기를 알 수 있다.
# wc 만들기
wc = WordCloud(random_state=1234, # 난수 고정
font_path=font, # 폰트 설정
width=400, # 가로 크기
height=400, # 세로 크기
background_color='white', # 배경색
mask=img) # mask 설정
# 워드 클라우드 만들기
img_wordcloud = wc.generate_from_frequencies(dic_word)
# 워드 클라우드 출력하기
plt.figure(figsize=(10, 10)) # 가로, 세로 크기 설정
plt.axis('off') # 테두리 선 없애기
plt.imshow(img_wordcloud); # 워드 클라우드 출력

텍스트 마이닝 더 알아보기
-
다양한 형태소 분석기 이용하기
KoNLPy를 이용하면 한나눔, 꼬꼬마 외에도 다양한 형태소 분석기를 이용할 수 있다. 또한 명사뿐 아니라 동사, 형용사 등 다양한 품사를 추출할 수 있으니 다음 KoNLPy 공식 문서를 참고하자.
-
텍스트 마이닝 자세히 익히기
텍스트 마이닝을 자세히 익히고 싶다면 《Do it! 쉽게 배우는 R 텍스트 마이닝》을 참고하자.
지도 시각화
시군구별 인구 단계 구분도 만들기
지역별 통계치를 색깔 차이로 표현한 지도를 단계 구분도choropleth map라고 한다. 단계 구분도를 만들면 인구나 소득 같은 통계치가 지역별로 어떻게 다른지 쉽게 이해할 수 있다. 시군구별 인구 데이터를 이용해 단계 구분도를 만들어보자.
시군구별 인구 단계 구분도 만들기
1. 시군구 경계 지도 데이터 준비하기
단계 구분도를 만들려면 지역별 위도, 경도 좌표가 있는 지도 데이터가 필요하다. 대한민국의 시군구별 경계 좌표가 들어 있는 SIG.geojson 파일을 불러오자. SIG.geojson은 행정 구역 코드, 지역 이름, 시군구 경계 위도와 경도 좌표를 담고 있는 GeoJSON2파일이다. json 패키지의 json.load()를 이용하면 GeoJSON 파일을 불러올 수 있다.
import json
geo = json.load(open('SIG.geojson.txt', encoding='UTF-8'))
json.load()로 GeoJSON 파일을 불러오려면 먼저 open()를 이용해 파일을 열어야 한다.
geo는 딕셔너리 자료 구조로 되어 있다. geo의 properties에 들어 있는 SIG_CD에 지역을 나타내는 행정 구역 코드가 담겨 있고, geometry에 시군구의 경계를 나타낸 위도, 경도 좌표가 담겨 있다.
# 행정 구역 코드 출력
geo['features'][0]['properties']
{'SIG_CD': '42110', 'SIG_ENG_NM': 'Chuncheon-si', 'SIG_KOR_NM': '춘천시'}
# 위도, 경도 좌표 출력
geo['features'][0]['geometry']
{'type': 'MultiPolygon',
'coordinates': [[[[127.58508551154958, 38.08062321552708],
[127.58565575732702, 38.0802009066172],
[127.58777905808203, 38.080354190085544],
[127.58890487394689, 38.080881783588694],
(...생략...)
2. 시군구별 인구 데이터 준비하기
지도에 표현할 시군구별 인구 통계 데이터가 담겨있는 Population_SIG.csv 파일을 불러오자. Population_SIG.csv3 파일은 2021년의 시군구별 행정 구역 코드, 지역 이름, 인구를 담고 있다.
참고로 통계 데이터에 행정 구역 코드가 들어 있어야 지도를 만드는 데 활용할 수 있다. KOSIS의 다운로드 화면에서 ‘파일 형태’의 ‘코드포함’을 체크하면 행정 구역 코드를 함께 다운로드한다.
import pandas as pd
df_pop = pd.read_csv('Population_SIG.csv')
df_pop.head()
| code | region | pop | |
|---|---|---|---|
| 0 | 11 | 서울특별시 | 9509458 |
| 1 | 11110 | 종로구 | 144683 |
| 2 | 11140 | 중구 | 122499 |
| 3 | 11170 | 용산구 | 222953 |
| 4 | 11200 | 성동구 | 285990 |
df_pop.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 278 entries, 0 to 277
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 code 278 non-null int64
1 region 278 non-null object
2 pop 278 non-null int64
dtypes: int64(2), object(1)
memory usage: 6.6+ KB
행정 구역 코드를 나타낸 df_pop의 code는 int64 타입으로 되어있다. 행정 구역 코드가 문자 타입으로 되어 있어야 지도를 만드는데 활용할 수 있다. df.astype()을 이용해 code를 문자 타입으로 바꾸자.
df_pop['code'] = df_pop['code'].astype(str)
3. 단계 구분도 만들기
folium 패키지를 이용하면 단계 구분도를 만들 수 있다. 아나콘다 프롬프트에서 folium 패키지를 설치한다.
pip install folium
(1) 배경 지도 만들기
folium.Map()을 이용해 배경 지도를 만든다. location에는 지도의 중심 위도, 경도 좌표를 입력하고, zoom_start에는 지도를 확대할 정도를 입력한다. folium으로 만든 지도는 마우스를 이용해 위치를 옮길 수 있고, 휠을 이용해 확대하거나 축소할 수 있다.
import folium
folium.Map(location=[35.95, 127.7], # 지도 중심 좌표
zoom_start=8) # 확대 단계
지도 크기는 모니터 크기와 해상도에 따라 달라진다. folium.Map()의 width와 height 인자를 이용해 지도 크기를 조절할 수 있다.
단계 구분도를 만드는 데 사용할 배경 지도를 만들어 저장하자. 지도 종류는 단계 구분도가 잘 표현되도록 밝은색으로 바꾸겠다. tiles에 ‘cartodbpositron’를 입력하면 된다.
map_sig = folium.Map(location=[35.95, 127.7], # 지도 중심 좌표
zoom_start=8, # 확대 단계
tiles='cartodbpositron') # 지도 종류
map_sig
(2) 단계 구분도 만들기
folium.Choropleth()를 이용해 시군구별 인구를 나타낸 단계 구분도를 만들자.
folium.Choropleth()에는 다음과 같은 파라미터를 입력한다.
- geo_data: 지도 데이터
- data: 색깔로 표현할 통계 데이터
- columns: 통계 데이터의 행정 구역 코드 변수, 색깔로 표현할 변수
- key_on: 지도 데이터의 행정 구역 코드
folium.Choropleth()에 .add_to(map_sig)를 추가하면 앞에서 만든 배경 지도 map_sig에 단계 구분도를 덧씌운다. map_sig를 실행하면 시군구 경계가 표시된 지도가 출력된다.
folium.Choropleth(
geo_data=geo,
data=df_pop,
columns=('code', 'pop'),
key_on='feature.properties.SIG_CD') \
.add_to(map_sig)
mpg_sig
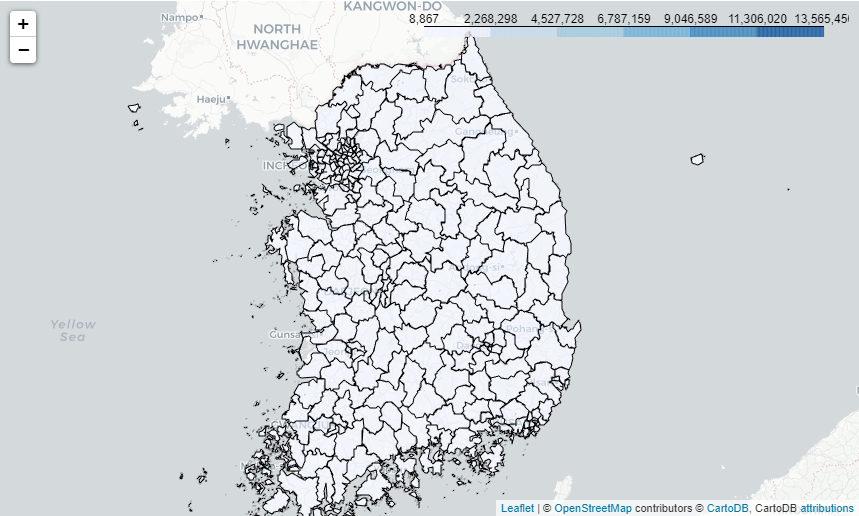
(3) 계급 구간 정하기
앞에서 출력한 지도는 지역이 색깔별로 표현되어 있지 않다. 지역을 단계별로 나눌 때 기준으로 삼은 ‘계급 구간’이 적당하지 않기 때문이다.
분위수를 이용해 지역을 적당히 나누는 계급 구간을 정하자. quantile()을 이용해 5가지 계급 구간의 하한값, 상한값을 담은 bins를 만든다. 이렇게 구한 값을 folium.Choropleth()의 bins에 입력하면 지역을 인구에 다라 다섯 단계의 색깔로 표현한다.
bins = list(df_pop["pop"].quantile([0, 0.2, 0.4, 0.6, 0.8, 1]))
bins
[8867.0, 50539.6, 142382.20000000004, 266978.6, 423107.20000000024, 13565450.0]
folium.Choropleth()는 통계치가 가장 작은 값부터 가장 큰 값까지 6개의 일정한 간격으로 계급 구간을 만들어 지역의 색깔을 정한다. 그런데 통계치가 극단적으로 큰 지역이 있으면 6개의 계급 구간으로 지역을 적절하게 구분하지 못하므로 모든 지역이 같은 색으로 표현된다. 앞에서 만든 지도는 ‘경기도’와 ‘서울 특별시’의 인구가 다른 지역에 비해 극단적으로 크기 때문에 모든 지역이 같은 색으로 표현된 것이다.
(4) 디자인 수정하기
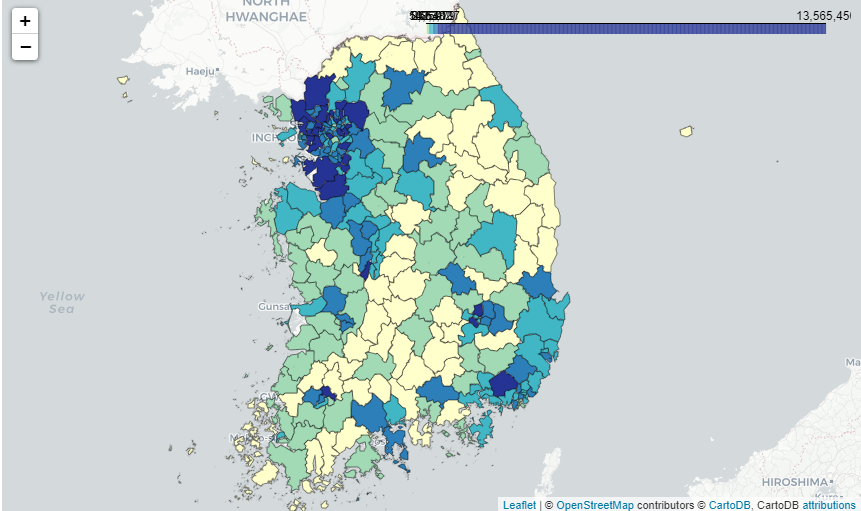
파라미터를 몇 가지 추가해 단계 구분도의 디자인을 보기 좋게 수정하자. 출력한 단계 구분도를 보면 인구가 많을수록 파란색, 적을수록 노란색에 가깝게 표현되어 시군구별 인구 차이를 한눈에 알 수 있다.
# 배경 지도 만들기
map_sig = folium.Map(location=[35.95, 127.7], # 지도 중심 좌표
zoom_start=8, # 확대 단계
tiles='cartodbpositron') # 지도 종류
map_sig
# 단계 구분도 만들기
folium.Choropleth(
geo_data=geo, # 지도 데이터
data=df_pop, # 통계 데이터
columns=('code', 'pop'), # df_pop 행정 구역 코드, 인구
key_on='feature.properties.SIG_CD', # geo 행정 구역 코드
fill_color='YlGnBu', # 컬러맵
fill_opacity=1, # 투명도
line_opacity=0.5, # 경계선 투명도
bins=bins) \ # 계급 구간 기준값
.add_to(map_sig) # 배경 지도에 추가
map_sig
서울시 동별 외국인 인구 단계 구분도 만들기
단계 구분도는 최적의 장소를 정하는 데 유용하게 활용할 수 있다. 만약 지자체가 외국인의 생활을 돕는 시설을 지을 장소를 정한다면, 지역별 외국인 인구를 나타낸 단계 구분도를 만들면 도움이 될 것이다. 이번에는 서울시의 동별 외국인 인구 데이터를 이용해 단계 구분도를 만들어보자.
서울시 동별 외국인 인구 단계 구분도 만들기
1. 서울시 동 경계 지도 데이터 준비하기
서울시의 동 경계 좌표가 들어 있는 EMD_Seoul.geosjon 파일을 불러온다. EMD_Seoul.geojson 파일은 서울시의 동별 행정 구역 코드, 동 이름, 동 경계 위도, 경도 좌표를 담고 있다.
import json
geo_seoul = json.load(open('EMD_Seoul.geojson.txt', encoding='UTF-8'))
geo_seoul의 properties에 들어 있는 ADM_DR_CD에 동을 나타내는 행정 구역 코드가 담겨 있고, geometry에 동별 경계를 나타낸 위도와 경도 좌표가 담겨 있다.
# 행정 구역 코드
geo_seoul['features'][0]['properties']
{'BASE_DATE': '20200630',
'ADM_DR_CD': '1101053',
'ADM_DR_NM': '사직동',
'OBJECTID': '1'}
# 위도, 경도 좌표 출력
geo_seoul['features'][0]['geometry']
{'type': 'MultiPolygon',
'coordinates': [[[[126.97398562200112, 37.578232670691676],
[126.97400165856983, 37.578091598158124],
[126.97401347517625, 37.57797124764524],
[126.97402588957173, 37.57786305895336],
(...생략...)
2. 서울시 동별 외국인 인구 데이터 준비하기
서울시 동별 외국인 인구 통계가 들어 있는 Foreigner_EMD_Seoul.csv 파일을 불러오자. Foreigner_EMD_Seoul.csv4 파일은 2021년 서울시의 동별 행정 구역 코드, 동 이름, 외국인 인구를 담고 있다.
foreigner = pd.read_csv('Foreigner_EMD_Seoul.csv')
foreigner.head()
| code | region | pop | |
|---|---|---|---|
| 0 | 1101053 | 사직동 | 418.0 |
| 1 | 1101054 | 삼청동 | 112.0 |
| 2 | 1101055 | 부암동 | 458.0 |
| 3 | 1101056 | 평창동 | 429.0 |
| 4 | 1101057 | 무악동 | 102.0 |
foreigner.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3490 entries, 0 to 3489
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 code 3490 non-null int64
1 region 3490 non-null object
2 pop 3486 non-null float64
dtypes: float64(1), int64(1), object(1)
memory usage: 81.9+ KB
행정 구역 코드를 나타낸 foreigner의 code는 int64 타입으로 되어 있다. 지도를 만드는 데 활용할 수 있도록 문자 타입으로 바꾸자.
foreigner['code'] = foreigner['code'].astype(str)
3. 단계 구분도 만들기
단계 구분도를 만들겠다. 우선 지역을 8단계로 나누도록 8개 계급 구간의 하한값, 상한값을 만들자.
bins = list(foreigner["pop"].quantile([0, 0.2, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]))
bins
[7.0, 98.0, 200.0, 280.0, 386.0, 529.5, 766.0, 1355.5, 26896.0]
서울이 가운데에 오도록 배경 지도를 만든 다음 단계 구분도를 추가한다. 인구가 많을수록 진한 파란색으로 표현하도록 fill_color=’Blues’를 입력하고, 외국인 이눅가 결측치인 지역은 흰색으로 표현하도록 nan_fill_color=’White’를 입력하자.
# 배경 지도 만들기
map_seoul = folium.Map(location=[37.56, 127], # 서울 좌표
zoom_start=12, # 확대 단계
tiles='cartodbpositron') # 지도 종류
# 단계구분도 만들기
folium.Choropleth(
geo_data=geo_seoul, # 지도 데이터
data=foreigner, # 통계 데이터
columns=('code', 'pop'), # foreigner 행정구역코드, 인구
key_on='feature.properties.ADM_DR_CD', # geo_seoul 행정구역코드
fill_color='Blues', # 컬러맵
nan_fill_color='White', # 결측치 색깔
fill_opacity=1, # 투명도
line_opacity=0.5, # 경계선 투명도
bins=bins) \ # 계급 구간 기준값
.add_to(map_seoul) # 배경 지도에 추가
map_seoul
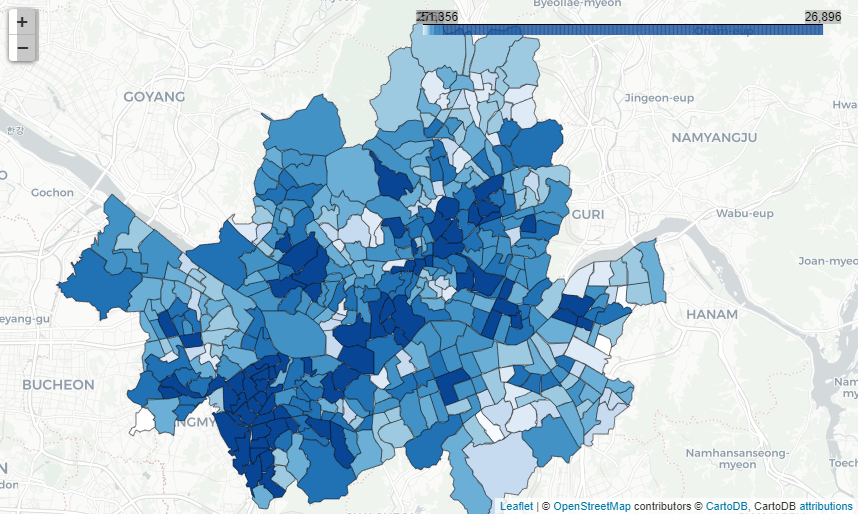
4. 구 경계선 추가하기
앞에서 만든 지도에 구 경계선을 추가한다. 먼저 서울시의 구 경계 좌표를 담은 SIG_Seoul.geojson 파일을 불러오자.
geo_seoul_sig = json.load(open('SIG_Seoul.geojson.txt', encoding='UTF-8'))
서울시의 구 경계선을 이용해 단계 구분도를 만든 다음 .add_to(map_seoul)를 이용해 앞에서 만든 지도에 추가하자. 색깔을 칠하지 않도록 fill_opacity=0을 입력하고, 구 경계선을 두껍게 나타내도록 line_width=4를 입력하자. 출력한 지도를 보면 외국인 인구가 많은 지역과 적은 지역을 쉽게 알아볼 수 있다.
# 서울 구 라인 추가
folium.Choropleth(geo_data=geo_seoul_sig, # 지도 데이터
fill_opacity=0, # 투명도
line_weight=4) \
.add_to(map_seoul) # 지도에 추가
map_seoul
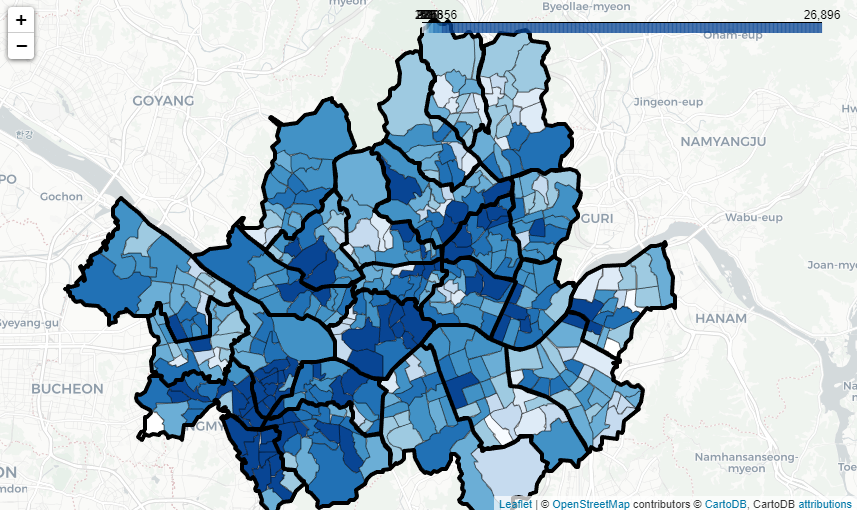
HTML 파일로 저장하기
save() 메서드를 이용하면 지도를 HTML 파일로 저장할 수 있다. HTML 파일은 파이썬과 JupyterLab이 설치되지 않은 곳에서도 웹 브라우저만 있으면 열어볼 수 있다.
map_seoul.save('map_seoul.html')
웹 브라우저에서 html 파일 열기
webbrowser 패키지의 open_new()를 이용하면 웹 브라우저에서 HTML 파일을 열 수 있다. 지도가 너무 커서 노트북에서 보기 어려울 때 HTML 파일로 저장한 다음 웹 브라우저에서 열면 편리하다.
import webbrowser
webbrowser.open_new('map_seoul.html')
다른 지도 만들기
folium 패키지를 이용하면 단계 구분도 외에 다른 종류의 지도를 만들 수 있고 디자인도 다양하게 수정할 수 있다. folium 공식 문서를 참고하자.
- folium 공식 문서: python-visualization.github.io/folium
-
인코딩encoding은 컴퓨터가 문자를 표현하는 방식을 의미한다. 문서 파일에 따라 인코딩 방식이 다르기 때문에 문서 파일과 프로그램의 인코딩이 맞지 않으면 문자가 깨지는 문제가 생긴다. ↩
-
GeoJSON은 위치 정보를 JSON 포맷으로 저장한 표준 지리 정보 데이터 포맷이다. 지리 정보 데이터를 다루는 대부분의 소프트웨어에서 GeoJSON 파일을 활용할 수 있다. 이 책에서 사용하는 GeoJSON 파일은 ‘(주)지오서비스’에서 공개한 SHP 파일을 오픈 소스 지리 정보 시스템 QGIS로 변환해 만들었다. 데이터 출처는 bit.ly/easypy_101이다. ↩
-
국가 통계포털 KOSIS의 ‘주민등록인구현황’ 데이터를 가공해 만들었으며 출처는 bit.ly/easypy_112이다. ↩
-
국가통계포털 KOSIS의 ‘지방자치단체외국인주민현황’ 데이터를 가공해 만들었으며 출처는 bit.ly/easypy_113이다. ↩
댓글남기기